Spark Streaming实战:优化HBase与任务管理策略
173 浏览量
更新于2024-08-29
收藏 443KB PDF 举报
Spark Streaming 是Apache Spark的重要组成部分,用于处理实时流数据。在"Spark Streaming应用与实战全攻略(Ⅱ)"中,本篇主要聚焦于第5部分的持续优化,特别是与HBase的集成及管理。HBase作为NoSQL数据库,其在Spark Streaming中的优化至关重要。
首先,文章介绍了Spark Streaming的基本背景和架构改造,强调了从批处理模型向实时流处理的转变,这涉及到数据源的选择、数据流的处理逻辑和性能优化。第二部分的核心内容是通过代码实现HBase的连接和数据写入,以及如何配置Write Ahead Log (WAL)。关闭WAL后,虽然写入速度有所提升,但发现性能仍然不稳定,尤其是在数据量大时,可能由于频繁的Compaction操作导致。
Compaction是HBase用来维护数据存储效率的关键机制。它分为两种类型:Minor Compaction(小合并)和Major Compaction(大合并)。 Minor Compaction主要合并小的、相邻的StoreFile,不处理已删除或过期的Cell,目标是减少文件数量并提高查询性能。Major Compaction则更为彻底,会合并所有StoreFile,并清理无用数据,如已删除、过期和超出版本限制的数据,但这可能导致短暂的服务中断。
在实践中,优化HBase与Spark Streaming的配合需要注意监控系统的使用,实时查看Streaming统计信息,以便及时发现问题并调整参数。例如,通过HBase界面的统计信息可以追踪Compaction的频率和影响,这有助于找到性能瓶颈并采取针对性的优化措施。
此外,管理Streaming任务也是本篇讨论的重点,包括任务调度策略、资源分配以及如何确保任务的稳定性和可靠性。有效的任务管理能够保证系统在面对高并发和大数据流时仍能保持高效运行。
"Spark Streaming应用与实战全攻略(Ⅱ)"深入探讨了如何通过技术手段和实践经验优化Spark Streaming与HBase的集成,帮助开发者提升实时流处理的性能和稳定性,实现业务的高效运作。
SparkStreaming应用与实战全攻略(应用与实战全攻略(Ⅱ))
Spark Streaming应用与实战系列包括以下六部分内容:
1.背景与架构改造
2.通过代码实现具体细节,并运行项目
3.对Streaming监控的介绍以及解决实际问题
4.对项目做压测与相关的优化
5.Streaming持续优化之HBase
