GPU的过度订阅命令队列
需积分: 5 89 浏览量
更新于2024-08-03
收藏 1.16MB PDF 举报
" Oversubscribed Command Queues in GPUs 指的是随着GPU变得越来越强大,提供了更多的并行执行单元,单个内核无法充分利用所有可用资源。因此,GPU应用程序开始使用细粒度的异步内核,它们可以并行执行,展现出更高的并发性。HSA(异构系统架构)和Compute Unified Device Architecture规范支持通过多个命令队列来并发启动内核。"
正文:
在现代计算机科学中,图形处理单元(GPU)的角色已经远远超出了传统的图形渲染,它们现在被广泛用于高性能计算、深度学习和大规模数据处理等任务。随着技术的进步,GPU的规模不断增大,包含的执行单元数量显著增加。这使得单个计算内核(kernel)无法有效利用所有的硬件资源,从而导致性能浪费。
"Oversubscribed Command Queues in GPUs"的概念应运而生,以解决这个问题。 Oversubscribed 在这里意味着命令队列的使用超过了其理论上的最大负载,即GPU的并行执行能力被超额预定。通过创建和管理多个命令队列,GPU可以同时处理更多的任务,提高资源利用率,实现更高程度的并发执行。这种方式被称为细粒度异步计算,它允许开发者将大任务分解为许多小的内核,这些内核可以并行运行,每个都在不同的命令队列上。
HSA(异构系统架构)和CUDA(Compute Unified Device Architecture)是两种主要的编程模型,它们支持这种并发内核启动。HSA允许CPU和GPU之间的无缝协作,开发者可以创建多个命令队列,以便在GPU的不同部分并行执行任务,提高效率。CUDA则通过CUDA流(stream)来实现类似的功能,每个流都可以包含一系列独立的命令,它们可以并发地在GPU上执行,无需等待前一个流完成。
在实际应用中,使用oversubscribed命令队列能够有效地利用GPU的并行性,提高计算效率。例如,在深度学习中,模型的训练可能涉及大量矩阵运算和卷积,这些操作可以被分解成多个小任务,放入不同的命令队列中,从而实现并行化。此外,对于大数据分析任务,多个命令队列可以同时处理不同的数据子集,加快整体处理速度。
然而,过度订阅命令队列也带来了一些挑战,比如内存管理和同步问题。如果不同队列之间的资源分配不当,可能会导致竞争条件,降低性能。因此,优化GPU程序时,开发者需要精心设计任务调度策略,确保数据一致性,并避免内存冲突。
"Oversubscribed Command Queues in GPUs"是一种有效利用现代GPU并行处理能力的技术,它通过多命令队列实现了细粒度的异步计算,提高了应用程序的性能。为了充分利用这一特性,开发者需要深入理解GPU架构,掌握相应的编程模型,并能有效地进行任务分解和调度。随着GPU技术的持续发展,这一领域将继续提供新的优化机会和挑战。
Oversubscribed Command Queues in GPUs
GPGPU’18, Vosendorf, Austria
3
(HSA queues) to launch kernels. However, it is challenging for the
GPU to locate all outstanding works on these queues when it can
only monitor a fixed number of queues at a time. Therefore, the
GPU periodically swaps different queues into the available
hardware queue slots (hereafter referred as hardware queues) and
processes ready tasks on the monitored queues. To ensure all
queues are eventually serviced, the hardware will swap in and out
queues at regular intervals, called the scheduling quantum.
When the number of allocated HSA queues is greater than the
number of hardware queues, the GPU wastes significant time
rotating between all allocated queues in search of ready tasks.
Furthermore, barrier packets that handle task dependencies can
block queues while waiting for prior tasks to complete. In this
situation, it is important for the GPU to choose a scheduling policy
that prioritizes queues having ready tasks. In this work, combining
round-robin and priority-based scheduling with various queue
mapping and unmapping criteria, we evaluate five different
scheduling policies (three round-robin and two priority-based).
