Python爬虫详解:原理、流程及实战演示
需积分: 23 170 浏览量
更新于2024-08-04
收藏 853KB DOCX 举报
Python爬虫详解深入探讨
Python爬虫是一种利用编程技术从互联网上自动搜集数据的过程。它通过发送HTTP请求与服务器交互,获取并处理网页内容,进而抓取所需信息。在理解爬虫的工作原理和流程后,我们可以更好地编写相应的代码。
爬虫的原理主要分为以下几个步骤:
1. **目标设定**:首先确定要爬取的网页URL,这在代码中作为输入参数。
2. **发送HTTP请求**:爬虫模拟用户行为,使用如`requests`或`urllib`库在Python中发送GET或POST等请求方法,指定目标URL和协议版本(如HTTP/1.1)。
3. **解析请求头**:在请求中,可能包含用户代理(User-Agent)、认证信息等,用于识别爬虫的身份,有时需要伪装以避免被服务器拒绝。
4. **请求体**:对于POST请求,可能包含请求体,例如登录信息,但GET请求通常不携带请求体。
5. **接收服务器响应**:服务器接收到请求后,返回一个HTTP响应,包括状态码、响应头和响应体。
爬虫流程可以概括为:
1. **发起请求**:根据URL构建请求对象,设置请求方法和头信息。
2. **建立连接**:通过网络连接目标服务器。
3. **发送请求**:将请求对象发送至服务器,等待服务器响应。
4. **解析响应**:分析响应状态码,提取响应头信息,获取响应体(HTML源代码)。
5. **数据处理**:解析响应体中的HTML结构,提取所需数据。
6. **保存数据**:将抓取的数据存储在本地文件、数据库或进一步处理。
Python在爬虫领域因其丰富的库而备受欢迎,例如:
- `requests`:提供了简洁的API进行HTTP请求,支持GET、POST等方法。
- `BeautifulSoup`或`lxml`:用于解析HTML文档,提取数据。
- `Scrapy`:更高级的爬虫框架,提供了更强大的功能和可扩展性。
以下是一个简单的Python爬虫示例,使用`requests`库获取网页内容:
```python
import requests
def get_html(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
print(f"请求失败,状态码:{response.status_code}")
return None
url = "http://example.com/top250"
html_content = get_html(url)
if html_content:
soup = BeautifulSoup(html_content, 'html.parser')
# 解析并提取数据
movie_titles = soup.find_all('h3', class_='title')
for title in movie_titles:
