深度生成模型:构建能想象与推理的机器
需积分: 10 19 浏览量
更新于2024-07-20
收藏 12.49MB PDF 举报
Shakir Mohamed是一位在机器学习领域有着深厚影响力的专家,他在2016年的Deep Learning Summer School上分享了主题为“Building Machines that Imagine and Reason”的演讲。该演讲探讨了深度生成模型(Deep Generative Models)的基本原则及其广泛应用。深度生成模型是一种解决无监督学习问题的关键工具,这种类型的机器学习系统能够在没有标签数据的情况下揭示隐藏的结构。由于它们具备生成能力,这些模型能够构建一个丰富的内在世界想象,这使得机器能够探索数据变化、理解世界的结构和行为,并最终支持决策制定。
在这次演讲中,Shakir强调了如何利用深度生成模型来构建能够想象的机器学习系统。他解释了这些模型是如何通过概率推断实现的,例如通过生成对抗网络(GANs)、变分自编码器(VAEs)或自注意力机制等技术,使机器能够从随机噪声中生成逼真的样本。深度生成模型在多个实际场景中发挥着重要作用,如密度估计、图像去噪和生成式对抗网络的艺术创作等。
深度生成模型的另一个关键应用是用于生成式对话系统,通过模拟人类对话的模式来提供更自然、连贯的交流。此外,它们还可以用于推荐系统,通过分析用户的行为模式预测潜在的兴趣,并据此做出个性化推荐。在强化学习中,生成模型也用于模拟环境,帮助智能体在复杂环境中进行策略规划和决策。
Shakir还讨论了深度生成模型在科学发现、自然语言处理和计算机视觉中的潜在作用,特别是在理解和生成复杂的数据分布方面。他可能提到了如何利用这些模型进行序列建模,例如文本生成或者音乐创作,以及如何通过生成模型来提升模型的泛化能力和适应性。
Shakir Mohamed的演讲不仅深入剖析了深度生成模型的核心原理,还展示了其在实际问题解决中的广泛实用性。听众不仅可以了解到如何构建具备想象力的机器,还能掌握如何将这些模型融入到各种应用场景中,以推动人工智能的发展并解决现实世界中的挑战。

Machines that Imagine and Reason
15
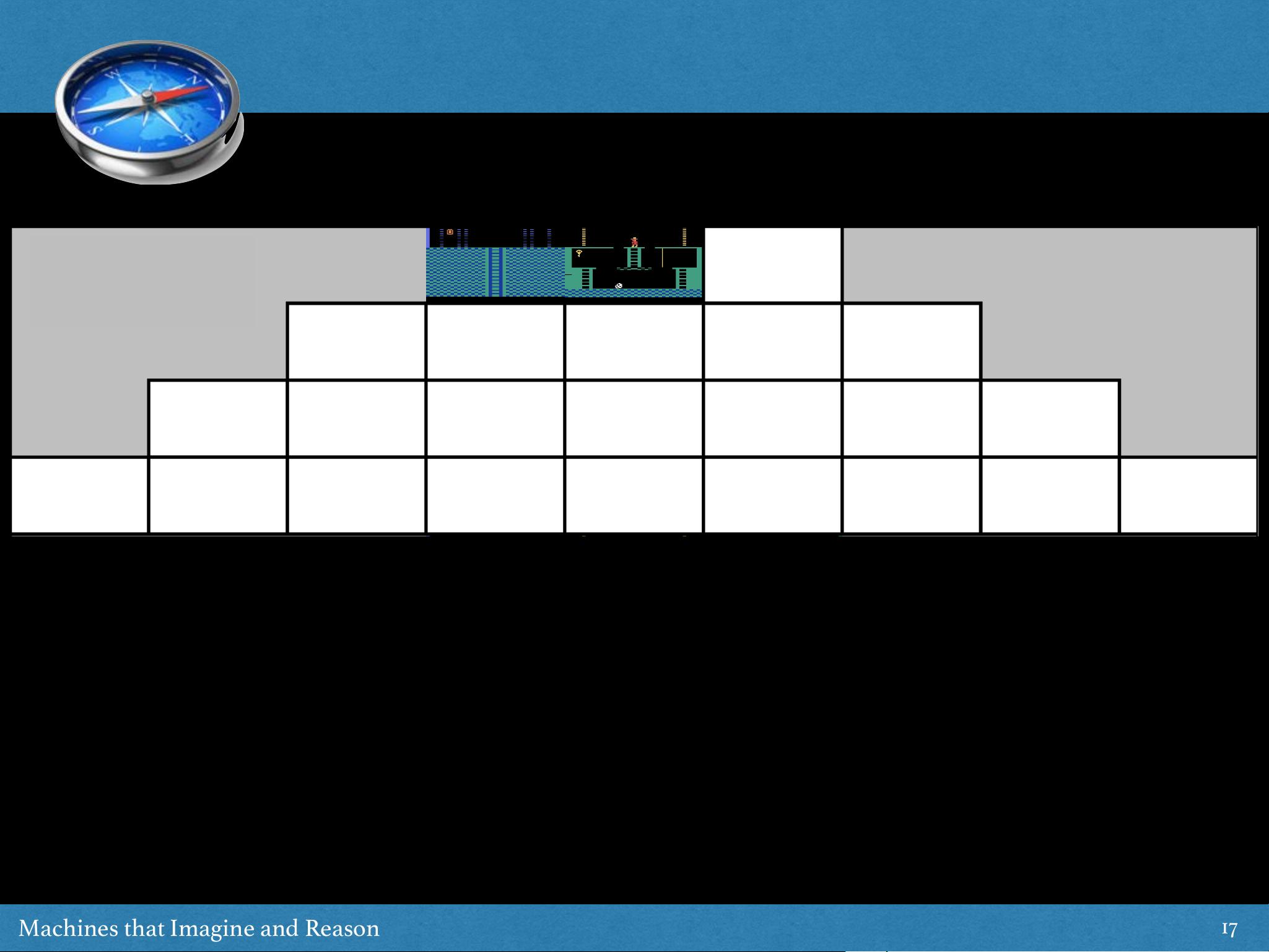
(a) (b) (c)
Figure 2: High-resolution screenshots of the Labyrinth environments.
(a)
Forage and Avoid showing
the apples (positive rewards) and lemons (negative rewards).
(b)
Double T-maze showing cues at
the turning points.
(c)
Top view of a Double T-maze configuration. The cues indicate the reward is
located at the top left.
state was discarded. The
k
-nearest-neighbour lookups used
k = 50
. The discount rate was set to
=0.99
. Exploration is achieved by using an
✏
-greedy policy with
✏ =0.005
. As a baseline, we
used A3C [
22
]. Labyrinth levels have deterministic transitions and rewards, but the initial location
and facing direction are randomised, and the environment is much richer, being 3-dimensional. For
this reason, unlike Atari, experiments on Labyrinth encounter very few exact matches in the buffers
of Q
EC
-values; less than 0.1% in all three levels.
Each level is progressively more difficult. The first level, called Forage, requires the agent to collect
apples as quickly as possible by walking through them. Each apple provides a reward of 1. A simple
policy of turning until an apple is seen and then moving towards it suffices here. Figure 1 shows that
