JavaScript实现UTF-8编码转换
PDF格式 | 156KB |
更新于2024-08-30
| 89 浏览量 | 举报
"本文主要介绍了如何使用JavaScript进行UTF-8编码的实现,包括JavaScript的字符集基础、UTF-8编码的原理以及将JavaScript中的Unicode字符串转换为UTF-8编码的方法。"
JavaScript是一种基于Unicode字符集的脚本语言,ECMAScript规范要求其支持Unicode 2.1及后续版本,确保了JavaScript能够处理多种语言的文字。Unicode是一种广泛使用的字符编码标准,包含了ASCII和Latin-1字符,并扩展到包含全世界各种语言的字符。
UTF-8作为Unicode的一种编码方式,它的特点是可变长度,可以根据字符的不同范围占用1至6个字节。UTF-8的一个重要特性是对ASCII字符的兼容性,使得ASCII字符在UTF-8编码下与原Unicode编码相同,只需1个字节表示,这对于处理兼容原有ASCII系统的软件非常有利。
在JavaScript中,我们需要将Unicode字符串转换为UTF-8编码,这通常发生在数据传输或者与服务器交互的过程中,例如当服务器要求数据以UTF-8编码提交时。转换的关键在于理解Unicode字符到UTF-8的转换规则,不同范围的Unicode码点对应不同的字节序列。对于Unicode码点:
- 1个字节:0–127(ASCII字符)
- 2个字节:128–2047
- 3个字节:2048–0xFFFF
- 4个字节:65536–0x1FFFFF
- 5个字节:0x200000–0x3FFFFFF
- 6个字节:0x4000000–0x7FFFFFFF
转换过程涉及到对Unicode码点的拆分和重新组合,通常使用位操作和循环来实现。JavaScript的`String.prototype.charCodeAt()`方法可以获取字符串中每个字符的Unicode码点,然后根据码点值计算出对应的UTF-8字节序列。
实际编程中,可以创建一个函数,接受Unicode字符串作为参数,遍历字符串中的每个字符,根据字符的Unicode码点计算出UTF-8编码,然后将这些字节拼接成新的字符串。这个过程可能涉及到位移、按位与、按位或等位运算,以确保正确地转换每个字符。
例如,以下是一个简单的转换示例(简化版,不包含所有Unicode范围):
```javascript
function unicodeToUtf8(unicodeStr) {
var utf8Arr = [];
for (var i = 0; i < unicodeStr.length; i++) {
var charCode = unicodeStr.charCodeAt(i);
if (charCode <= 0x7F) { // 1字节
utf8Arr.push(charCode);
} else if (charCode <= 0x7FF) { // 2字节
utf8Arr.push(0xC0 | (charCode >> 6));
utf8Arr.push(0x80 | (charCode & 0x3F));
}
// 其他范围类似处理
}
return String.fromCharCode.apply(null, utf8Arr);
}
```
这个函数会将输入的Unicode字符串转换为UTF-8编码的字节数组,然后通过`String.fromCharCode()`方法将字节数组转换回字符串形式。完整的转换函数应涵盖所有Unicode码点范围,但这个简化的例子展示了基本思路。
JavaScript中的UTF-8编码实现涉及到对Unicode字符集和UTF-8编码规则的理解,以及JavaScript内置的字符串和字符处理方法的运用。通过编写适当的函数,可以有效地在Unicode和UTF-8之间进行转换,以满足各种应用场景的需求。
通过通过javascript进行进行UTF-8编码的实现方法编码的实现方法
javascript的字符集:的字符集:
