Flink 1.13 State Backend 优化与生产实践
需积分: 8 146 浏览量
更新于2024-06-26
1
收藏 7.28MB PDF 举报
"State backend Flink-1.13优化及生产实践分享.pdf"
Apache Flink 是一个流行的开源流处理框架,其在版本1.13中对State backend进行了多项优化和改进,旨在提升性能和稳定性,同时更好地适应大规模生产环境的需求。State backend是Flink中存储和管理状态的关键组件,它负责持久化和恢复任务的状态,以确保在系统故障或重启后能够准确地继续执行。
在Flink 1.13中,对State backend的主要变化包括:
1. 状态访问性能监控(latency tracking state):引入了对状态访问延迟的监控功能,通过记录每个操作的开始和结束时间来计算延迟,并使用直方图展示关键百分位数(如p50、p75、p95、p98、p99、p999),帮助开发者更好地理解和优化系统的性能瓶颈。这一特性可以通过配置项`state.backend.latency-track.keyed-state-enabled`、`state.backend.latency-track.sample-interval`和`state.backend.latency-track.history-size`进行控制。
2. 统一的Savepoint格式(FLINK-20976):Flink 1.13改进了Savepoint的格式,使其更加标准化,增强了不同State backend之间的互操作性。这意味着用户可以在不同类型的State backend之间迁移Savepoint,比如从Heap state backend切换到RocksDB state backend,而无需重新处理整个数据集。
3. 更清晰的API(FLINK-19463):对设置State backend的API进行了简化和统一,使得用户可以通过`env.setStateBackend(StateBackend)`方法更直观地选择和配置State backend,如`MemoryStateBackend()`、`MemoryStateBackend("file://path")`、`FsStateBackend()`和`RocksDBStateBackend()`。
RocksDB state backend内存管控优化:
RocksDB是一个高性能的键值存储库,常被用作Flink的State backend。在Flink 1.13中,对RocksDB的内存管理进行了优化,可能包括但不限于:
- 内存分配策略:改进了内存分配的方式,以减少碎片并提高内存利用率。
- 压缩策略:可能优化了数据压缩算法,以降低内存占用,同时保持读写速度。
- 缓存管理:调整了缓存的大小和替换策略,以平衡内存消耗和读取性能。
Flink state backend模块未来发展规划:
