支持向量机在文本数据挖掘中的应用与性能比较
"基于文本的数据挖掘"
在当前的信息时代,数据挖掘已经成为科学研究和技术应用的关键领域,特别是对于基于文本的数据挖掘,它涉及到如何从大量文本数据中提取有价值的信息和知识。文本数据挖掘通常包括预处理、特征提取、模式识别和分类等多个步骤。
文本分类是数据挖掘中的一个重要任务,它涉及将文本数据归类到预先定义的类别中。支持向量机(Support Vector Machine, SVM)是一种被广泛应用于文本分类的机器学习算法。SVM通过构造最大边距超平面来划分数据,以达到最优的分类效果。在第二章中,详细介绍了SVM的理论基础,包括其算法提出的历史、基本概念和工作原理,以及与其他分类算法(如决策树、朴素贝叶斯等)的性能比较。
在实际应用中,支持向量分类器的编程实现是至关重要的。第三章中描述了系统功能的概览,包括程序的总体框架和主要功能函数,这为实际操作提供了指导。通过训练集和测试集的选取,评估了分类器的性能,分析了运行结果和正确率,这对于理解和优化分类器的性能至关重要。
文本分类不仅限于SVM,还包括其他方法,如神经网络。人工神经网络(Artificial Neural Networks, ANN)在第五章中被提及,它们在模式识别和分类任务中展现出强大的适应性和学习能力。此外,还有基于主题和文档的文本文摘构件库的讨论,这涉及到文本摘要的生成,如Luhn算法和Latent Semantic Analysis(LSA)。
在基于Web的系统设计中,第四章介绍了实验室管理系统的分析和实现,这表明数据挖掘技术也可用于提高管理和运营效率。整个第一部分围绕文本数据挖掘展开,从理论到实践,从单一的分类方法到综合的应用场景,揭示了数据挖掘在处理文本数据时的多样性和实用性。
基于文本的数据挖掘是一个多学科交叉的领域,涵盖了机器学习、自然语言处理和信息检索等多个方面。通过对文本数据的有效挖掘和分类,我们可以更好地理解和利用这些信息,从而在科学研究、商业决策、信息检索等众多领域中获得价值。随着技术的不断发展,这一领域的研究和应用将继续深化,为人类社会带来更多的智慧和便利。

