Python KMeans算法详解:从概念到实践
158 浏览量
更新于2024-08-31
收藏 157KB PDF 举报
"深入解析Python KMeans算法,包括无监督学习概念、聚类目的及KMeans算法的基本原理。本文提供了一组二维数据点作为示例,解释了如何通过欧式距离找到簇中心。"
KMeans算法是一种广泛应用的无监督学习方法,主要用于数据的聚类。在无监督学习中,我们没有预先定义的类别标签,目标是从数据的内在结构中学习模式。聚类是无监督学习的一种,它的任务是将相似的数据分到同一组,即“簇”。
KMeans算法的核心思想是迭代寻找簇的中心(质心),并将数据点分配给最近的质心所在的簇。以下是对KMeans算法步骤的详细解释:
1. 初始化:选择K个初始质心。这通常可以通过随机选择K个数据点来实现。在本例中,我们假设K=4。
2. 分配阶段:计算每个数据点与所有质心的距离,使用的是欧式距离。欧式距离是两点之间的直线距离,公式为:`d = sqrt(sum((x_i - y_i)^2))`,其中x和y是两个点的坐标,i是坐标轴索引。
3. 更新质心:一旦所有数据点被分配到对应的簇,就更新每个簇的质心。质心是该簇内所有数据点坐标平均值的位置,即簇内所有点的均值向量。
4. 迭代:重复分配和更新质心的过程,直到质心不再显著移动(达到收敛条件),或者达到预设的最大迭代次数。
在实际应用中,选择合适的K值是关键,可以使用肘部法则或者轮廓系数等方法来确定最佳的簇数。肘部法则通过观察随着K增加,簇内的平方误差总和的变化趋势,选择“肘部”处的K值,即增加簇的数量带来的改善效果开始显著减小的点。
对于给定的二维数据点,KMeans算法会迭代地更新质心,最终形成4个簇。在每个迭代过程中,数据点将根据与当前质心的距离重新分配,直到质心稳定,即每个簇内的点相对固定,且簇间距离最大化。
需要注意的是,KMeans算法有一些局限性,如对初始质心敏感可能导致不同的结果,对异常值敏感,以及对非凸形状的簇识别能力有限。此外,KMeans假设簇是球形的,并且大小一致,对于复杂的数据分布可能不适用。因此,在实际应用中,可能需要结合其他聚类算法或者预处理步骤来优化结果。
python Kmeans算法原理深入解析算法原理深入解析
主要介绍了python Kmeans算法深入解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定
的参考学习价值,需要的朋友可以参考下
一一. 概述概述
首先需要先介绍一下无监督学习,所谓无监督学习,就是训练样本中的标记信息是位置的,目标是通过对无标记训练样本的学
习来揭示数据的内在性质以及规律。通俗得说,就是根据数据的一些内在性质,找出其内在的规律。而这一类算法,应用最为
广泛的就是“聚类”。
聚类算法可以对数据进行数据归约,即在尽可能保证数据完整的前提下,减少数据的量级,以便后续处理。也可以对聚类数据
结果直接应用或分析。
而Kmeans 算法可以说是聚类算法里面较为基础的一种算法。
二二. 从样例开始从样例开始
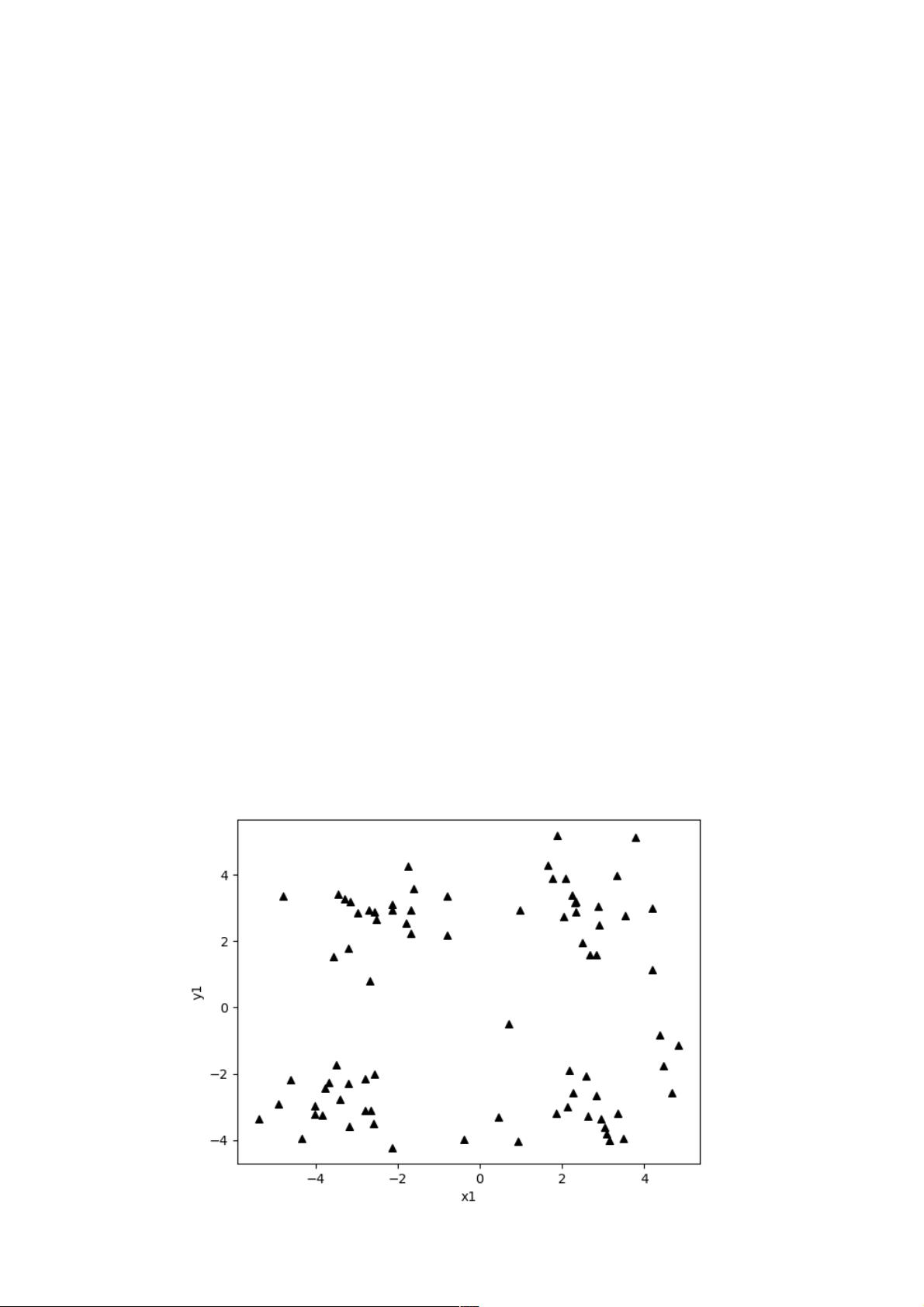