print(title.text)
```
这个例子展示了基本的爬虫流程,即发送请求、解析响应,并从中提取信息。然而,实际爬虫项目可能涉及更复杂的网络逻辑、数据清洗、反爬虫策略以及数据存储等环节。在进行爬虫开发时,务必遵守网站的robots.txt规则,并尊重版权和隐私政策。
爬虫是什么
爬虫简单的来说就是用程序获取网络上数据这个过程的一种名称。
爬虫的原理
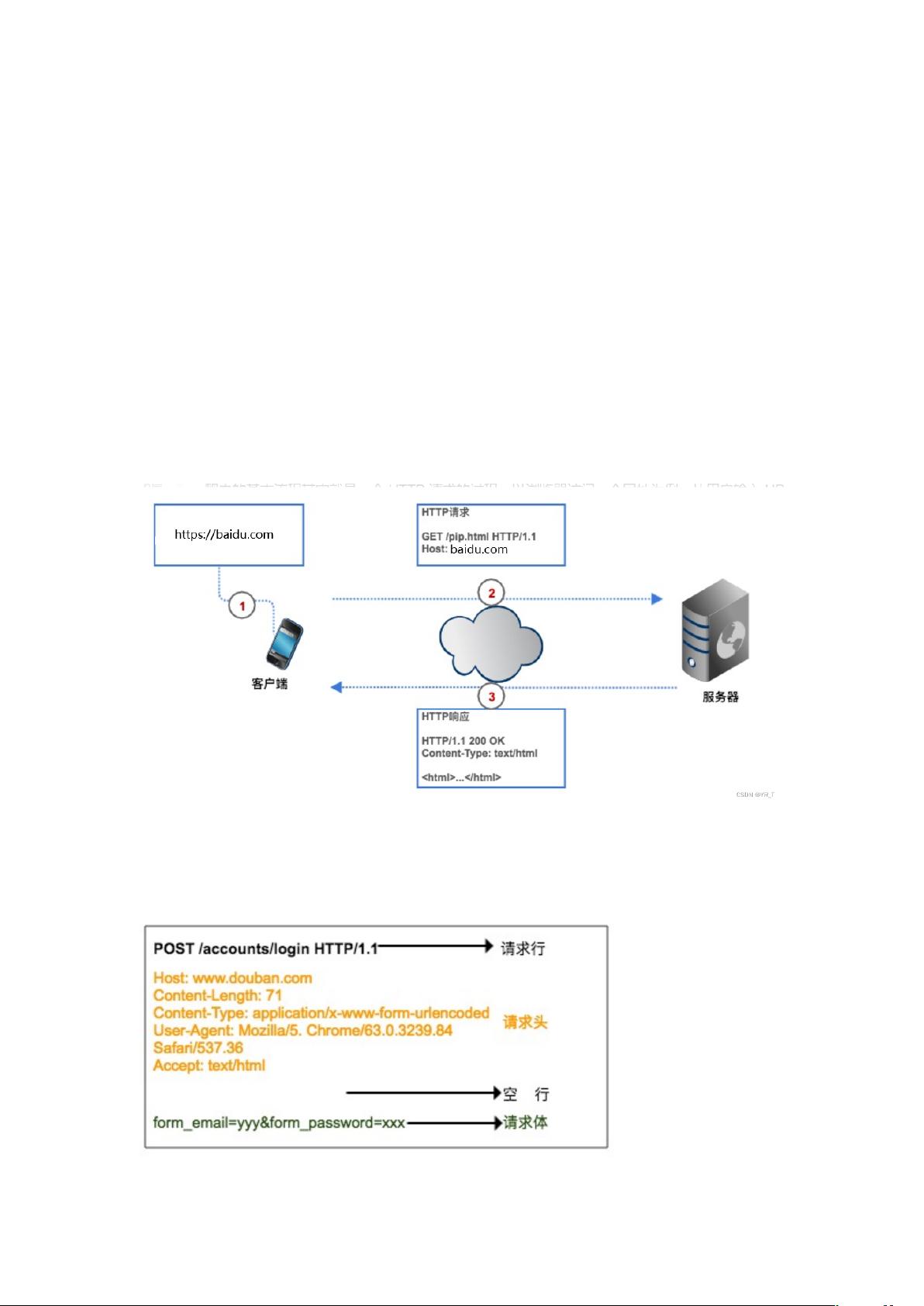
如果要获取网络上数据,我们要给爬虫一个网址(程序中通常叫 URL),爬虫发送一个 HTTP
请求给目标网页的服务器,服务器返回数据给客户端(也就是我们的爬虫),爬虫再进行数
据解析、保存等一系列操作。
流程
爬虫可以节省我们的时间,比如我要获取豆瓣电影 Top250 榜单,如果不用爬虫,我们要
先在浏览器上输入豆瓣电影的 URL ,客户端(浏览器)通过解析查到豆瓣电影网页的服务
器的 IP 地址,然后与它建立连接,浏览器再创造一个 HTTP 请求发送给豆瓣电影的服务
器,服务器收到请求之后,把 Top250 榜单从数据库中提出,封装成一个 HTTP 响应,然
后将响应结果返回给浏览器,浏览器显示响应内容,我们看到数据。我们的爬虫也是根据这
个流程,只不过改成了代码形式。
HTTP 请求
HTTP 请求由请求行、请求头、空行、请求体组成。
下载后可阅读完整内容,剩余8页未读,立即下载
511 浏览量
773 浏览量
521 浏览量
294 浏览量
304 浏览量
2024-02-03 上传
147 浏览量
103 浏览量
124 浏览量

千源万码
- 粉丝: 1110
- 资源: 419
 我的内容管理
展开
我的内容管理
展开







最新资源
- CLOYD_CANOY.github.io
- 深圳金中环商务大厦工程投标方案.zip
- AlmonteSnow
- PT100热电阻温度阻值计算器
- Umbraco-Forms-Bootstrap-4-Theme:Boostrap 4框架的Umbraco Forms插件的主题
- rosetta-inspector:Rosetta服务器实施检查器
- ReactTutorialRepo:使用devCodeCamp的react教程创建的基本react应用程序
- Erbele:Erbele是一款轻巧但功能强大的macOS文本编辑器
- 易语言学习-WEBUI支持库1.1静态库.zip
- 土壤湿度检测电路的设计,打造智能浇花系统-电路方案
- AllHookedUp
- copylot:您的副驾驶学习和工作(Pomodoro-timer,Translate and Notes应用)
- v4l2-ar0330-qt-ok.rar
- AeroFontOne
- roguelike_prog2:roguelike_prog2
- DataReporter:基于移动平台的实时数据报告系统