the episodic controller found an apple seeking policy very quickly. Eventually A3C caught up, and
final outperforms the episodic controller with a more efficient strategy for picking up apples.
The second level, called Forage and Avoid involves collecting apples, which provide a reward of 1,
while avoiding lemons which incur a reward of
1
. The level is depicted in Figure 2(a). This level
requires only a slightly more complicated policy then Forage (same policy plus avoid lemons) yet
A3C took over 40 million steps to the same performance that episodic control attained in fewer than
3 million frames.
The third level, called Double-T-Maze, requires the agent to walk in a maze with four ends (a map
is shown in Figure 2(c)) one of the ends contains an apple, while the other three contain lemons.
At each intersection the agent is presented with a colour cue that indicates the direction in which
the apple is located (see Figure 2(b)): left, if red, or right, if green. If the agent walks through a
lemon it incurs a reward of
1
. However, if it walks through the apple, it receives a reward of
1
, is
teleported back to the starting position and the location of the apple is resampled. The duration of an
episode is limited to 1 minute in which it can reach the apple multiple times if it solves the task fast
enough. Double-T-Maze is a difficult RL problem: rewards are sparse. In fact, A3C never achieved
an expected reward above zero. Due to the sparse reward nature of the Double T-Maze level, A3C did
not update the policy strongly enough in the few instances in which a reward is encountered through
random diffusion in the state space. In contrast, the episodic controller exhibited behaviour akin to
one-shot learning on these instances, and was able to learn from the very few episodes that contain
any rewards different from zero. This allowed the episodic controller to observe between 20 and 30
million frames to learn a policy with positive expected reward, while the parametric policies never
learnt a policy with expected reward higher than zero. In this case, episodic control thrived in sparse
reward environment as it rapidly latched onto an effective strategy.