javascript程序是使用Unicode字符集编写的。Unicode是ASCII和Latin-1的超集,并支持地球上几乎所有的语言。
ECMAScript3要求JavaScript必须支持Unicode2.1及后续版本,ECMAScript5则要求支持Unicode3及后续版本。所以,我们编
写出来的
javascript程序,都是使用Unicode编码的。
UTF-8
UTF-8(UTF8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。
它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须
或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字的应用中,优先采用的编码。
目前大部分的网站,都是使用的UTF-8编码。
将javascript生成的Unicode编码字符串转为UTF-8编码的字符串
如标题所说的应用场景十分常见,例如发送一段二进制到服务器时,服务器规定该二进制内容的编码必须为UTF-8。这种情况
下,我们必须就要通过程序将javascript的Unicode字符串转为UTF-8编码的字符串。
转换方法转换方法
转换之前我们必须了解Unicode的编码结构是固定的。
不信可以试一试 String 的 charCodeAt 这个方法,看看返回的 charCode 占几个字节。
•英文占1个字符,汉字占2个字符
然而,UTF-8的编码结构长度是根据某单个字符的大小来决定长度有多少。
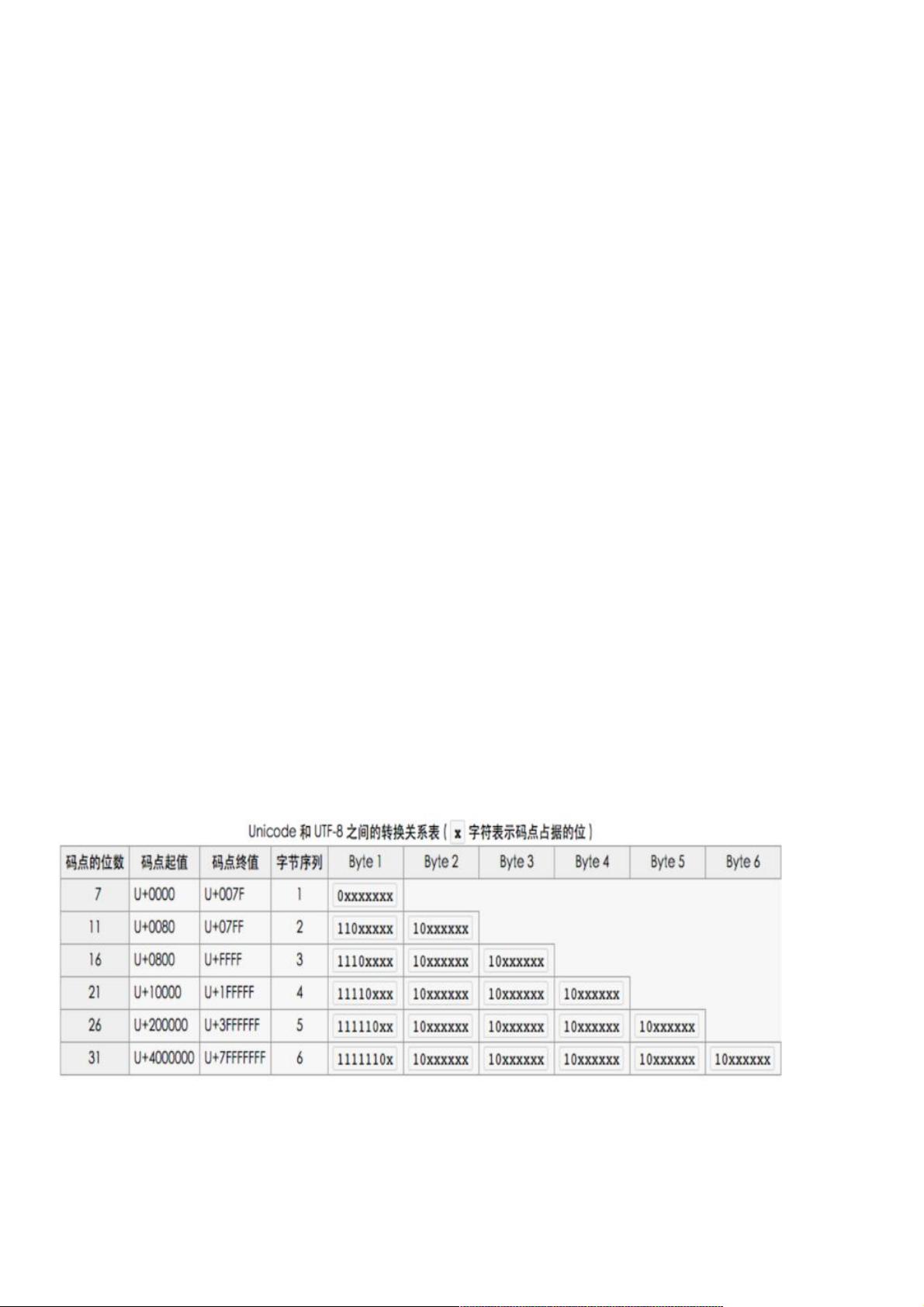
下面为单个字符的大小占用几个字节。单个unicode字符编码之后的最大长度为6个字节。
•1个字节:Unicode码为0 – 127
•2个字节:Unicode码为128 – 2047
•3个字节:Unicode码为2048 – 0xFFFF
•4个字节:Unicode码为65536 – 0x1FFFFF
•5个字节:Unicode码为0x200000 – 0x3FFFFFF
•6个字节:Unicode码为0x4000000 – 0x7FFFFFFF
具体请看图片:具体请看图片:
因为英文和英文字符的Unicode码为0 – 127,所以英文在Unicode和UTF-8中的长度和字节都是一致的,只占用1个字节。这
也就是为什么UTF8是Unicode的超集!
现在我们再来讨论汉字,因为汉字的unicode码区间为0x2e80 – 0x9fff, 所以汉字在UTF8中的长度最长为3个字节。
那么汉字是如何从Unicode的2个字节转换为UTF8的三个字节的哪?
假设我需要把汉字”中”转为UTF-8的编码
1、获取汉字、获取汉字Unicode值大小值大小
下载后可阅读完整内容,剩余3页未读,立即下载
相关推荐


405 浏览量


weixin_38680340
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Kubevious UI Diagram组件的图表可视化功能介绍
- 虚拟化检测神器 LeoMoon CPU-V 的使用与功能介绍
- 企业微信信息自动化处理程序:PYTHON3.8+FLASK实现
- 深入揭秘:使用Fiddler2破解AJAX网站技术
- Java实现服务器间文件传输的方法与实践
- FlexPaper 2.1.2源码获取与二次开发指南
- JS日历控件源码及工具实现解析
- C#实现仿QQ的P2P聊天软件源码发布
- 官方免费下载JDK 8u201 Windows x64安装包
- 优化图片大小的PNG压缩工具介绍
- 用Django框架创建简易甜蜜博客应用
- 实现二叉树核心功能:遍历、节点操作
- 数据结构与算法解决方案库:掌握Java技巧
- 深入解读遮罩技术与源码工具应用
- MATLAB实现一阶惯性加延迟环节曲线最小二乘拟合
- 基于微服务与机器学习的算法交易系统MBATS