我们现在在二维平面上有这样一些点
x y
1.658985 4.285136
-3.453687 3.424321
4.838138 -1.151539
-5.379713 -3.362104
0.972564 2.924086
-3.567919 1.531611
0.450614 -3.302219
-3.487105 -1.724432
2.668759 1.594842
-3.156485 3.191137
3.165506 -3.999838
-2.786837 -3.099354
4.208187 2.984927
-2.123337 2.943366
0.704199 -0.479481
-0.392370 -3.963704
2.831667 1.574018
-0.790153 3.343144
2.943496 -3.357075
...
它在二维平面上的分布大概是这样的:
好,这些点看起来隐约分成4个“簇”,那么我们可以假定它就是要分成4个“簇”。(虽然我们可以“看”出来是要分成4个“簇”,但
实际上也可以分成其他个,比如说5个。)这里分成“4个簇“是我们看出来的。而在实际应用中其实应该由机器算得,下面也会
下载后可阅读完整内容,剩余6页未读,立即下载
2020-12-25 上传
2010-04-14 上传
点击了解资源详情
2021-08-11 上传
2022-12-24 上传
2015-09-01 上传
2021-10-11 上传
点击了解资源详情

weixin_38526421
- 粉丝: 5
- 资源: 985
 我的内容管理
展开
我的内容管理
展开







最新资源
- 人工智能基础实验.zip
- chkcfg-开源
- Amaterasu Tool-开源
- twitter-application-only-auth:Twitter仅限应用程序身份验证的简单Python实现。
- 第一个项目:shoppingmall
- webpage-test
- JTextComponent.rar_Applet_Java_
- 人工智能原理课程实验1,numpy实现Lenet5,im2col方法实现的.zip
- PyPI 官网下载 | vittles-0.17-py3-none-any.whl
- Real-World-JavaScript-Pro-Level-Techniques-for-Entry-Level-Developers-V-:实际JavaScript的代码存储库
- Sitecore.Support.96670:修补程序解决了以下问题:选中“相关项目”复选框时,并非所有子项目都会发布,
- BioGRID-PPI:生物二进制PPI数据集和BioGRID的处理
- ownership-status:所有权状态页
- DMXOPL:用于末日和源端口的YMF262增强的FM补丁集
- VideoCapture.rar_视频捕捉/采集_Visual_C++_
- trd_mc:一个简单的蒙特卡洛TPX响应仿真引擎。专为ROOT互动模式