4.3 Effect of number of nearest neighbours on final score
Finally, we compared the effect of varying
k
(the number of nearest neighbours) on both Labyrinth
and Atari tasks using VAE features. In our experiments above, we noticed that on Atari re-visiting
the same state was common, and that random projections typically performed the same or better
than VAE features. One further interesting feature is that the learnt VAEs on Atari games do not
yield a higher score as the number of neighbours increases, except on one game, Q*bert, where
VAEs perform reasonably well (see Figure 3a). On Labyrinth levels, we observed that the VAEs
outperformed random projections and the agent rarely encountered the same state more than once.
Interestingly for this case, Figure 3b shows that increasing the number of nearest neighbours has a
7
Representation Learning for Control
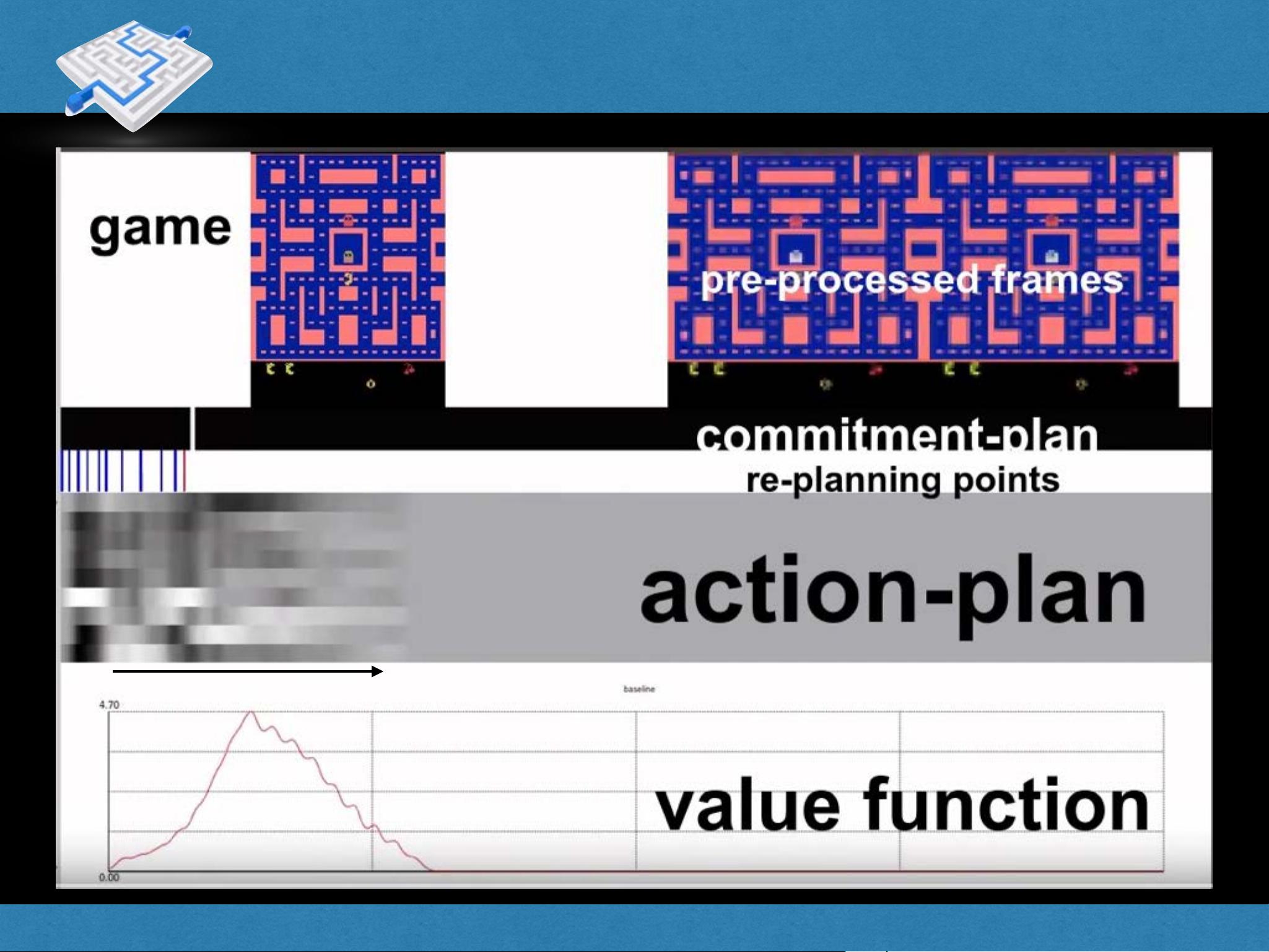
剩余88页未读,继续阅读
1422 浏览量
110 浏览量
2021-03-31 上传
136 浏览量
229 浏览量
2021-06-01 上传
2021-06-01 上传
点击了解资源详情
2025-03-06 上传

蓝魅派
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
