大规模弱监督下的语音识别技术
需积分: 2 186 浏览量
更新于2024-06-16
收藏 985KB PDF 举报
"这篇论文研究了使用大规模弱监督训练的语音识别系统,通过预测互联网上的大量音频转录来提升模型的鲁棒性。在680,000小时的多语言、多任务监督下训练的模型在标准基准测试中表现出良好的泛化能力,与全监督方法的结果相当,但无需微调。这些模型在与人类的比较中接近其准确性和鲁棒性,论文作者将发布模型和推理代码,以促进对鲁棒语音处理的进一步研究。Wav2Vec2.0等无监督预训练技术的发展推动了语音识别的进步,这些方法能直接从原始音频学习,无需人类标注,能够有效利用大量未标注的语音数据,并已迅速扩展到1,000,000小时的训练数据规模。"
本文探讨的核心知识点是基于大规模弱监督的鲁棒语音识别技术。弱监督学习是指在有限或者不完全的标注数据下进行学习,这种方法通常用于处理大规模数据集,因为它允许模型从大量未标注的样本中学习模式。在这种情况下,模型被训练去预测互联网上大量音频的转录,从而实现无监督或弱监督的学习。
Wav2Vec2.0是一种代表性的无监督预训练技术,它通过学习音频的原始特征,显著提升了语音识别的性能,而不需要人工标注的数据。这种技术的出现,使得研究人员能够利用未标注的语音数据进行大规模训练,进一步推动了语音识别领域的进步。
论文中提到,当模型在680,000小时的多语言和多任务监督下训练后,其在标准评估基准上的表现优秀,甚至可以与全监督训练的模型相媲美,而且在零样本转移设置下,即不需要额外的微调就能达到这样的效果。这表明,弱监督学习在减少对标注数据依赖的同时,依然能够实现高性能的模型。
此外,这些经过训练的模型在与人类的准确性及鲁棒性对比中,表现接近,这表明模型在处理各种语音环境和噪声条件下的表现非常出色。为了鼓励更多的研究,作者决定公开模型和推理代码,这将为后续的鲁棒语音处理工作提供基础。
这篇论文揭示了弱监督学习在语音识别中的潜力,特别是在构建鲁棒且适应性强的模型方面,同时也强调了无监督预训练技术如Wav2Vec2.0在处理大规模语音数据集时的重要性。这一研究对于未来在语音识别领域提高模型的泛化能力和降低对人工标注数据的依赖具有重要意义。
Robust Speech Recognition via Large-Scale Weak Supervision 6
0 1 2 3 4 5 6 7 8
WER on LibriSpeech dev-clean (%)
0
10
20
30
40
50
Average WER on [Common Voice, CHiME-6, TED-LIUM] (%)
Supervised LibriSpeech models
Zero-shot Whisper models
Zero-shot Human (Alec)
Ideal robustness (y = x)
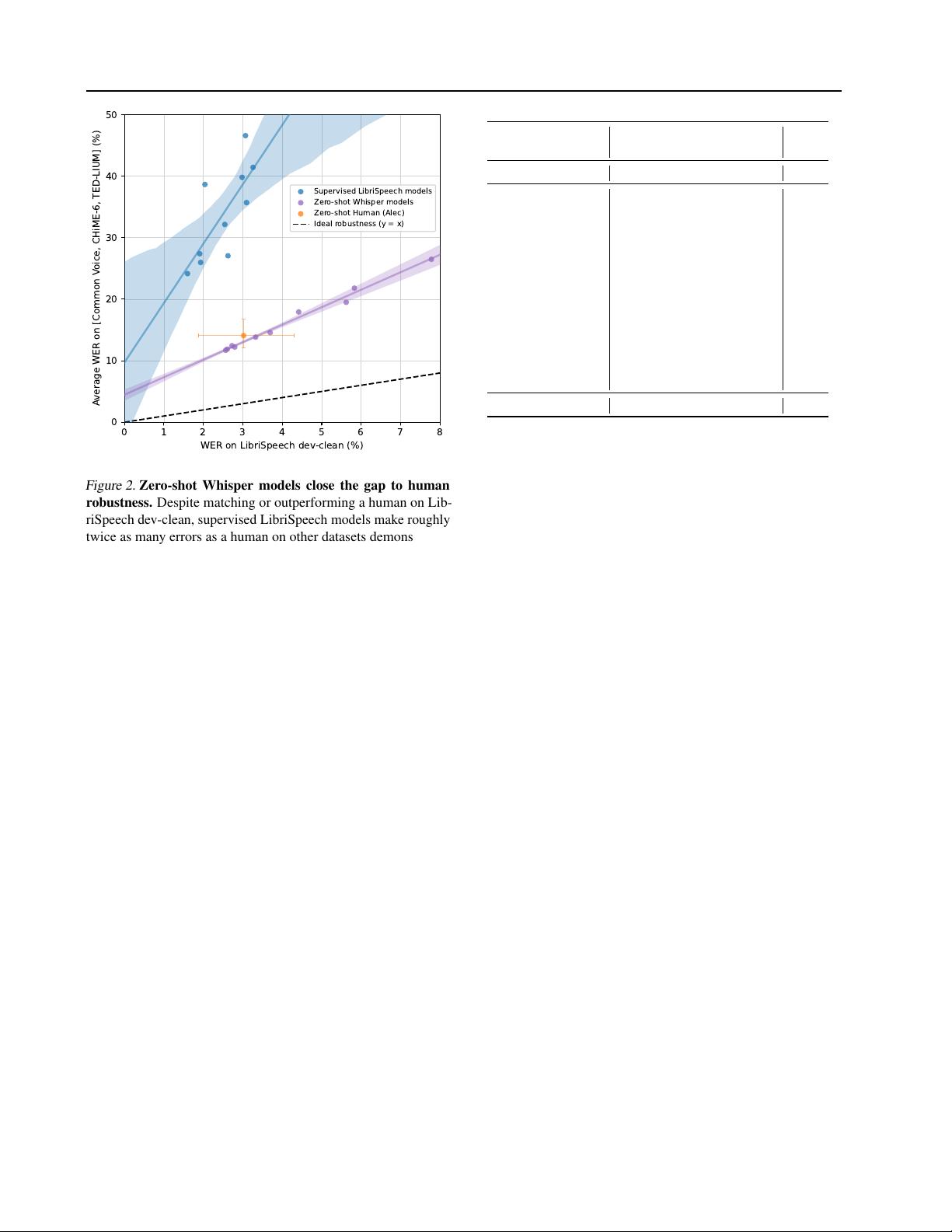
Figure 2. Zero-shot Whisper models close the gap to human
robustness.
Despite matching or outperforming a human on Lib-
riSpeech dev-clean, supervised LibriSpeech models make roughly
twice as many errors as a human on other datasets demonstrating
their brittleness and lack of robustness. The estimated robustness
frontier of zero-shot Whisper models, however, includes the 95%
confidence interval for this particular human.
To quantify this difference, we examine both overall ro-
bustness, that is average performance across many distribu-
tions/datasets, and effective robustness, introduced by Taori
et al. (2020), which measures the difference in expected
performance between a reference dataset, which is usually
in-distribution, and one or more out-of-distribution datasets.
A model with high effective robustness does better than
expected on out-of-distribution datasets as a function of its
performance on the reference dataset and approaches the
ideal of equal performance on all datasets. For our analy-
sis, we use LibriSpeech as the reference dataset due to its
central role in modern speech recognition research and the
availability of many released models trained on it, which
allows for characterizing robustness behaviors. We use a
suite of 12 other academic speech recognition datasets to
study out-of-distribution behaviors. Full details about these
datasets can be found in Appendix A.
