史上最全:一步步教你搭建Hadoop+Spark大数据集群
 已收录资源合集
已收录资源合集
需积分: 0 49 浏览量
更新于2024-06-16
收藏 5.93MB DOCX 举报
"该文档提供了最简单的Hadoop+Spark大数据集群搭建方法,适用于3-4节点的完全分布式集群。内容涵盖环境准备,包括设置机器名、IP映射、SSH免密和Java安装,以及Zookeeper、Hadoop、Hive、Spark的安装过程。此外,文档还通过表格形式详细列出了不同节点的角色分配,如namenode、secondarynamenode、datanode和resourcemanager,并提供了可访问的IP地址和用户名密码。特别指出,对于阿里云环境,直接使用公网IP,而校园网环境下则需提供公网和校园网IP。文档强调图文并茂,包含详细步骤、说明和截图,适合初学者学习。"
在搭建Hadoop+Spark大数据集群的过程中,首先要确保你有合适的硬件环境,例如在VMware中创建多个CentOS虚拟机。创建虚拟机时,应根据实际硬件资源分配处理器和内存,并选择合适的网络类型,通常选择网络地址转换(NAT),以便虚拟机连接到外部网络。
接下来是基础环境的配置,包括:
1. 设置主机名:每个节点需要有唯一的主机名,例如node1、node2和node3。
2. 配置IP映射:在/etc/hosts文件中添加所有节点的IP和主机名映射,确保各节点间能互相识别。
3. 安装Java:Hadoop、Spark等大数据组件依赖Java运行环境,因此需要安装Java JDK并配置环境变量。
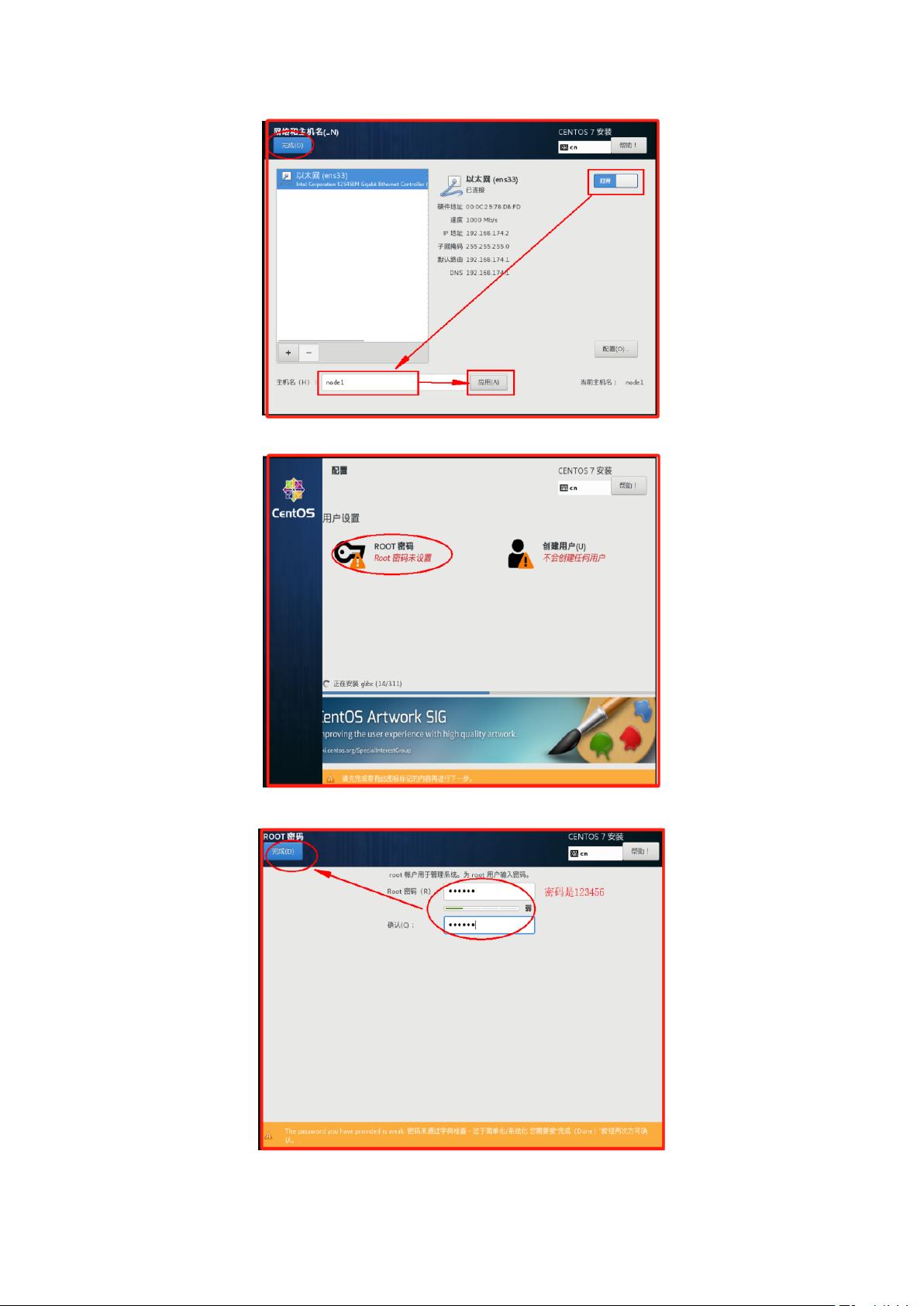
