

Chapter 1
Introduction
1.1 Thoughts behind the thesis
In the recent years, we have seen drastic improvements in various Speech Recogni-
tion technologies. Smart speech recognizing AIs like Siri, Alexa, Google Assistant,
Cortana etc. are just one tap away from us. These systems work awlessly in most
of the cases. However, depending on the variation in population of a country, every
language has many dierent dialects based on various regions. Even sophisticated
and highly advanced systems like the aforementioned ones have to face trouble when
the speaker does not speak in the standard accent of that language [14] . To tackle
this issue, quite a lot of research is already done in English, Mandarin and few other
prominent languages. However, while we were researching for related papers in this
eld, we barely found any work that was done in Bengali language. Worldwide al-
most 210 million [15] people speak in Bengali language. Among them, 100 million
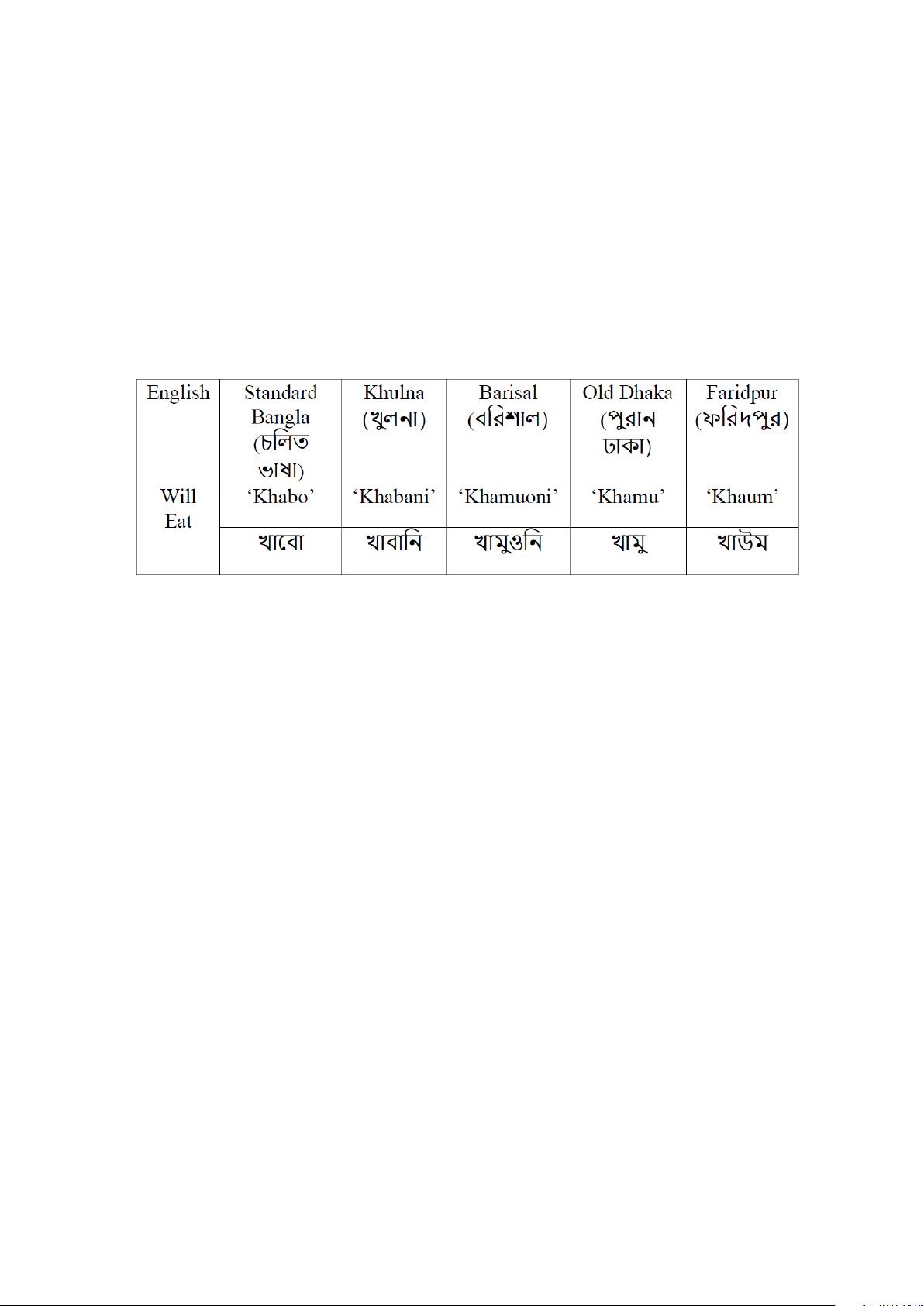
are from Bangladesh. Bangladesh is divided into 8 divisions and these divisions
are divided into dierent number of districts which totals in 64 districts. People
from these divisions speak in dierent dialect and accent. Furthermore, even in the
same division people’s accent varies greatly from district to district. These dierent
accents and dialect aect the performance of any Speech Recognizing system signif-
icantly. In this paper, we will try to build a model by training it on various audio
samples from few divisions and districts of Bangladesh. By using the approaches
discussed in this paper, it will be possible to easily distinguish accent of the speaker.
If separate ASR systems are created for each accents then our models will be able
to redirect the speakers audio to the ASR model which was built for the accent
of that speaker. Using the prediction of our models it might also be possible to
build a single ASR system which will be able to detect the spoken words accurately
regardless of the accent.
1
剩余47页未读,继续阅读

承让@
- 粉丝: 6
- 资源: 380
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- VMP技术解析:Handle块优化与壳模板初始化
- C++ Primer 第四版更新:现代编程风格与标准库
- 计算机系统基础实验:缓冲区溢出攻击(Lab3)
- 中国结算网上业务平台:证券登记操作详解与常见问题
- FPGA驱动的五子棋博弈系统:加速与创新娱乐体验
- 多旋翼飞行器定点位置控制器设计实验
- 基于流量预测与潮汐效应的动态载频优化策略
- SQL练习:查询分析与高级操作
- 海底数据中心散热优化:从MATLAB到动态模拟
- 移动应用作业:MyDiaryBook - Google Material Design 日记APP
- Linux提权技术详解:从内核漏洞到Sudo配置错误
- 93分钟快速入门 LaTeX:从入门到实践
- 5G测试新挑战与罗德与施瓦茨解决方案
- EAS系统性能优化与故障诊断指南
- Java并发编程:JUC核心概念解析与应用
- 数据结构实验报告:基于不同存储结构的线性表和树实现
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


