MapReduce详解:大数据处理模型与历年气温查找示例
19 浏览量
更新于2024-08-27
2
收藏 1.32MB PDF 举报
Hadoop MapReduce是一种强大的编程模型,专为大规模数据处理设计,它将复杂的计算任务分解为map和reduce两个阶段,这两个阶段分别负责数据的预处理和结果汇总。MapReduce的核心在于其键值对处理机制,key-value的形式允许数据在不同的节点之间灵活传递和聚合。
1. **Map阶段**:
- 输入:原始数据,如NCDC的天气数据,每一行包含年份和温度,以文本格式存储。
- 处理:map函数逐行读取数据,提取关键信息(年份和温度),并转换为键值对形式,如(1950,0)、(1950,22)等。在这个过程中,map函数还需处理脏数据,确保数据质量。
- 输出:经过处理的键值对按照key进行排序,形成键值对的有序列表,例如(1949,[111,78])和(1950,[0,22,-11])。
2. **Shuffle阶段**:
- 过程:map阶段结束后,所有map任务的输出进行shuffle操作,即将同一key的所有值合并到一起,形成一个键值对列表,然后发送给reduce任务。
- 效果:键相同的值列表在reduce前已经预先聚合,减少了reduce阶段的工作量。
3. **Reduce阶段**:
- 输入:接收到map阶段的键值对列表,每个元素形式为(key, [values]),reduce函数处理这些键值对,如在天气数据例子中,找出每个key对应的最高温度。
- 输出:最终结果,如(1949,111)和(1950,22),表示各年的最高气温。
4. **分布式执行**:
- 实现:在Hadoop这样的分布式计算框架中,map和reduce操作可以使用多种编程语言实现,如Java、Python或Ruby等。
- 集群协调:整个计算过程由Hadoop集群中的节点协同完成,例如,假设处理2011-2015年天气数据分布在三个文件中,数据会被分布到集群的不同节点进行处理。
通过MapReduce模型,大规模数据的处理变得更加高效和易于管理,通过分工和协作,降低了单台机器的负载,并充分利用集群资源。这是Hadoop MapReduce在大数据处理领域中的核心价值所在。
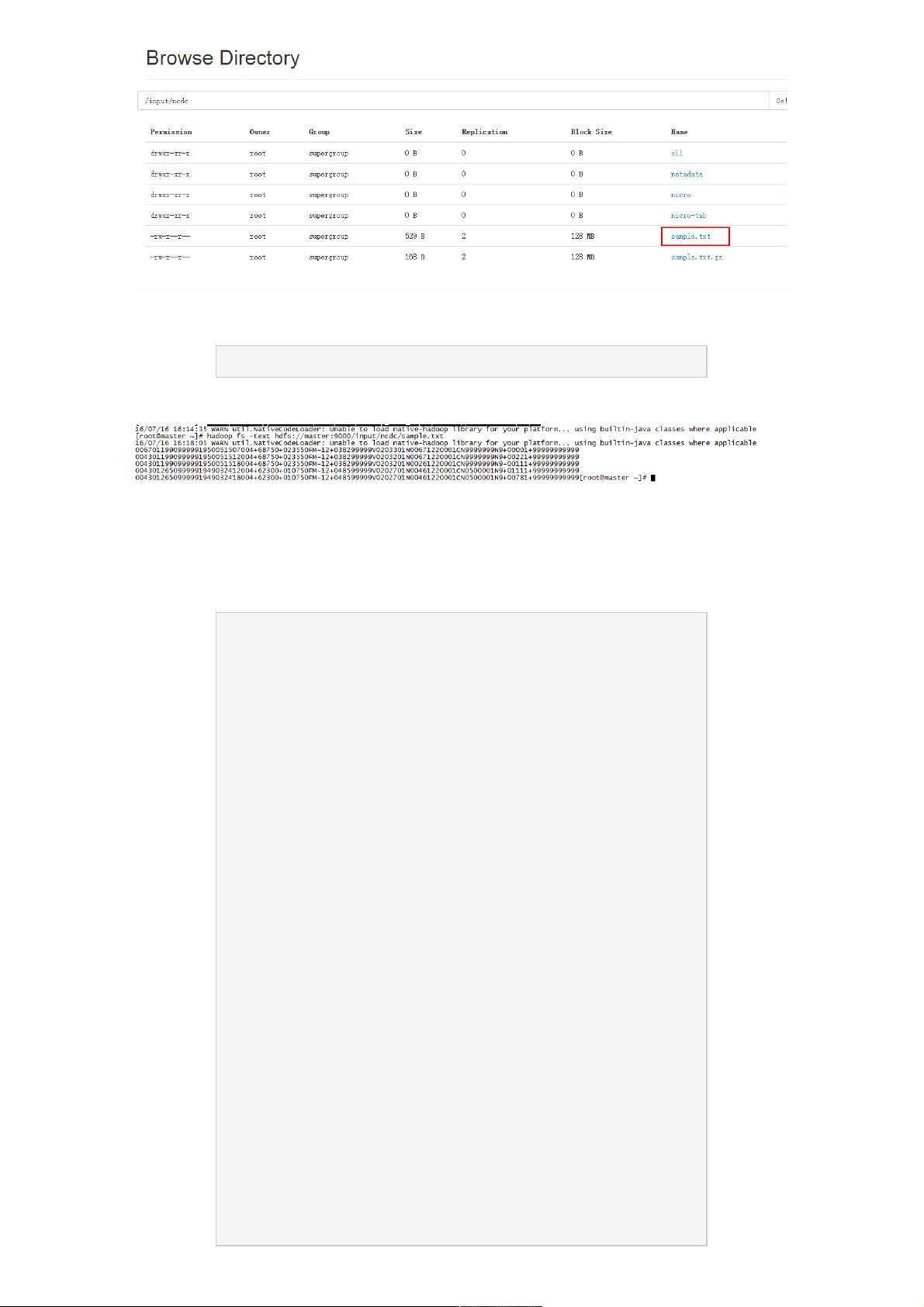
查看一下数据内容:
hadoop fs -text hdfs: //master: 9000/input /ncdc / sample .txt
编写Java代码