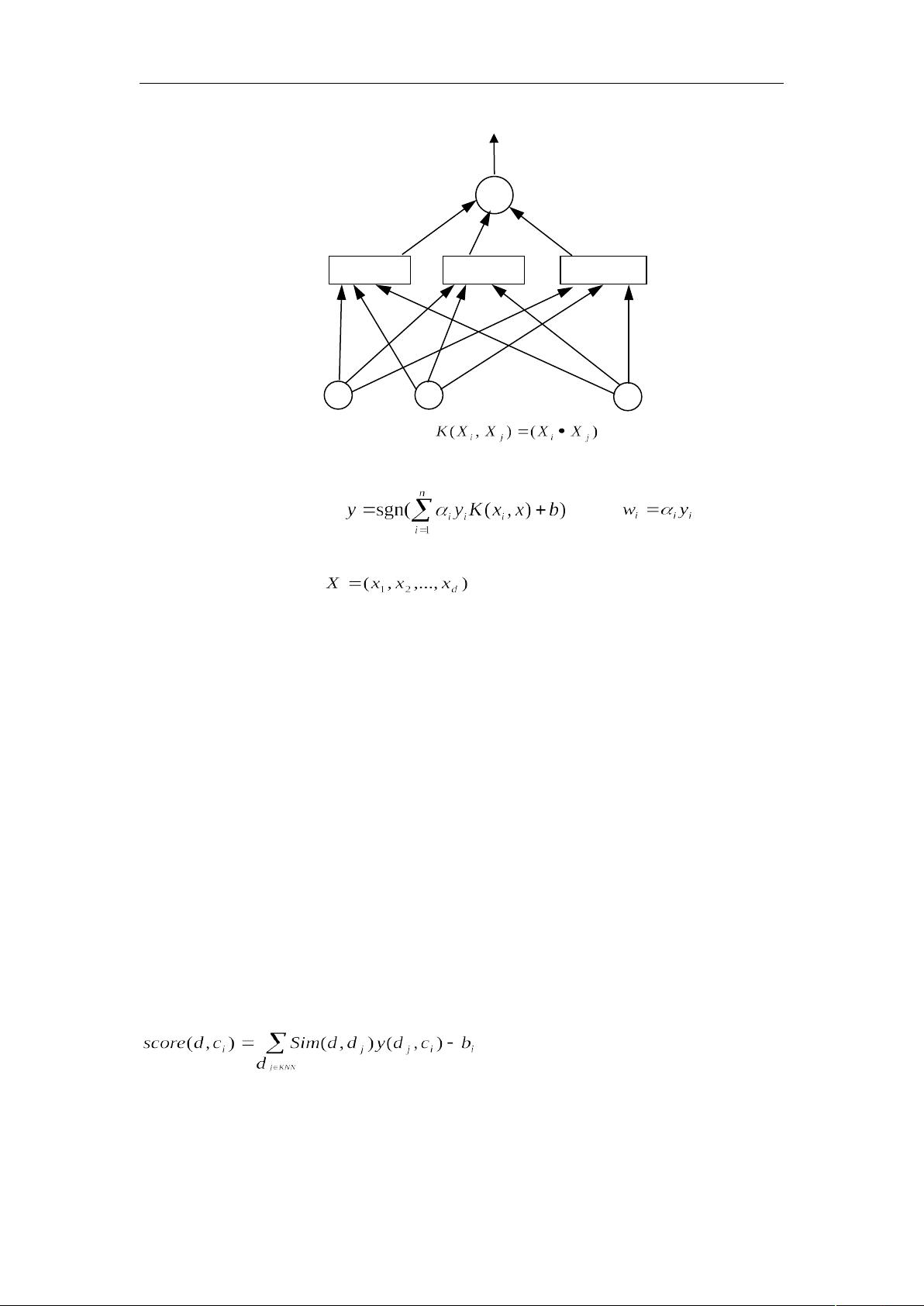
特征空间中完成。函数 称为点积的卷积核函数,根据 [4],它
可以看作在样本之间定义的一种距离。 显然,上面的方法在保证训练样本全部被正确分类,
即经验风险 为 0 的前提下,通过最大化分类间隔来获得
最好的推广性能。
在对分类函数的求解中常引入惩罚参数 C 来限制 的取值范围。则支持向量机算法
可以描述为[24]:
1. 已 知 训 练 集 , 其 中
2. 选择核函数 和惩罚参数 C>0,构造并求解最优
化问题
S.T.
3. 求得最优解 ;
4. 选 择 的 一 个 小 于 C 的 正 分 量 , 并 据 此 计 算
5. 求得决策函数
依 KKT 条件, 解中只有很少一部分
不为零,而它们对应的样本就是支持向量。由于 KKT 条件是最优解应满足的充要条件
[24],所以目前提出的一些算法几乎都是以是否违反 KKT 条件作为迭代策略的准则。
8

剩余63页未读,继续阅读
2023-08-20 上传
2023-06-02 上传
2023-02-23 上传
2023-05-22 上传
2024-04-03 上传
2023-03-25 上传

LJZ2885
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- dbml-renderer
- zwtdwz.js.cool:我发现了一个秘密! 这是一个特殊的存储库,可用于构建静态网站。 确保它是公开的,并使用网站文件进行初始化以开始使用
- 智能医疗办公室:应用程序的发布
- 小白也能听懂的Python课.txt打包整理.zip
- Firebase Auth in Chrome Extension Sample-crx插件
- 网吧主页
- ADC1,c语言源码打字游戏,c语言
- SUSTech-GPA-Calculator:不需专门服务器的网页版南方科技大学本科生 GPA 计算器
- β 和伽马的 NIST 质量吸收系数:材料中电子 (β) 和光子 (γ) 辐射的吸收。-matlab开发
- 仿华为手机网站触屏版手机wap企业网站模板_网站开发模板含源代码(css+html+js+图样).zip
- mqsync
- 作业12
- Nubo Beauty-crx插件
- tp-android-unity-Plugins:tp-android源码配合unity插件
- 将任何多维矩阵展平为二维矩阵!:将任何多维矩阵转换为二维矩阵。 然后将其转换回其原始形式。-matlab开发
- NextJS-chat-app:使用Ably和Next JS构建并由Vercel托管的聊天应用程序
