本地化图文视频生成网站搭建教程:使用Stable Diffusion
版权申诉
"这篇教程详细介绍了如何搭建一个本地化的图文视频生成网站,使用了Stable Diffusion AI图像生成模型,并附带源码。教程分为五个部分,包括搭建AI网站、模型下载安装、汉化插件安装、模拟真人图片生成及图片开口说话功能。"
在当前的AI技术领域,Stable Diffusion是一个关键的图像生成模型,它使得文本到图像的生成变得更加普遍和易于操作。这个模型被用来训练真实人物的图片,生成的图像逼真度极高,以至于难以分辨是否由AI创作。针对对此感兴趣的读者,本教程提供了一个从零开始的指南,教大家构建一个基于Stable Diffusion的本地化AI图像生成网站,即Midjourney。
首先,搭建自己的AI网站需要确保具备Python环境,具体要求是Python 3.10.6版本。如果已有其他Python版本,可以通过conda创建一个特定于3.10.6的虚拟环境。接下来,需要从GitHub上克隆名为`stable-diffusion-webui`的仓库代码,这包含了运行网站所需的基础框架。
然后,为了运行模型,需要安装与GPU兼容的Pytorch版本。官方Pytorch网站提供了详细的安装指南,根据个人硬件配置选择合适的版本进行安装。安装过程中,可能还需要其他依赖库,如CUDA或cuDNN,这些都是用于GPU加速的关键组件。
在模型下载安装环节,教程可能涉及模型权重的获取和放置到正确的位置,以便AI能够正确识别并使用这些模型来生成图像。此外,对于非英语使用者,教程还涵盖了汉化插件的下载和安装,这将使用户界面更加友好和易于理解。
生成模拟真人图片是教程的重点内容,包括以下步骤:
1. 生成模拟真人图片:通过输入文本指令,模型会根据描述生成类似真实人物的图像。
2. 不同风格图片生成:用户可以指定不同的艺术风格,让AI生成具有特定风格的图像作品。
3. 动画视频生成:更进一步,教程还将介绍如何利用模型生成动态视频,这需要更复杂的处理和渲染技术。
最后,教程还涉及到一个独特且有趣的特性,即“生成的图片开口说话”。这意味着AI不仅能够创建图像,还能为生成的图像添加语音合成,使其仿佛能“说话”。
通过这个详尽的教程,读者不仅可以学习到AI图像生成的基本原理,还能实际动手建立一个自定义的、具有多种功能的AI图像生成平台,从而深入理解和应用这一前沿技术。同时,附带的源码可以帮助读者更好地理解和修改代码,以适应个人需求。
2023/5/19
【详细教程】教你自己搭建一个本地化图文视频生成网站(附源码)