Flink社区可能将继续关注以下几个方面的发展:
- 扩展性:增加State backend的可扩展性,支持更多的持久化存储方案和定制化需求。
- 性能优化:针对大型工作负载和高并发场景进行性能调优,包括更快的状态访问和更低的延迟。
- 容错性:强化错误恢复机制,确保在故障情况下快速且准确地恢复状态。
- 资源管理:更好地集成到整体的资源管理系统中,实现更精细的内存和CPU管理。
这些优化和改进对于运行大规模、长时间运行的流处理作业至关重要,有助于提升系统的稳定性和效率,同时降低运维成本。在生产环境中应用这些更新,可以提高Flink应用的整体性能,减少延迟,以及增强系统的健壮性。
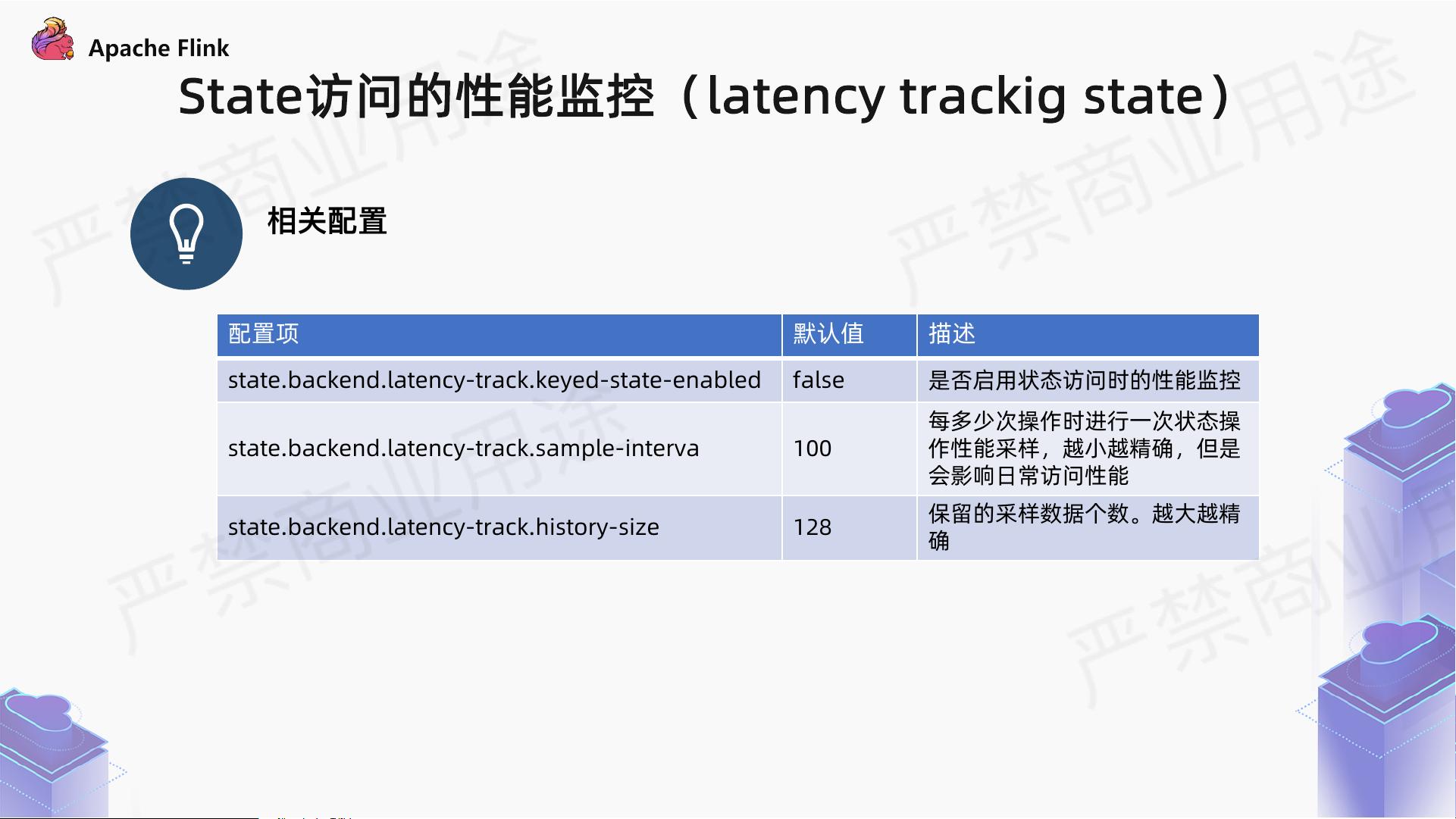
State访问的性能监控(latency trackig state)
相关配置
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/deployment/config/#state-backends-latency-tracking-options
配置项
默认值
描述
state.backend.latency
-track.keyed-state-enabled
false
是否启用状态访问时的性能监控
state.backend.latency
-track.sample-interva
100
每多少次操作时进行一次状态操
作性能采样
,越小越精确,但是
会影响日常访问性能
state.backend.latency
-track.history-size
128
保留的采样数据个数
。越大越精
确
剩余23页未读,继续阅读
104 浏览量
2022-04-12 上传
126 浏览量
2022-04-08 上传
2022-05-13 上传

远方有海,小样不乖
- 粉丝: 3689
- 资源: 57
 我的内容管理
展开
我的内容管理
展开







最新资源
- SMTPSender(iPhone源代码)
- 类似瀑布流的网格视图效果
- win7 64位安装IE11所需补丁
- WIFIRobots
- 多路DA上位机+单片机源码.zip
- cace:CMS管理员命令执行
- cursoKuberneteswildfly:Curso cursoKubernetes野蝇sobre Cubernetes
- mysql-connector-java-8.0.25.zip
- 建筑节能平台登录网页模板
- 网络游戏-基于移动无线网络、通过远程服务器进行地图解析的方法.zip
- PCBMill:PCBMill FABtotum插件
- 房屋出租管理系统.rar
- Google Chrome:trade_mark:的标签管理器-crx插件
- WindowsFormsApp1.zip
- agora:面向目标的敏捷需求获取
- webtesting-ii-guided:Web测试II模块指导项目
