DOA估计:古典与现代方法探索
"Classical and Modern DOA Estimation"
本书《Classical and Modern DOA Estimation》是2009年由Elsevier出版的一部专注于方向-of-arrival (DOA)估计技术的专业文献,它集合了在Elsevier数据上发表的相关论文,为读者提供了丰富的DOA估计算法和理论知识。DOA估计是信号处理领域的一个关键问题,特别是在无线通信、雷达系统和声学传感器网络中,用于确定信号源相对于接收阵列的方向。
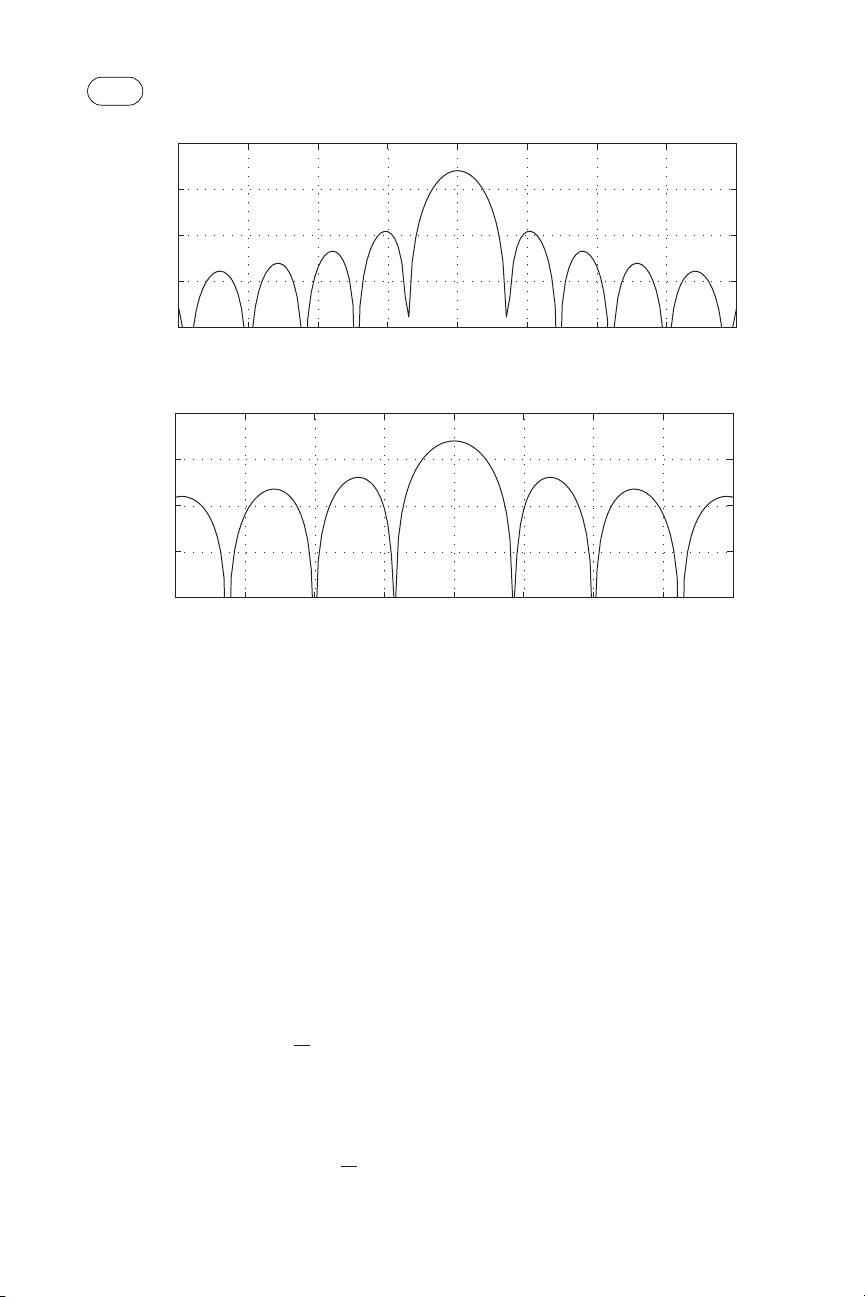
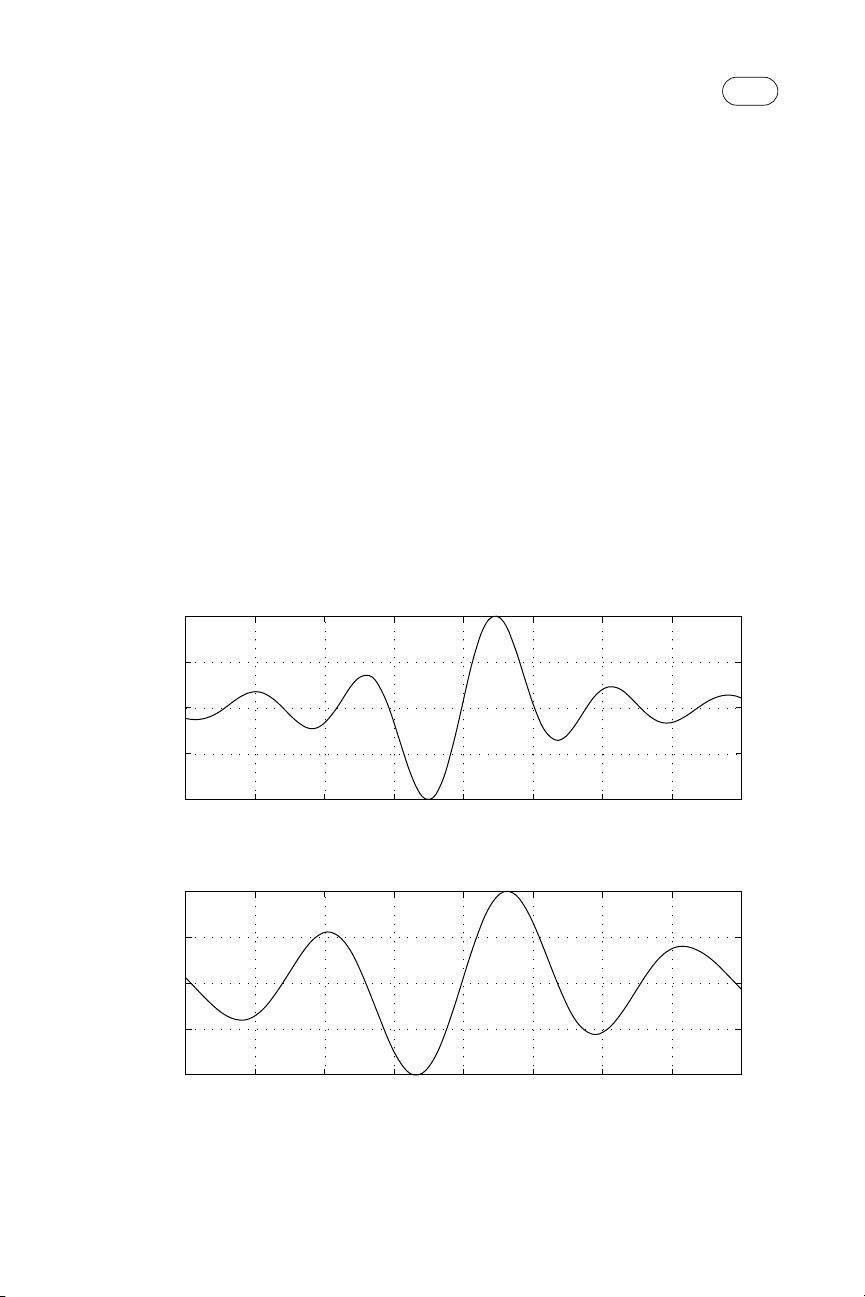
DOA估计算法主要包括经典方法和现代方法。经典方法通常涉及数学统计和矩阵理论,如最大似然(ML)估计、最小二乘(LS)估计和音乐算法(MUSIC)。这些方法基于阵列信号处理,利用多通道接收信号之间的相位差来确定信号源的方向。例如,最大似然估计通过寻找最可能产生观测数据的信号源方向来估计DOA,而音乐算法则利用特征值分解来识别噪声子空间,从而估计信号源的方向。
现代DOA估计技术则涵盖了更广泛的领域,包括阵列信号处理的高级理论、机器学习和人工智能算法。例如,基于稀疏表示的DOA估计利用信号的稀疏特性来提高估计精度,这在噪声环境复杂的情况下特别有效。此外,现代方法还包括利用神经网络和深度学习的方法,通过训练模型来直接预测DOA,这种方法可以自动学习信号特性和阵列配置的复杂关系,进一步提升DOA估计的性能。
书中可能还探讨了阵列几何结构的影响,如线性阵列、圆阵列和随机分布阵列等,以及各种阵列处理技术,如波束形成、自适应滤波和空间谱估计。每种阵列结构都有其特定的优势和适用场景,如线性阵列适用于平面波入射,而圆阵列可以提供全方位的覆盖。
除了理论分析外,本书可能还包含实际应用案例和实验结果,以展示不同DOA估计方法在真实世界情境中的表现。这有助于读者理解如何选择合适的DOA估计技术,并将其应用于实际系统设计中。
此外,版权信息提醒读者,本书内容受到严格保护,未经许可不得复制或传播。如果需要使用其中的内容,应事先获得出版社的授权。读者可以通过Elsevier的官方网站获取权限申请相关信息。
《Classical and Modern DOA Estimation》是了解和深入研究DOA估计技术的重要参考资料,无论对于学术研究者还是工程实践者,都能从中获益良多。