https://mp.weixin.qq.com/s?__biz=MzI0NjU0NDU5MA==&tempkey=MTIxOF9RNlZESnhFSmZ3ekpSMHFlT2R2eGh0SXV0X2hobm1JNTBDb2gxeWFlTl
…
4/17
进
入
下
载
的
G
i
t
h
u
b
仓
库
的
代
码
文
件
夹
,
安
装
第
三
方
依
赖
:
02
:
模
型
下
载
安
装
有
了
网
站
,
还
需
要
下
载
对
应
的
AI
模
型
。
有
些
朋
友
已
经
利
用
大
量
的
图
片
训
练
好
的
模
型
分
享
到
网
站
上
了
,
比
如
:
h
ttps
://
ci
v
i
t
ai
.
c
o
m
/
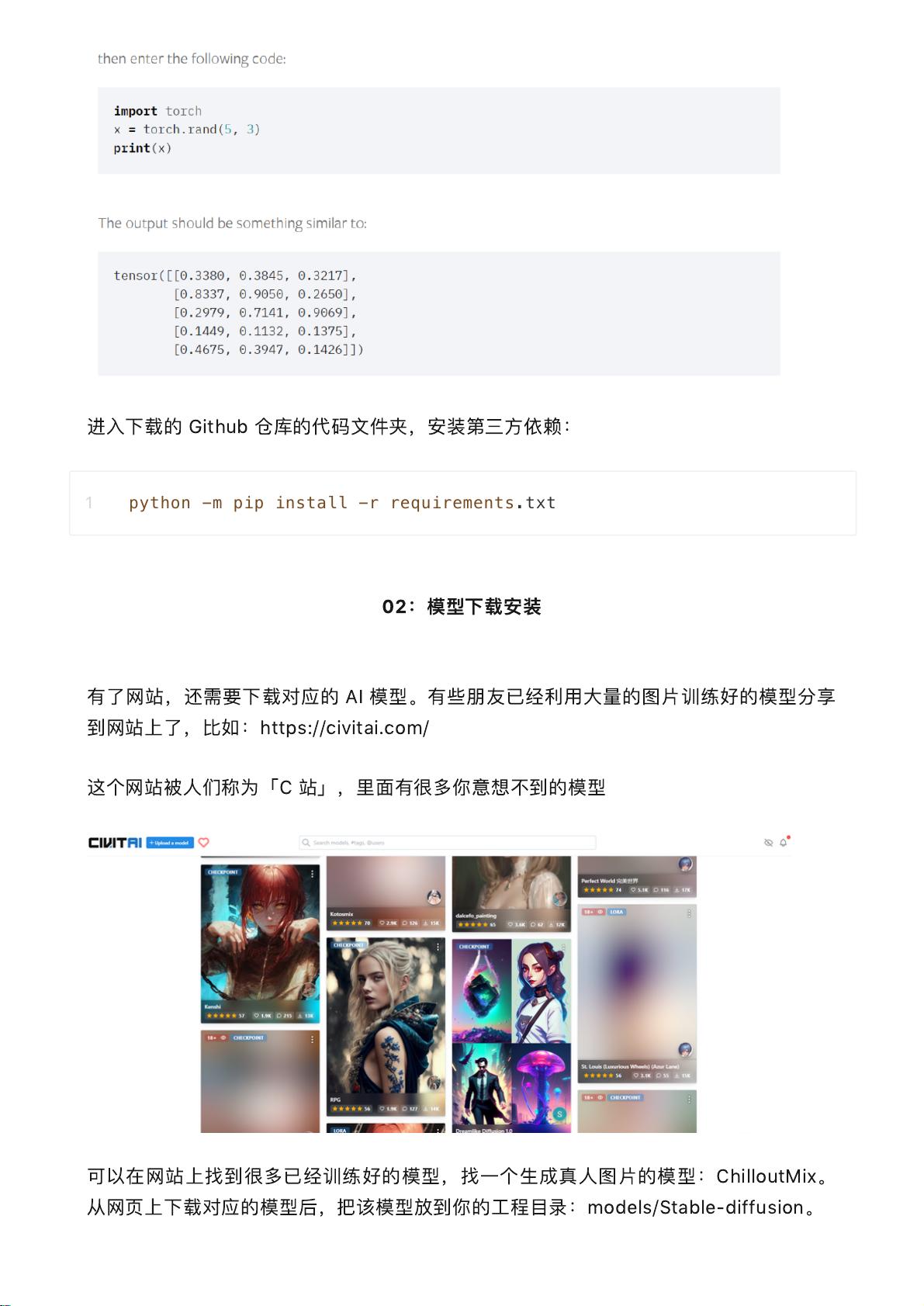
这
个
网
站
被
人们
称
为
「
C
站
」
,
里
面
有
很
多
你
意想
不
到
的
模
型
可
以
在
网
站
上
找
到
很
多
已
经
训
练
好
的
模
型
,
找
一个
生
成
真
人
图
片
的
模
型
:
C
hill
out
M
i
x
。
从
网
页
上下
载
对
应
的
模
型
后
,
把
该
模
型
放
到
你
的
工
程
目
录
:
m
o
del
s
/
S
t
able
‑
diff
us
i
o
n
。
1
python -m pip install -r requirements.txt
剩余16页未读,继续阅读
相关推荐


730 浏览量




ChatGPT4.0
- 粉丝: 2002
 我的内容管理
展开
我的内容管理
展开







最新资源
- VB实现Excel数据导入到ListView控件技术
- 触屏版wap购物网站模板及多技术源码大全
- ZOJ1027求串相似度解题策略与代码分析
- Excel表格数据合并工具:高效整合多个数据源
- MFC列表控件:实现下拉选择与编辑功能
- Tinymce4集成Powerpaste插件即用版使用教程
- 探索QMLVncViewer:Qt Quick打造的VNC查看器
- Mybatis生成器:快速自定义实体类与Mapper文件
- Dota 2插件开发:TrollsAndElves自定义魔兽3地图攻略
- C语言编写单片机控制蜂鸣器唱歌教程
- Ansible自动化脚本简化Ubuntu本地配置流程
- 探索ListView扩展:BlurStickyHeaderListView源码解析
- 探索traces.vim插件:Vim的范围选择与模式高亮预览
- 快速掌握Ruby编译与安装的神器:ruby-build
- C语言实现P1口灯花样控制源代码及使用指南
- 会员管理系统:消费激励方案及其源代码