3. GPU Command Queue Organization
Figure 2 shows the GPU queue scheduling and task dispatching
mechanism used in this paper. The GPU device driver is
responsible for creating queues in the system memory. The driver
also creates a queue list that contains the queue descriptors of all
the queues created by the application. Queue descriptors have all
the necessary information to access HSA queues, such as the
pointer to the base address of a queue. This queue list is passed to
the GPU hardware scheduler during initialization phase. Although
the queue list is read by the hardware scheduler, it is modified only
by the device driver. The hardware scheduler maps and unmaps
queues from the queue list to the hardware list stored inside the
packet processor at each scheduling quantum. The number of
entries in the hardware list is limited and each entry in the hardware
list corresponds to the HSA queue mapped to a hardware queue.
The packet processor monitors these hardware queues, processes
both kernel dispatch and barrier HSA packets, resolves
dependencies expressed by barrier packets and forwards ready
tasks to the dispatcher. The dispatcher then launches these tasks on
the shaders in work-group granularity.
When the HSA queues are oversubscribed, the hardware
scheduler unmaps a queue from the hardware list and maps a new
queue from the queue list. Our baseline hardware scheduler selects
a new queue to be mapped at each scheduling quantum based on a
round-robin policy. However, the newly selected queue may not
have ready tasks, resulting in idling GPU resources. Priority-based
queue scheduling techniques tries to reduce idling by intelligently
mapping a queue with ready tasks. The next section discusses this
priority-based queue scheduling in detail.
4. Priority-Based Queue Scheduling
While HSA can expose more task level concurrency to the GPU, it
shifts the burden of task scheduling to the hardware. In a complex
task graph with hundreds of interdependent tasks, many task queues
can become unblocked at any given time. From a data dependency
standpoint, the task scheduler is free to launch any ready task.
However, a naïve policy may not be able to achieve efficient use of
resources and may leave tasks blocked for long periods of time.
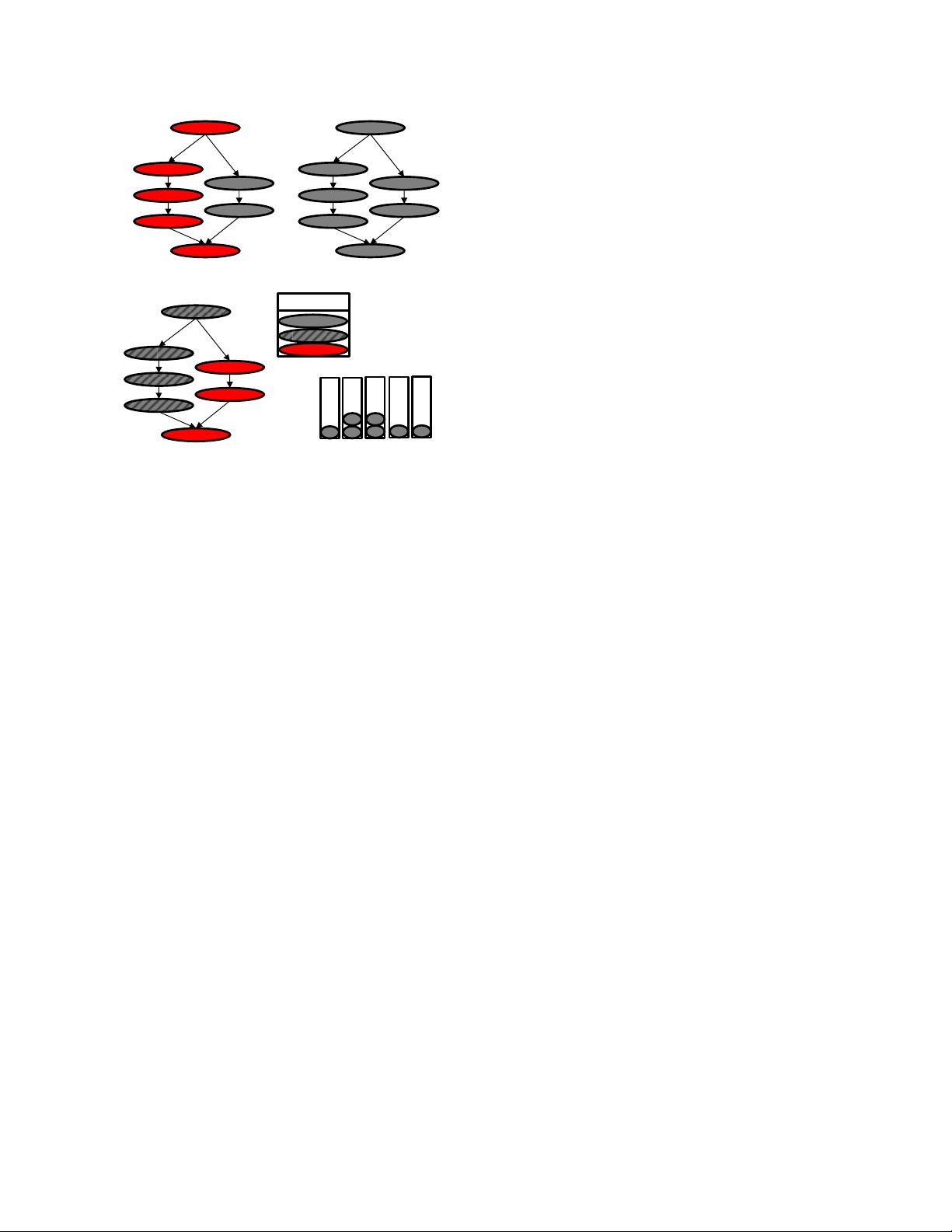
Figure 3 explains the deficiency of the naïve scheduler. Tasks
on the initial critical path of execution are marked in red in Figure
3 (a). After task A is executed, both tasks B and C are ready to