6.管理Streaming任务
点此阅读第一部分内容,本篇为第二部分,包括 Streaming 持续优化之 HBase 以及管理 Streaming 任务。
五、Streaming持续优化之HBase
5.1 设置WALog
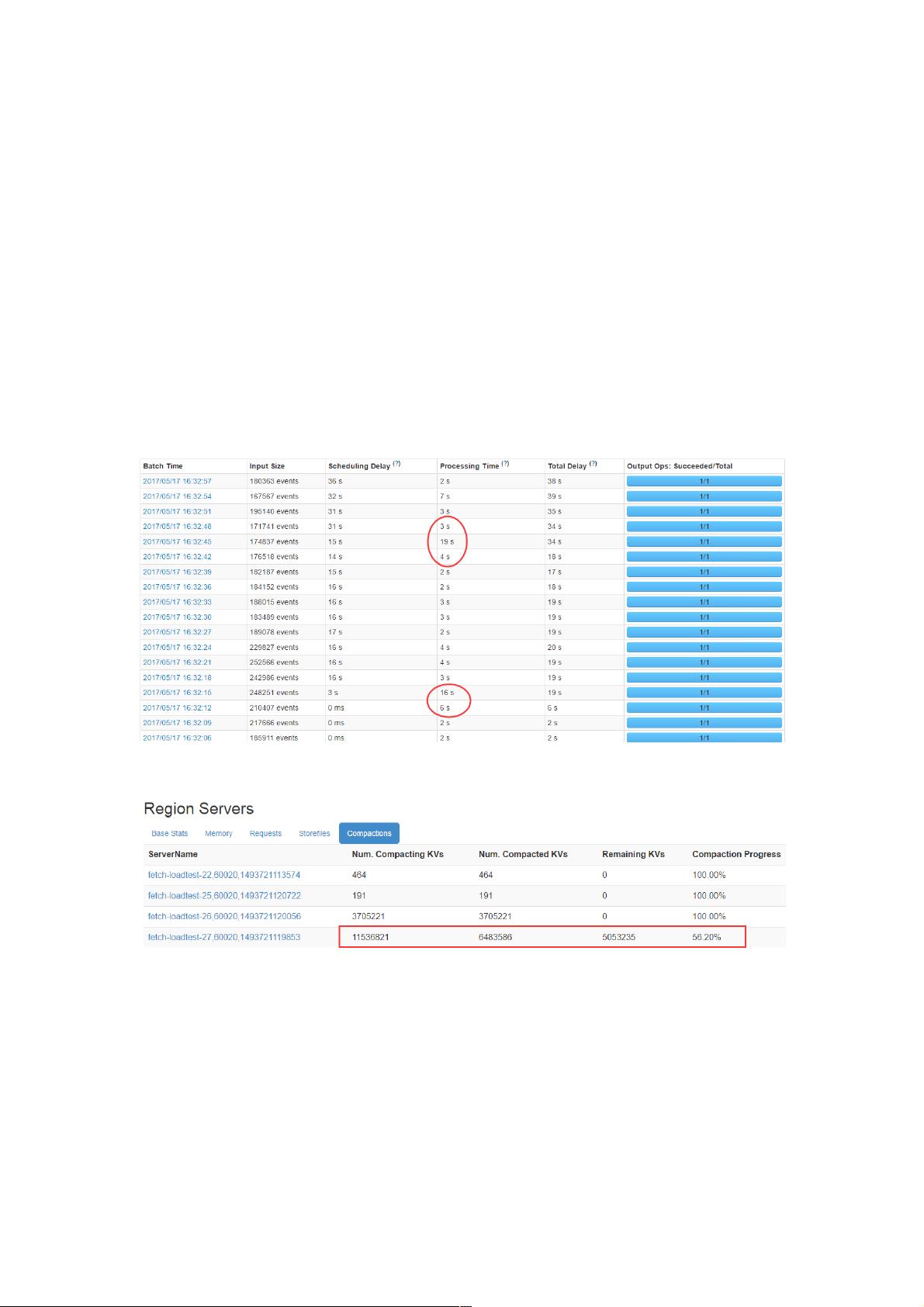
关闭WALog后写入能到20万,但是发现还是不是特别稳定,有时耗时还是比较长的,发现此阶段正在做Compaction!!!
查看streaming统计,发现耗时不稳定
HBase界面统计信息
HBase是一种 Log-Structured Merge Tree 架构模式,用户数据写入先写WAL,再写缓存,满足一定条件后缓存数据会执行
flush操作真正落盘,形成一个数据文件HFile。随着数据写入不断增多,flush次数也会不断增多,进而HFile数据文件就会越来
越多。然而,太多数据文件会导致数据查询IO次数增多,因此HBase尝试着不断对这些文件进行合并,这个合并过程称为
Compaction。
Compaction会从一个 region 的一个 store 中选择一些 hfile 文件进行合并。合并说来原理很简单,先从这些待合并的数据文件
中读出KeyValues,再按照由小到大排列后写入一个新的文件中。之后,这个新生成的文件就会取代之前待合并的所有文件对
外提供服务。
HBase根据合并规模将 Compaction 分为了两类: inorCompaction 和 MajorCompaction 。
1. Minor Compaction 是指选取一些小的、相邻的 StoreFile 将他们合并成一个更大的 StoreFile ,在这个过程中不会处理已经
Deleted 或 Expired 的 Cell 。一次 Minor Compaction 的结果是更少并且更大的 StoreFile 。
2. Major Compaction 是指将所有的 StoreFile 合并成一个 StoreFile ,这个过程还会清理三类无意义数据:被删除的数据、
下载后可阅读完整内容,剩余3页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-02-25 上传
2015-02-15 上传
2022-07-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38534344
- 粉丝: 0
- 资源: 916
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