首先实现Mapper类,Mapper在新版本Hadoop中改变为类(旧版为接口)定义如下:
// 支持泛型,泛型定义map输入输出的键值类型
public class Mapper <KEYIN, VALUEIN, KEYOUT, VALUEOUT > {
public Mapper() {
// map任务开始的时候调用一次,用于做准备工作
protected void setup(Context context) throws IOException ,
InterruptedException {
// 空实现
}
// map逻辑 默认直接将输入进行类型转换后输出
protected void map (KEYIN key, VALUEIN value,
Context context) throws IOException, Interrupted Exception {
context.write ((KEYOUT) key, (VALUEOUT) value);
}
// 任务结束后调用一次,清理工作,与setup对应
protected void cleanup (Context context
) throws IOException, InterruptedException {
// 空实现
}
// map的实际运行过程就是调用run方法,一般用于高级实现,更精细地
控制 任务的执行过程, 一般情况不需要覆盖这个方法
public void run (Context context) throws IOExcep tion ,
InterruptedException {
// 准备工作
setup(context);
try {
// 遍历分配给该任务的数据,循环调用map
while (context.nextKeyValue()) {
map (context.getCurrentKey(), context .get CurrentValue (), context );
}
} finally {
// 清理工作
cleanup (context);
}
}
}
剩余11页未读,继续阅读
2021-01-07 上传
2023-09-17 上传
2023-12-27 上传
2023-03-16 上传
2023-06-01 上传
2023-06-09 上传
2023-06-11 上传

weixin_38636461
- 粉丝: 5
- 资源: 894
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
