Hadoop与大数据技术基石:HDFS、MapReduce与Hive、Pig详解
版权申诉
大数据入门是一份详细讲解大数据基础知识的教程,由CVJ提供,共22页。该文档首先介绍了Hadoop家族的起源,其创始人Doug Cutting对于大数据技术的发展有着重要贡献。Hadoop Common作为Hadoop体系的基础模块,为Hadoop的所有子项目提供了基础工具支持,比如配置文件管理和日志操作。
第3页重点讲解了Hadoop分布式文件系统(HDFS)。HDFS是一个关键组成部分,设计用于处理海量数据,它的主要特点是通过NameNode(主节点)来管理元数据,而DataNode(数据节点)则负责存储实际数据。HDFS的优势在于处理大文件而非小文件,它优化的是对大量大型文件的访问和存储。
第4页进一步阐述了MapReduce,这是一个强大的并行计算框架,使得编写处理TB级数据的应用程序变得更加容易。MapReduce是Hadoop的核心组件,它将数据分发到多台商用硬件组成的集群中,确保处理过程的可靠性和容错性,使得分布式计算编程在Hadoop平台上变得简单。
随后,文档转向了数据仓库系统的介绍。第5页提到Apache Hive,作为一个基于Hadoop的数据仓库,它提供SQL查询功能(HiveQL),支持ETL(提取、转换、加载)操作,并允许用户使用自定义Mapper和Reducer进行复杂的数据处理。Hive因其通用性和可扩展性而被广泛应用。
第6页介绍了Apache Pig,Pig是一个专门用于大规模数据集分析的平台,它使用 PigLatin语言,具有高度并行性和可扩展性。Pig的架构包括一个用于生成MapReduce任务的编译器,使得数据分析更加高效。
总结来说,这份教程涵盖了大数据领域的关键组件和技术,从Hadoop生态系统的基础(Hadoop Common、HDFS和MapReduce)到数据仓库(Hive)和数据处理平台(Pig),为初学者提供了全面的大数据入门知识。学习者可以通过这份教程深入了解如何在实际场景中利用Hadoop及其相关的工具进行数据处理和分析。
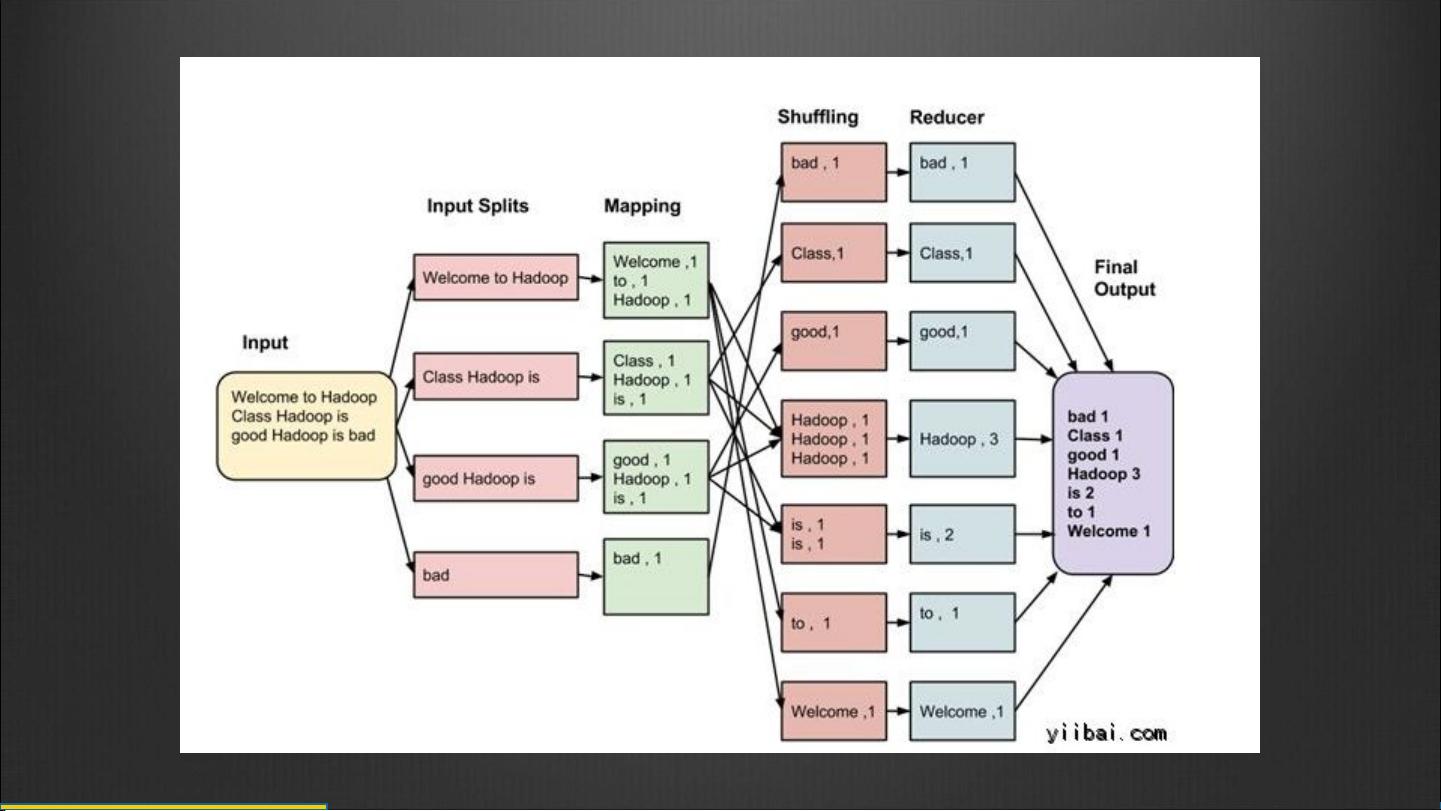
MapReduce
是一个软件框架,用以轻松编写处理海量( TB 级)数据的并
行应用程序,以可靠和容错的方式连接大型集群中上万个节点
(商用硬件)
MapReduce 是 hadoop 的核心组件之一, hadoop 要分布
式包括两部分,一是分布式文件系统 hdfs, 一部是分布式计算
框,就是 mapreduce, 缺一不可,也就是说,可以通过
mapreduce 很容易在 hadoop 平台上进行分布式的计算编程。
剩余21页未读,继续阅读
2021-12-18 上传
2023-03-24 上传
2021-09-05 上传
2021-09-23 上传
2021-12-28 上传
2021-10-19 上传
2023-10-15 上传
2021-06-05 上传
2021-06-05 上传









