贝叶斯算法在新闻分类中的应用与实现
需积分: 14 24 浏览量
更新于2024-08-04
收藏 441KB PDF 举报
"该资源为基于贝叶斯的新闻分类任务识别系统的设计与实现的代码大全,涵盖了新闻数据预处理、特征提取、分类过程及程序代码,并提供了运行结果的分析。"
在新闻分类任务中,贝叶斯算法是一种常用的方法。贝叶斯分类基于概率论,通过计算每个类别的先验概率和给定特征条件下类别的后验概率来预测新样本的类别。在这个系统设计中,主要涉及以下知识点:
1. **预处理**:预处理是文本分类的重要步骤,包括去除停用词(如“的”、“是”等常见但对分类意义不大的词汇)、词干提取和词形还原等。目的是减少噪声,提高分类效果。
2. **特征表示**:通常采用TF-IDF(Term Frequency-Inverse Document Frequency)和词袋模型(Bag-of-Words Model)。TF-IDF是一种统计方法,用于衡量一个词对于文档集合或者语料库中的一个文档的重要性。词袋模型忽略词序和语法结构,仅关注词频,将文本转化为向量表示。
3. **分类器选择**:使用贝叶斯算法作为分类器。朴素贝叶斯分类器假设特征之间相互独立,简化了计算,使得在大数据集上运行高效。尽管这个假设在实际文本中往往不成立,但在许多情况下仍能给出良好结果。
4. **硬件与软件环境**:实验基于Intel Core i5 8th Gen的硬件和Python编程环境。Python因其丰富的库支持(如nltk、sklearn等)在自然语言处理领域广泛应用。
5. **数据集**:数据集包含Category(类别)、Theme(主题)、URL(链接)和Content(内容)四个字段。分类任务主要依据Content字段进行,而Theme和URL在本任务中未被利用。
6. **特征提取**:通过提取关键词作为特征,减少数据维度,同时保留关键信息。这一步骤有助于提高分类器的效率和准确性。
7. **分类过程**:在词袋模型基础上,利用TF-IDF进一步增强特征的区分性。TF-IDF考虑了词在整个文档集合中的稀有程度,减少了常见词的影响。
8. **程序代码**:代码部分应包含了数据预处理、特征提取、模型训练和预测等关键模块,并且附带注释以解释各部分功能。
9. **运行结果分析**:这部分内容会展示模型的性能指标,如准确率、召回率、F1分数等,以及可能的错误分析和优化方向。
这个资源对于学习和实践贝叶斯新闻分类是一个宝贵的参考资料,通过理解和应用其中的方法,可以深入理解文本分类的流程和技巧。
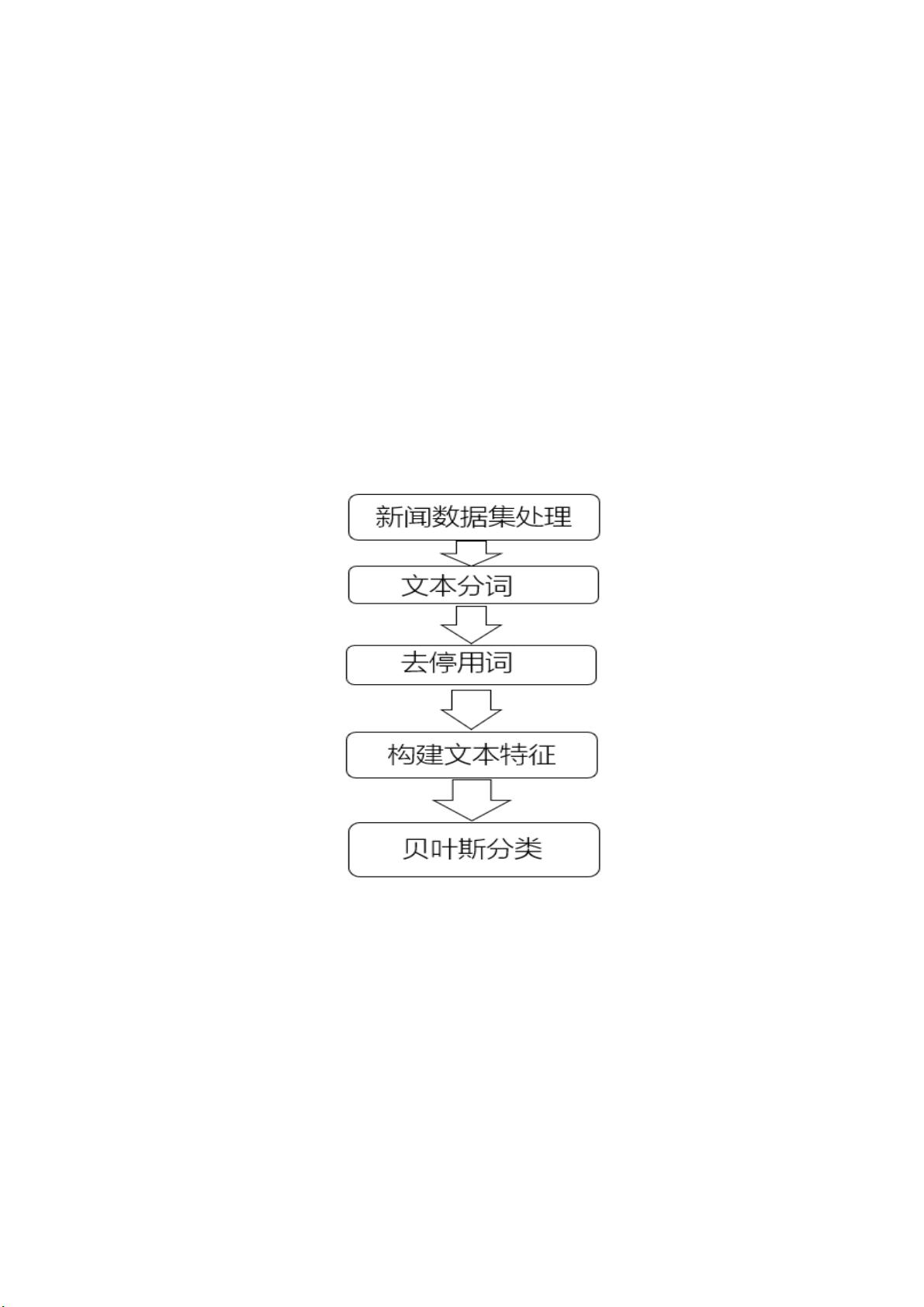
基于贝叶斯新闻分类任务识别系统的设计与实现
1.1 贝叶斯新闻分类任务的主要研究内容
(1)工作的主要描述
建立新闻文章分类模型,抓取的新闻数据,需要我们对文本数据进行很多
预处理才能使用,通常我们处理的都是词而不是一篇文章,停用词会对结果产生
不好的影响,所以一定得把他们去剔除掉,使用 TF-IDF 和词袋模型构建特征,
基于贝叶斯算法来完成分类任务。
(2)系统流程图
1.2 题目研究的工作基础或实验条件
(1)硬件环境(intel CORE i5 8th Gen)
(2)软件环境(python 语言)
1.3 数据集描述
下载后可阅读完整内容,剩余6页未读,立即下载
2022-06-20 上传
2022-05-13 上传
2021-09-24 上传
2021-09-24 上传
2021-09-25 上传
2022-06-29 上传
2021-09-25 上传
2023-02-22 上传
2021-07-15 上传

李逍遥敲代码
- 粉丝: 2996
- 资源: 277
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
