
1.SparkContext是pyspark的编程入口,作业的提交,任务的分发,应用的注册都会在SparkContext中进行。一个SparkContext实例代
表着和Spark的一个连接,只有建立了连接才可以把作业提交到集群中去。实例化了SparkContext之后才能创建RDD和Broadcast广播变
量。
2.Sparkcontext获取,启动pyspark--masterspark://hadoop-maste:7077之后,可以通过SparkSession获取Sparkcontext对象
从打印的记录来看,SparkContext它连接的Spark集群的master地址是spark://hadoop-maste:7077
另外一种获取SparkContext的方法是,引入pyspark.SparkContext进行创建。新建sparkContext.py文件,内容如下:
frompysparkimportSparkContext
frompysparkimportSparkConf
conf=SparkConf()
conf.set('master','local')
sparkContext=SparkContext(conf=conf)
rdd=sparkContext.parallelize(range(100))
print(rdd.collect())
sparkContext.stop()
运行之前先将spark目录下的conf配置目录中的log4j.properties配置文件中的日志级别改为如下:
这样后台打印的日志不至于太多印象查看!重启Spark集群
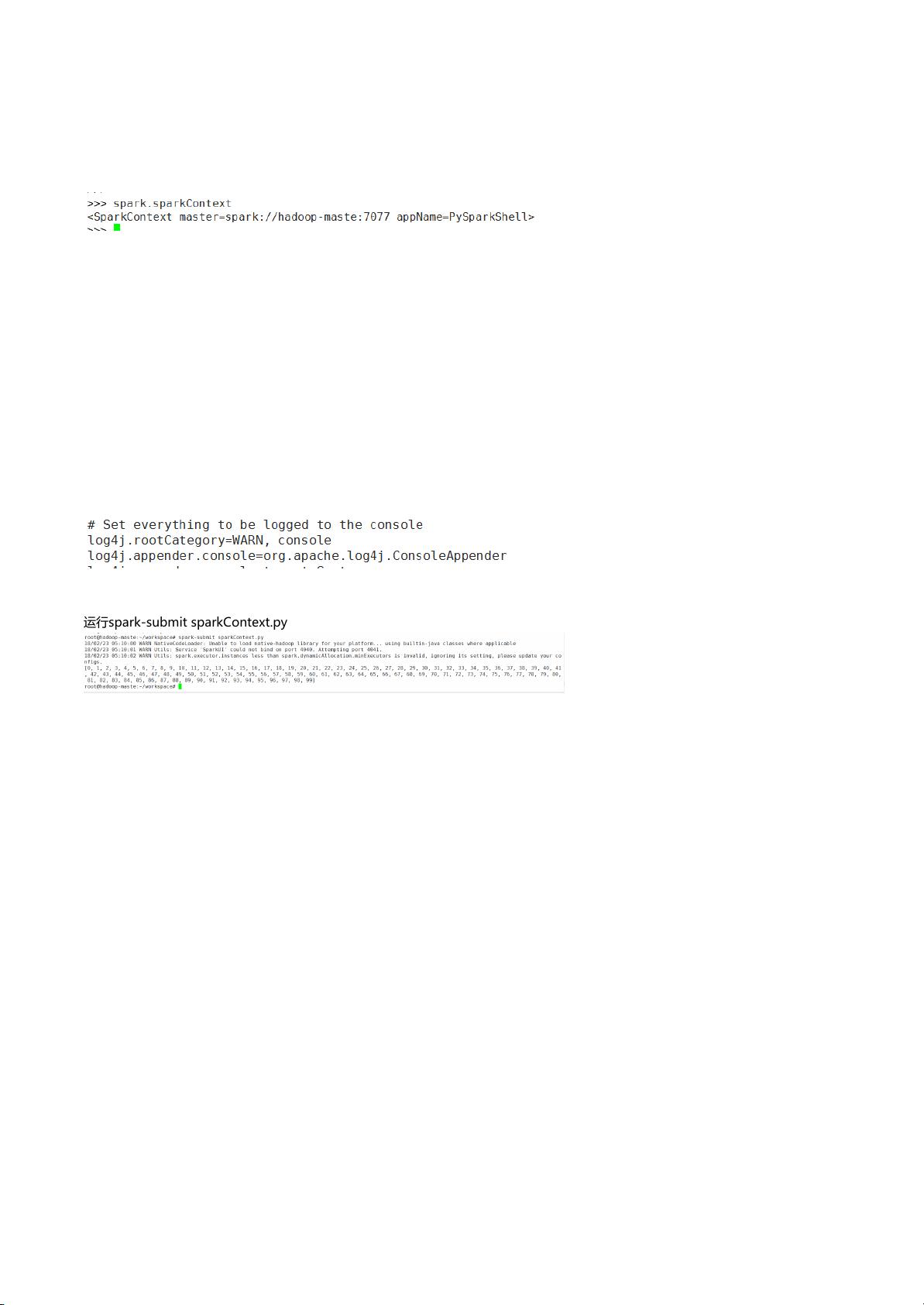
运行spark-submitsparkContext.py
上面代码中的Sparkconf对象是Spark里面用来配置参数的对象,接下来我们会详细讲解到。
3.accumulator是Sparkcontext上用来创建累加器的方法。创建的累加器可以在各个task中进行累加,并且只能够支持add操作。该方法
支持传入累加器的初始值。这里以Accumulator累加器做1到50的加法作为讲解的例子。
新建accumulator.py文件,内容如下:
frompysparkimportSparkContext,SparkConf
importnumpyasnp
conf=SparkConf()
conf.set('master','spark://hadoop-maste:7077')
context=SparkContext(conf=conf)
acc=context.accumulator(0)
print(type(acc),acc.value)
rdd=context.parallelize(np.arange(101),5)
defacc_add(a):
acc.add(a)
returna
rdd2=rdd.map(acc_add)
print(rdd2.collect())
print(acc.value)
context.stop()
使用spark-submitaccumulator.py运行
下载后可阅读完整内容,剩余6页未读,立即下载

老许的花开
- 粉丝: 31
- 资源: 328
 我的内容管理
展开
我的内容管理
展开







最新资源
- ASP.NET数据库高级操作:SQLHelper与数据源控件
- Windows98/2000驱动程序开发指南
- FreeMarker入门到精通教程
- 1800mm冷轧机板形控制性能仿真分析
- 经验模式分解:非平稳信号处理的新突破
- Spring框架3.0官方参考文档:依赖注入与核心模块解析
- 电阻器与电位器详解:类型、命名与应用
- Office技巧大揭秘:Word、Excel、PPT高效操作
- TCS3200D: 可编程色彩光频转换器解析
- 基于TCS230的精准便携式调色仪系统设计详解
- WiMAX与LTE:谁将引领移动宽带互联网?
- SAS-2.1规范草案:串行连接SCSI技术标准
- C#编程学习:手机电子书TXT版
- SQL全效操作指南:数据、控制与程序化
- 单片机复位电路设计与电源干扰处理
- CS5460A单相功率电能芯片:原理、应用与精度分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


