利用机器学习的贝叶斯方法解密腾讯邮箱垃圾邮件
140 浏览量
更新于2024-06-17
收藏 2.38MB DOCX 举报
本资源主要探讨了如何使用机器学习中的贝叶斯方法来解密腾讯邮箱的垃圾邮件过滤问题。机器学习理论的核心在于设计和分析让计算机自动学习的算法,如监督学习、推荐系统和无监督学习。其中,监督学习特别提到了用于分类任务的模型,如支持向量机(SVM)、决策树和随机森林(GBDT),以及K近邻(KNN)等,这些算法在Python的Scikit-Learn库中有广泛应用。
Scikit-Learn是一个广泛使用的Python机器学习模块,提供了丰富的模型,适合于各种类型的机器学习问题。在这个背景下,作者提到了一个具体的例子,即使用Scikit-Learn中的逻辑回归算法对音乐数据进行分类。通过将音乐数据分解为频谱图,展示了时域和频域分析的概念,这两个概念在理解信号特征和变换上至关重要,例如傅里叶变换就是将信号从时域转换到频域,使得我们可以更深入地分析信号的频率成分。
在实际应用中,如反垃圾邮件系统,贝叶斯分类器是一种常用的策略,它基于贝叶斯定理,根据已有的训练数据来计算新邮件属于垃圾邮件的概率,从而决定是否将其归类为垃圾邮件。这个过程涉及到概率模型的构建和更新,以及特征选择和权重计算,是机器学习技术在邮箱过滤这类场景中的具体实践。
本资源深入介绍了如何利用机器学习中的贝叶斯分类方法来提升腾讯邮箱的垃圾邮件识别准确率,同时展示了时域和频域分析在数据处理中的作用,以及Python工具在实际项目中的运用。通过这个实例,读者可以了解到如何将理论知识转化为实际问题的解决方案。
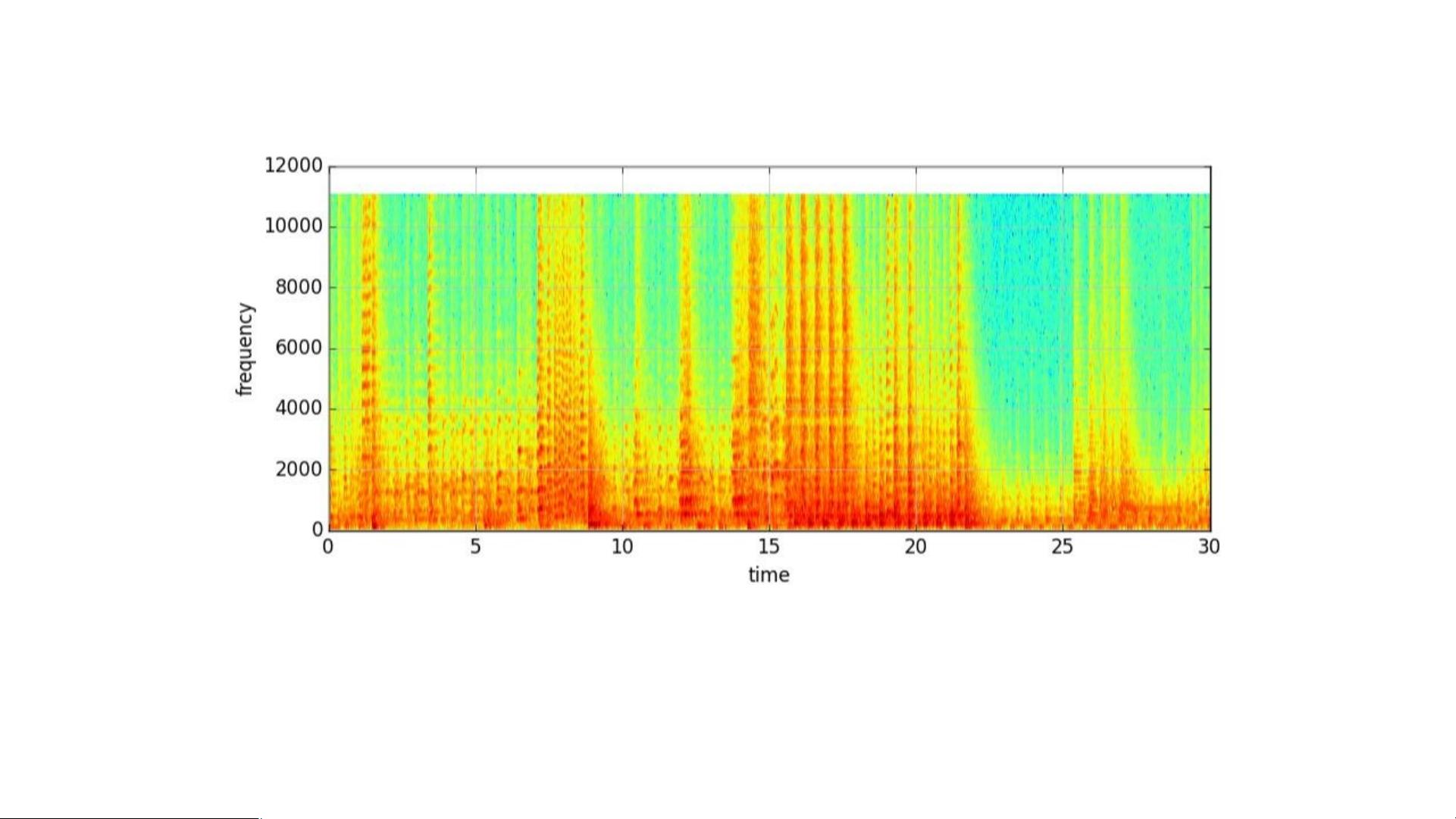
(spectrogram)来看看是什么样的 jazz

剩余37页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-06-14 上传
2022-11-28 上传
2019-08-13 上传
2024-05-01 上传

张飞的猪
- 粉丝: 4228
- 资源: 41
 我的内容管理
展开
我的内容管理
展开







最新资源
- 简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- 解线性方程组的直接法matlab实现
- 《ORANGE’S:一个操作系统的实现》读书笔记(三十五)内存管理(三)文章代码
- springCloud的ribbon和feign
- 一键安装Linux系统VNC服务端
- 简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- 蓝桥杯真题解析,常用算法和数据结构刷题
- 简历-求职简历-word-文件-简历模版免费分享-应届生-高颜值简历模版-个人简历模版-简约大气-大学生在校生-求职-实习
- GB2312 GBK GB18030的汉字编码表
- 51单片机教学实验箱代码
- Xmind思维导图300多套模板.zip
- C#-WPF基于MVVM开发的点餐demo
- Matlab实现随机数生成
- 本文提供的解密器(链接)均由互联网搜集.zip
- python推箱子游戏源码.zip
- python俄罗斯方块游戏源码.zip