Our main findings are summarized in Figure 2 and Table 2.
Although the best zero-shot Whisper model has a relatively
unremarkable LibriSpeech clean-test WER of 2.5, which
is roughly the performance of modern supervised baseline
or the mid-2019 state of the art, zero-shot Whisper models
have very different robustness properties than supervised
LibriSpeech models and out-perform all benchmarked Lib-
riSpeech models by large amounts on other datasets. Even
wav2vec 2.0 Whisper RER
Dataset Large (no LM) Large V2 (%)
LibriSpeech Clean 2.7 2.7 0.0
Artie 24.5 6.2 74.7
Common Voice 29.9 9.0 69.9
Fleurs En 14.6 4.4 69.9
Tedlium 10.5 4.0 61.9
CHiME6 65.8 25.5 61.2
VoxPopuli En 17.9 7.3 59.2
CORAAL 35.6 16.2 54.5
AMI IHM 37.0 16.9 54.3
Switchboard 28.3 13.8 51.2
CallHome 34.8 17.6 49.4
WSJ 7.7 3.9 49.4
AMI SDM1 67.6 36.4 46.2
LibriSpeech Other 6.2 5.2 16.1
Average 29.3 12.8 55.2
Table 2. Detailed comparison of effective robustness across
various datasets.
Although both models perform within 0.1%
of each other on LibriSpeech, a zero-shot Whisper model performs
much better on other datasets than expected for its LibriSpeech
performance and makes 55.2% less errors on average. Results
reported in word error rate (WER) for both models after applying
our text normalizer.
the smallest zero-shot Whisper model, which has only 39
million parameters and a 6.7 WER on LibriSpeech test-clean
is roughly competitive with the best supervised LibriSpeech
model when evaluated on other datasets. When compared
to a human in Figure 2, the best zero-shot Whisper models
roughly match their accuracy and robustness. For a detailed
breakdown of this large improvement in robustness, Table
2 compares the performance of the best zero-shot Whisper
model with a supervised LibriSpeech model that has the
closest performance to it on LibriSpeech test-clean. Despite
their very close performance on the reference distribution,
the zero-shot Whisper model achieves an average relative
error reduction of 55.2% when evaluated on other speech
recognition datasets.
This finding suggests emphasizing zero-shot and out-of-
distribution evaluations of models, particularly when at-
tempting to compare to human performance, to avoid over-
stating the capabilities of machine learning systems due to
misleading comparisons.
3.4. Multi-lingual Speech Recognition
In order to compare to prior work on multilingual speech
recognition, we report results on two low-data benchmarks:
Multilingual LibriSpeech (MLS) (Pratap et al., 2020b) and
VoxPopuli (Wang et al., 2021) in Table 3.
Whisper performs well on Multilingual LibriSpeech, out-
performing XLS-R (Babu et al., 2021), mSLAM (Bapna
剩余27页未读,继续阅读
2022-08-03 上传
点击了解资源详情
2024-05-17 上传
点击了解资源详情
点击了解资源详情
241 浏览量

幽雨雨幽
- 粉丝: 5242
- 资源: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- ActionScript 3.0 Cookbook 中文版.pdf
- iBATIS in Action
- crc_explain 关于crc校验说明
- 软硬件开发人员的简历的模板
- 全国计算机等级考试网络三级详细资源
- S3C2410A_manual_r10.pdf
- 计算机操作系统(汤子瀛)习题答案
- 《实战C#.NET编程-Spring.NET & NHibernate从入门到精通》pdf部分
- GCC 入门剖析以及嵌入式汇编
- PMP项目管理师英文选择题试题一
- .NET中对文件的操作
- 使用pager-taglib实现分页显示的详细步骤
- CSAI信息系统项目管理师考试辅导模拟试题二(有答案)
- Apchche+php+Mysql+jsp+tomcat.WEB环境设置指南
- jmail 4.3使用方法PDF文档
- GDB Quick Reference Card
