Apache Spark大数据与机器学习管道验证实践
需积分: 6 166 浏览量
更新于2024-07-17
收藏 5.13MB PDF 举报
"Apach Spark - Validating Big Data & ML Pipelines"
本PDF文档主要探讨了在Apache Spark中验证大数据和机器学习(ML)管道的设计思路及示例代码。作者Melinda Seckington Holden是一位来自Google的开发倡导者,同时也是Apache Spark的PMC成员和多个项目(包括Airflow)的贡献者。她分享了她在大数据处理、机器学习领域以及相关工具的丰富经验。
文档将涵盖以下关键知识点:
1. **验证的重要性**:在大数据和ML项目中,验证是确保数据质量和模型准确性的关键步骤。由于数据规模庞大,仅凭直觉判断“工作正常”往往是不够的,需要系统化的验证机制来检测潜在问题。
2. **假设与背景**:文档可能首先会介绍为什么企业和组织需要关注验证流程,包括避免错误数据导致的决策失误、提升数据驱动产品的可靠性等。
3. **快速了解属性测试**:属性测试是一种测试方法,它基于数据的特定属性或行为进行验证,而非具体的结果值。在大数据场景下,这种测试可以更有效地发现潜在的故障模式。
4. **数据管道验证**:文档将解释什么是数据管道验证,以及为何要为数据处理流程制定验证规则。这有助于发现数据清洗、转换和加载过程中的错误,防止错误数据进入后续分析和模型训练。
5. **构建简单的验证规则**:作者可能会分享如何在Spark中创建简单的验证规则,并指出当前实施这些规则时可能遇到的局限性。
6. **机器学习验证**:针对黑盒模型的验证是一个挑战,因为我们需要确认模型的预测是否符合预期。这部分可能涉及交叉验证、性能指标(如精度、召回率、F1分数)和模型解释性方法。
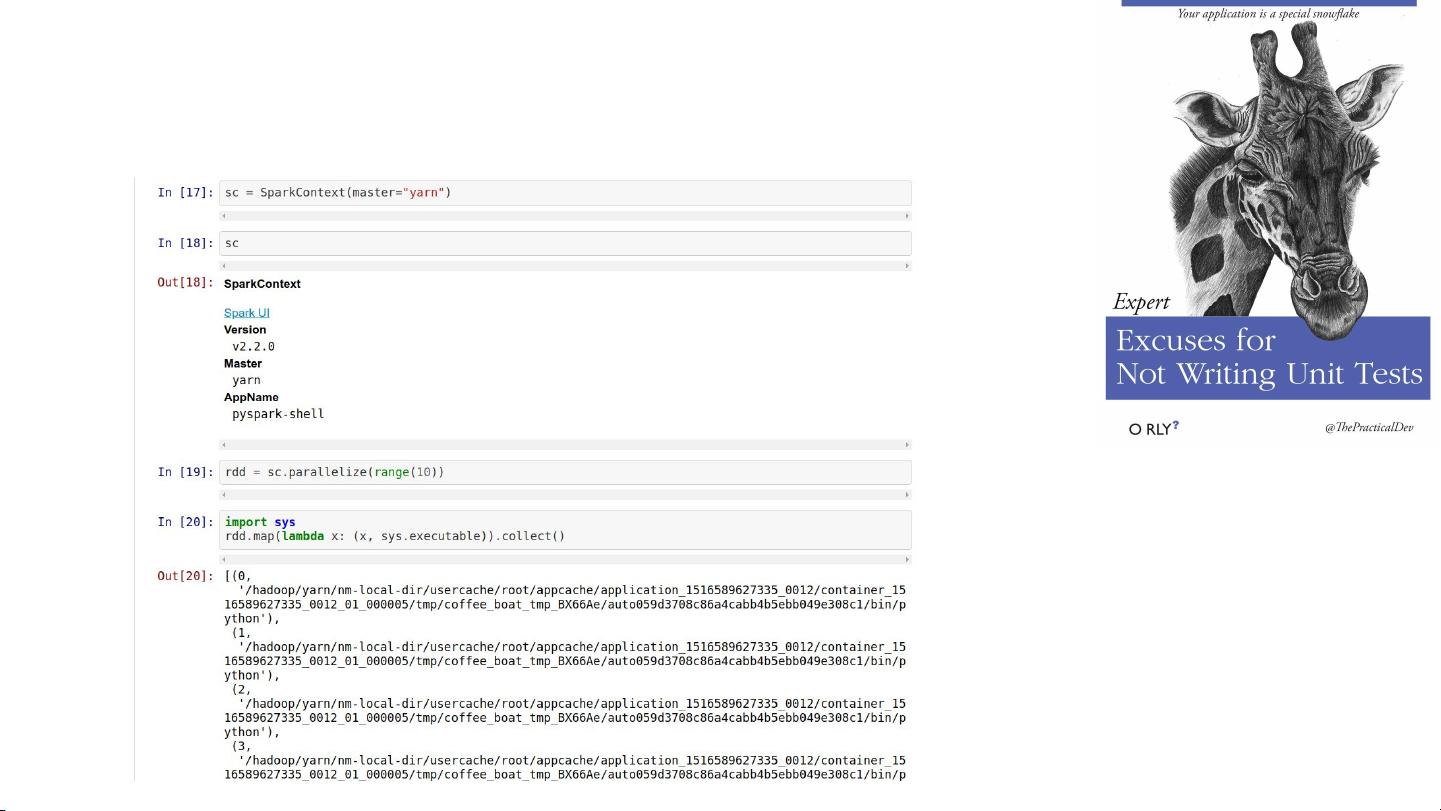
7. **实例与示例**:文档可能会包含一些生动的案例,以帮助读者更好地理解验证的实际应用,可能还会有一些有趣的图片,比如至少一张猫咪的图片,以增加阅读的趣味性。
8. **反馈与互动**:作者鼓励观众提供反馈,并提供了在线直播的代码审查和Spark相关的视频资源,供读者深入学习和交流。
通过这篇文档,读者将获得在Apache Spark环境中实现高效、可靠的数据和ML管道验证的实践指导,从而提高整个数据分析流程的稳定性和准确性。

