
python数据可视化之数据可视化之Seaborn(三)(三)
写在开头:今天开始分享一下seaborn对于数据集分布的设计。该文章主要借鉴seaborn文档,会附在结尾链接。
前文回顾前文回顾:
第一节分享了Seaborn绘图的整体颜色与风格比例调控,可点击链接查看。
python数据可视化之Seaborn(一)
第二节分享了连续、分类、离散数据的绘图颜色的方法,可点击链接查看。
python数据可视化之Seaborn(二)
Seaborn可视化内容安排可视化内容安排
在Seaborn的学习中安排如下,
一、画风设置一、画风设置:会简单介绍一下绘图风格(一)与颜色风格(二)的设置;
二、绘图技巧二、绘图技巧:这里会介绍数据集(三)、相关数据(四)、分类数据(五)、线性关系(六)可视化的相关内容;
三、结构网络三、结构网络:本节主要介绍数据识别结构网络的绘图(七)。
二、二、Seaborn绘图技巧绘图技巧
数据集分布可视化数据集分布可视化
当我们处理数据集数据的时候,我们往往需要查看数据的分布情况,判断其属于哪种分布,或者判断其是否正态, 因为在有
些统计模型下需要正态的假定,本章我们就会对单变量数据的分布直方图、核密度图,双变量分布矩阵图进行和一些个性化设
置进行分享。
绘制单变量分布绘制单变量分布
在绘制图之前我们先载入本章需要的包,
import numpy as np
import pandas as pd
from scipy import stats, integrate
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
np.random.seed(42)
直方图直方图
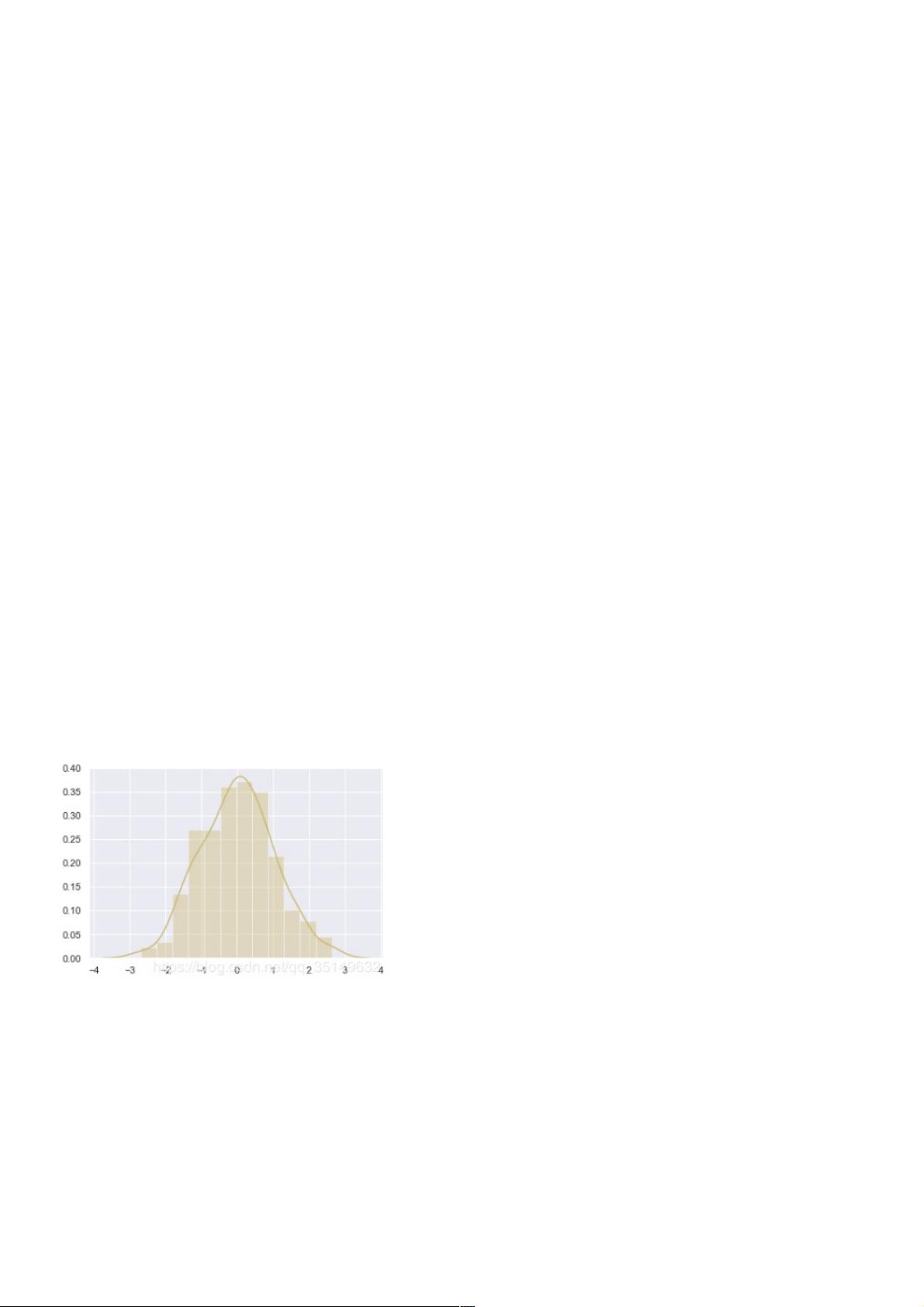
在seaborn中,对于单变量数据分布方法观察最便捷的方式就是绘制直方图和核密度估计,使用的就是distplot()函数,直方图
其实就是根据数据的大小,将数据分成一段一段的矩形,来观察数据的分布情况。
sns.set_style("darkgrid")
x = np.random.normal(size=200)
sns.distplot(x, color='y')
我们可以移除核密度估计线,在轴上加上垂直小标签来表示数据所在的位置,同样还可以调整矩阵的数量,来对图像进行重新
绘制,
sns.distplot(x, kde=False, rug=True, bins=20)
下载后可阅读完整内容,剩余6页未读,立即下载

weixin_38506713
- 粉丝: 4
- 资源: 907
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


