C4.5、Kmeans、朴素贝叶斯与KNN:机器学习算法详解及其优缺点
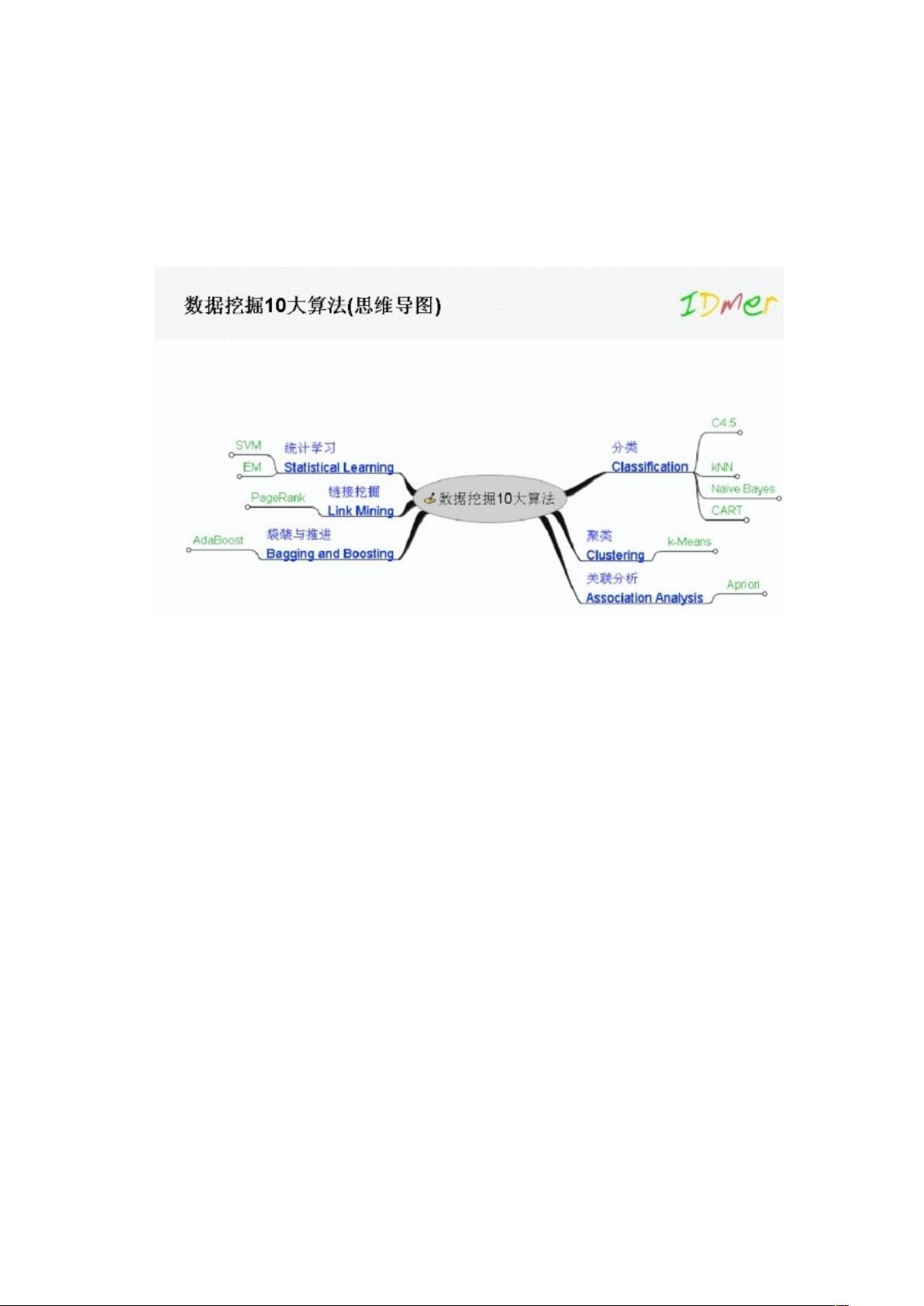
机器学习是一种强大的数据分析工具,它的成功很大程度上依赖于一系列经典的算法。本文将深入探讨机器学习中的十大算法,包括C4.5算法、K-means算法、朴素贝叶斯算法和K最近邻分类算法(KNN),以及EM最大期望算法,以便更好地理解和应用它们。
首先,C4.5算法是ID3算法的升级版,它利用信息增益率来替代信息增益,以解决取值多的属性优先的问题。C4.5可以处理连续和不完整数据,但在构造决策树时,由于频繁的数据扫描和排序,效率较低,且对内存容量有限制。
K-means算法作为聚类算法的基本代表,其目标是通过迭代优化失真函数,将数据分成k个紧密簇。然而,选择的簇数k需要预先设定,不当的k可能导致结果不佳。该算法的优点是计算速度快,但缺点是对初始聚类中心敏感,且不适用于非凸形状的簇。
朴素贝叶斯算法是基于贝叶斯定理和特征条件独立假设的分类方法,其假设简化了计算,使得分类过程快速且出错率低。在文本分类和垃圾邮件过滤等领域广泛应用,但其朴素假设在某些情况下可能过于简化现实。
K近邻算法(KNN)的分类依据的是样本之间的距离,简单直观。然而,K值的选择需要人工干预,且在样本不平衡的情况下,可能会受多数类样本影响。尽管适用于大规模样本,但对数据的存储要求较高。
最后,EM最大期望算法(Expectation-Maximization)是一种用于隐含变量模型的迭代方法,主要用于混合模型的参数估计。其优点在于能够处理复杂的模型结构,但计算复杂度相对较高,且对于初始参数选择敏感。
理解这些算法的核心思想、工作原理和适用场景,有助于我们针对不同的问题选择合适的机器学习模型,提高预测和分析的准确性。同时,了解它们各自的优缺点,可以帮助我们在实际应用中避免潜在的陷阱,提升算法的性能和效果。
下载后可阅读完整内容,剩余6页未读,立即下载
291 浏览量
2021-11-27 上传
136 浏览量
2013-03-18 上传
2024-04-15 上传
1578 浏览量
2021-10-05 上传
2071 浏览量
139 浏览量

zhulinniao
- 粉丝: 5074
 我的内容管理
展开
我的内容管理
展开







最新资源
- 初学者入门必备!Visual C++开发的连连看小程序
- C#实现SqlServer分页存储过程示例分析
- 西门子工业网络通信例程解读与实践
- JavaScript实现表格变色与选中效果指南
- MVP与Retrofit2.0相结合的登录示例教程
- MFC实现透明泡泡效果与文件操作教程
- 探索Delphi ERP框架的核心功能与应用案例
- 爱尔兰COVID-19案例数据分析与可视化
- 提升效率的三维石头制作插件
- 人脸C++识别系统实现:源码与测试包
- MishMash Hackathon:Python编程马拉松盛事
- JavaScript Switch语句练习指南:简洁注释详解
- C语言实现的通讯录管理系统设计教程
- ASP.net实现用户登录注册功能模块详解
- 吉时利2000数据读取与分析教程
- 钻石画软件:从设计到生产的高效解决方案