Why don’t we test?
● It’s hard
○ Faking data, setting up integration tests
● Our tests can get too slow
○ Packaging and building scala is already sad
● It takes a lot of time
○ and people always want everything done yesterday
○ or I just want to go home see my partner
○ Etc.
● Distributed systems is particularly hard

剩余60页未读,继续阅读
2011-12-03 上传
2011-11-16 上传
2016-11-10 上传
2018-12-29 上传
2011-11-07 上传
2018-01-11 上传
2018-04-12 上传
2019-06-11 上传
2021-05-07 上传

JaneJLiu
- 粉丝: 0
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- JHU荣誉单变量微积分课程教案介绍
- Naruto爱好者必备CLI测试应用
- Android应用显示Ignaz-Taschner-Gymnasium取消课程概览
- ASP学生信息档案管理系统毕业设计及完整源码
- Java商城源码解析:酒店管理系统快速开发指南
- 构建可解析文本框:.NET 3.5中实现文本解析与验证
- Java语言打造任天堂红白机模拟器—nes4j解析
- 基于Hadoop和Hive的网络流量分析工具介绍
- Unity实现帝国象棋:从游戏到复刻
- WordPress文档嵌入插件:无需浏览器插件即可上传和显示文档
- Android开源项目精选:优秀项目篇
- 黑色设计商务酷站模板 - 网站构建新选择
- Rollup插件去除JS文件横幅:横扫许可证头
- AngularDart中Hammock服务的使用与REST API集成
- 开源AVR编程器:高效、低成本的微控制器编程解决方案
- Anya Keller 图片组合的开发部署记录