execute. A naïve scheduler could pick either of these two tasks, but
executing task B first is the better scheduling decision because task
B is on the critical path. Task C can be delayed, but Figure 3 (b)
shows delaying the execution of task C until tasks B, D, and F
complete, puts task C on the critical path. A more informed
scheduler would have executed task C before task F.
To make better decisions, a task priority-aware scheduler is
needed. Many techniques have been proposed in literature to
prioritize tasks [15][54]. One such technique is the Heterogeneous
Earliest-Finish-Time (HEFT) algorithm proposed by Topçuoğlu et
al. [54] that computes upward ranks of the tasks and selects the task
with highest upward rank for scheduling. A task’s upward rank is
its distance from an exit node. Figure 3 (c) shows the same task
graph from Figure 3 (a) with each task annotated with their upward
rank. The ranking uses HEFT algorithm but assumes equal
computation time for all tasks. Since the tasks are now annotated
with priorities, a scheduler that is aware of the priorities can make
informed scheduling decisions. For example, after task A is
completed, priority-based scheduler will choose task B to be
scheduled because the rank of task B (rank 4) is higher than task C
(rank 3). In this paper, we use this HEFT algorithm to determine
the priorities of each task.
4.1 Priority-based Hardware Scheduling in HSA
There are three challenges to implement a priority-based task
scheduler, (a) the tasks need to be annotated by a ranking algorithm,
(b) these annotations should be exposed to the scheduler, and (c)
the scheduler should be able to use these rankings when making
scheduling decisions.
Since HSA relies on queues to expose concurrency and schedule
tasks, we modified the HSA queue creation API [Figure 4], to
include a priority field. A queue priority (or rank) is a positive
integer value that can be specified at the time of queue creation and
Figure 3. Task graph execution and priorities.
Barrie
r
C
A
B
D
F
G
E
C (3)
A (5)
B (4)
D (3)
F (2)
G (1)
E (2)
C
A
B
D
F
G
E
(a)
(b)
(c)
completed
to be run
Legend
critical path
G
E
C
B
A
F
D
(d)
Q1
Q2
Q3 Q4
Q5
hsa_queue_create(gpu_agent, queue_size,
HSA_QUEUE_TYPE_SINGLE, NULL, NULL,
UINT32_MAX, UINT32_MAX, q_ptr, priority);
Figure 4. HSA API modifications. priority is added to HSA
queue create API.
剩余10页未读,继续阅读
2022-08-03 上传
2024-11-13 上传
2024-11-13 上传
2024-11-13 上传
2024-11-13 上传
2024-11-13 上传

泰勒朗斯
- 粉丝: 2419
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
