探索TiDB分布式架构:无状态服务与数据存储详解
版权申诉
83 浏览量
更新于2024-08-06
收藏 609KB DOC 举报
本文档主要介绍了TiDB的基础架构,针对对MySQL有深入理解但寻求分布式数据库解决方案的读者群体。TiDB作为一款分布式SQL数据库,它的出现旨在解决单体数据库在高并发和大数据场景下的性能瓶颈问题。
首先,文档从TiDBServer的视角入手,强调了TiDB作为一个分布式系统的特性。TiDBServer不仅扮演着MySQLServer的角色,负责接收客户端的SQL请求,解析、优化并生成分布式执行计划,但与MySQL的传统架构有所不同。TiDBServer是无状态的,这意味着它不依赖于任何单个节点的状态信息,这使得它具备良好的可扩展性,能够轻松应对海量数据和高并发情况。相比之下,MySQLServer由于与底层存储引擎紧密集成,且在内存中缓存数据,是带有状态的,限制了其扩展性。
在存储层面,TiDB采用了一种分布式列式存储的设计,类似于RedisCluster,能够高效地存储和管理大量数据。当用户执行插入(Insert)操作时,TiDBServer会将SQL请求分解为一系列操作,这些操作会被分布到不同的存储节点,实现了数据的水平扩展。同时,TiDB支持MySQL的大部分语法,这使得开发人员可以无缝地迁移和操作数据,降低了学习曲线。
文章还提到了TiDB如何处理数据一致性问题,尽管分布式系统通常面临分区容错和强一致性的权衡,但TiDB通过Paxos和Raft等分布式一致性算法,确保了即使在分布式环境中也能提供较高的数据一致性保证。此外,文档可能还会涉及TiDB的数据复制机制、故障恢复策略以及读写分离等关键特性,这些都是理解TiDB架构的重要组成部分。
总结来说,这篇文档为读者提供了对TiDB架构的入门级介绍,帮助他们理解分布式数据库在处理大规模数据和高并发场景中的优势,以及TiDB如何通过无状态设计、分布式存储和一致性算法来实现这一目标。对于希望通过分布式数据库升级现有系统的开发者和技术决策者,这篇文章提供了有价值的参考信息。
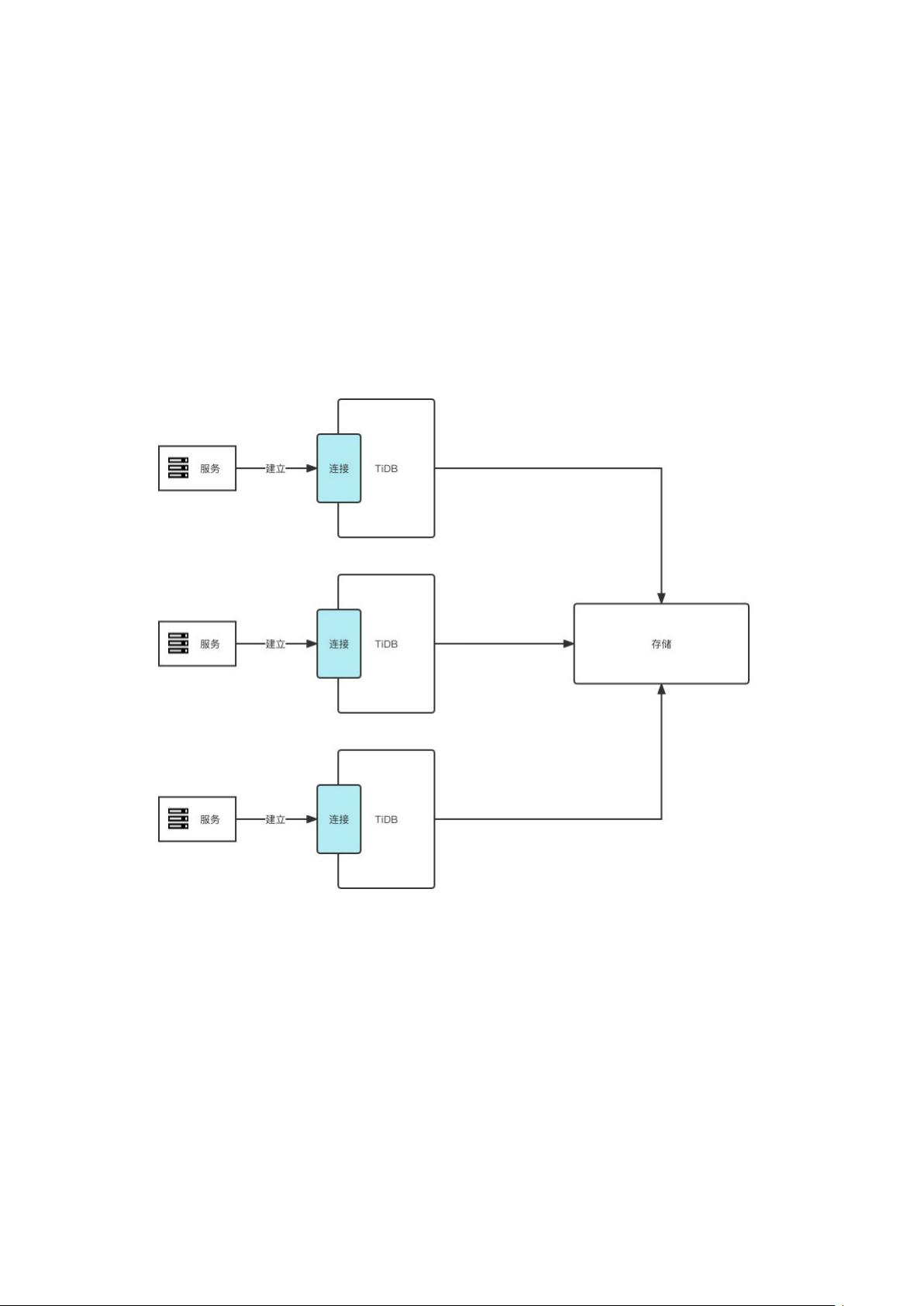
页的数据,是有状态的。
这里其实可以简单的把两者理解为,TiDB 是无状态的可横向扩展的服务。而 MySQL
则是在内存中缓存了业务数据、无法横向扩展的单体服务。
而由于 TiDB Server 的无状态特性,在生产中可以启动多个实例,并通过负载均衡的策
略来对外提供统一服务。
实际情况下,TiDB 的存储节点是单独、分布式部署的,这里只是为了方便理解 TiDB Server
的横向扩展特性,不用纠结,后面会聊到存储
总结下来,TiDB Server 只干一件事:负责解析 SQL,将实际的数据操作转发给存储节点。
2.TiKV
我们知道,对于 MySQL,其存储引擎(绝大多数情况)是 InnoDB,其存储采用的数据
结构是 B+ 树,最终以 .ibd 文件的形式存储在磁盘上。那 TiDB 呢?
剩余12页未读,继续阅读
2018-03-25 上传
2022-01-16 上传
2020-04-24 上传
2021-12-23 上传
2021-01-30 上传
2021-01-30 上传
2021-05-11 上传

书博教育
- 粉丝: 1
- 资源: 2837
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