Section | 1.2 Problem Formulation
3
where x
pb
(t) is the vector of the received passband signals and τ
m
are the
propagation delays determined by the direction of the source relative to the
array. For example, in the case of a linear array
τ
m
=τ
0
−(d
m
/c) sin θ (1.2)
where τ
0
is the propagation delay from the emitter to a reference point on the
array, d
m
are the distances of the array elements from that reference point, c is
the speed of light, and θ is the emitter direction measured relative to the line
perpendicular to the array. Without loss of generality we can assume that τ
0
=0.
(This is equivalent to defining s(t) as the baseband signal at the reference point
of the receiver array, not as the source signal.) Thus, in the rest of this chapter
we will assume that
τ
m
=−(d
m
/c) sin θ (1.3)
We note that the contribution of τ
0
to the phase e
−jw
c
τ
0
introduces an unknown
random phase term that is common to the elements of the received signal vector.
Because of this phase term, all direction-finding methods must be designed to
be invariant to a common additive phase.
After transforming the passband signals to baseband, we have
x(t) =
⎡
⎢
⎢
⎢
⎣
s(t −τ
1
)e
jw
c
τ
1
s(t −τ
2
)e
jw
c
τ
2
.
.
.
s(t −τ
M
)e
jw
c
τ
M
⎤
⎥
⎥
⎥
⎦
(1.4)
where x(t) is the vector of received baseband signals.
Let D denote the aperture of the array in wavelengths λ. Then Dλ/c =D/f
c
is the time it takes the signal to propagate over the array, so that τ
m
< D/f
c
.It
follows that, if the signal bandwidth is B and B f
c
/D, s(t −τ
m
) ≈s(t). The
condition B f
c
/D or B/f
c
1/D implies that s(t) is a narrowband signal. It
follows that, under the narrowband assumption, the received baseband signal
can be written as
x(t) =s(t)
⎡
⎢
⎢
⎢
⎣
e
jw
c
τ
1
e
jw
c
τ
2
.
.
.
e
jw
c
τ
M
⎤
⎥
⎥
⎥
⎦
(1.5)
For this reason, we define the so-called “array manifold” a(θ), as the array
response to a unit amplitude signal (i.e., the case where s(t) =1).
a(θ) =
⎡
⎢
⎢
⎢
⎣
exp{ j2πd
1
sin θ/λ}
exp{ j2πd
2
sin θ/λ}
.
.
.
exp{ j2πd
M
sin θ/λ}
⎤
⎥
⎥
⎥
⎦
(1.6)


剩余435页未读,继续阅读
173 浏览量
138 浏览量
133 浏览量
298 浏览量
250 浏览量
2024-11-01 上传
110 浏览量
181 浏览量
367 浏览量