4. SSH免密登录:通过ssh-keygen生成公钥和私钥,并将公钥复制到其他所有节点的authorized_keys文件中,实现无密码登录。
然后,依次安装和配置各个大数据组件:
1. Zookeeper:作为协调服务,用于Hadoop和Spark的元数据管理。安装Zookeeper,配置相关参数如dataDir和clientPort,并启动服务。
2. Hadoop:包括HDFS和YARN。安装Hadoop,配置core-site.xml、hdfs-site.xml、yarn-site.xml等核心配置文件,指定NameNode、Secondary NameNode、DataNode和ResourceManager的角色分配。初始化HDFS,格式化NameNode,并启动Hadoop服务。
3. Hive:基于Hadoop的数据仓库工具,允许使用SQL查询HDFS上的数据。安装Hive,配置hive-site.xml,设置metastore数据库(通常使用MySQL或Derby),并将Hive库添加到Hadoop的类路径中。
4. Spark:分布式计算框架。安装Spark,配置spark-env.sh、spark-defaults.conf,指定Master和Executor的节点,以及与Hadoop的交互方式。
最后,为了便于开发和测试,可以安装Eclipse或IntelliJ IDEA,并配置对应的Hadoop和Spark插件,以便在IDE中编写、运行和调试Spark程序。
整个过程中,务必注意各个组件的版本兼容性,确保它们能正常协同工作。同时,配置文件的正确性和完整性至关重要,任何小错误都可能导致集群无法正常运行。通过这个文档,读者将能够逐步理解并掌握大数据集群的搭建过程,为后续的大数据学习和实践打下坚实基础。
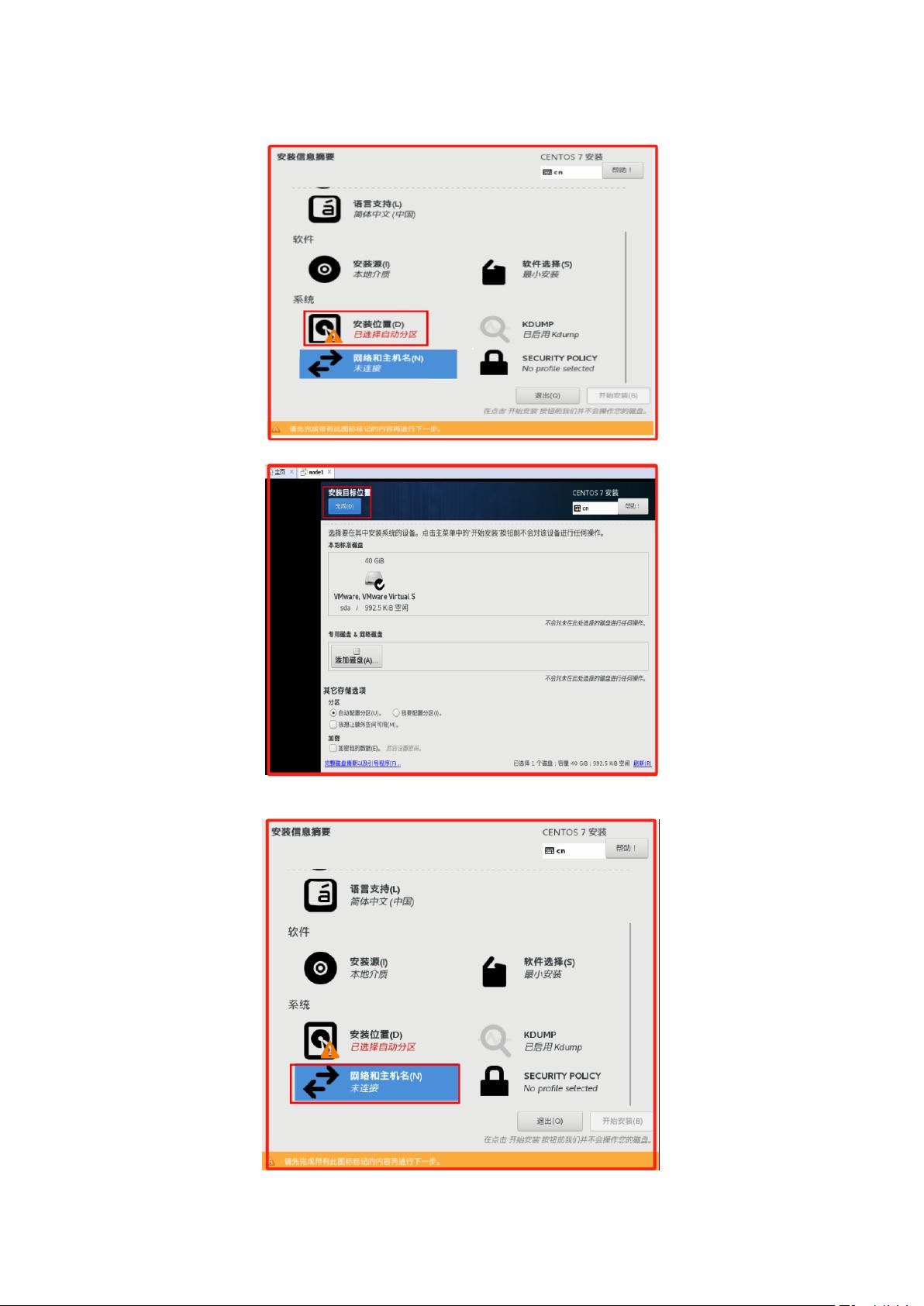
(20)进行安装位置配置
(20)进行网络和主机名配置,主机名为 node1
剩余46页未读,继续阅读
2023-11-07 上传
2022-07-27 上传
2024-05-08 上传
2020-09-17 上传

卡林神不是猫
- 粉丝: 5479
- 资源: 17
 我的内容管理
展开
我的内容管理
展开







最新资源
- node-selenium-driver-filedetector:具有文件检测器绑定的节点网络驱动程序
- spring-boot-graphql
- remixed2recipes
- 星级酒店预定主题响应式模板
- 企业门户网站管理系统,包括前台展示、后台管理、后端服务(Node.js、Koa、sequelize、MySQL),前.zip
- cordova-plugin-mmedia:千禧一代媒体广告的CordovaPhoneGap
- Lita:公司聊天室的机器人伴侣-开源
- eslint-plugin-jsx-extras:一组Eslint插件,用于基于应用程序的特定JSX规则
- bls_custom:粘在一起将Blocky Survival Minetest服务器固定在一起
- 进口玻璃磨边机PLC程序.rar
- Schizo-crx插件
- angular-starter:基于angularJS框架的全初始化前端项目
- javascript-dom-exercises-2.3
- TheGrid:按键游戏
- autotrader-scraper:用于刮擦自动交易器网站以获取汽车图像的工具。 我用它们来训练神经网络
- 库:通用功能的声明。 存储库的内容不属于GNU C库
