Storm编程入门:Spout组件与关键接口详解
143 浏览量
更新于2024-08-27
收藏 183KB PDF 举报
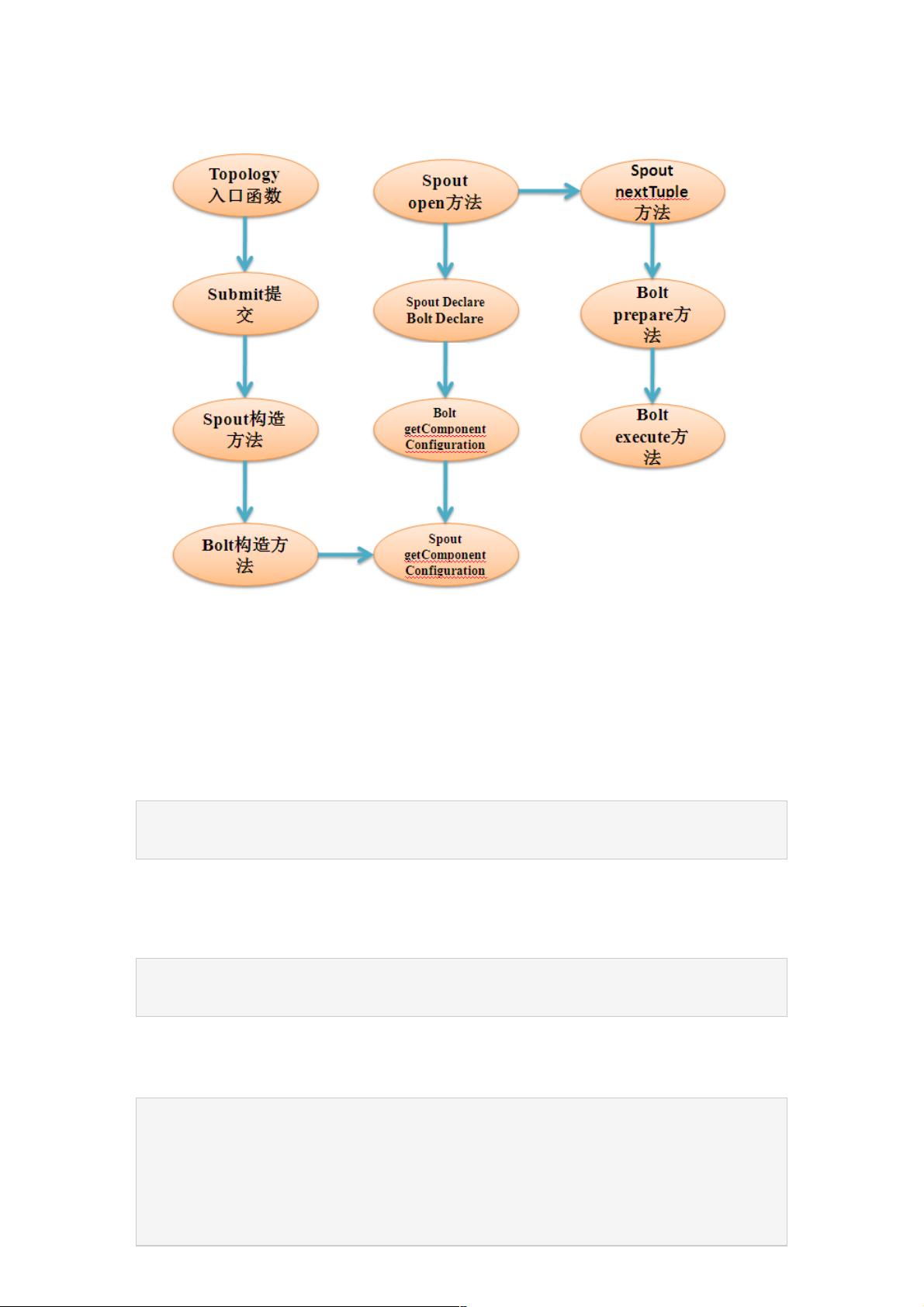
在Storm编程入门中,Spout组件是 Storm实时流处理系统中的基础组件,它负责从数据源读取数据并将其转化为消息(Tuples)注入到Topology中。Spout的实现方式有两种:一是通过继承BaseRichSpout类或者其派生类,如XyzSpout;二是实现IRichSpout接口。以下是关于Spout组件的关键接口和方法的详细介绍:
1. open方法:
- 这个方法在每个Task被初始化时会被调用。它主要用于初始化Spout的资源,如设置发送Tuple的工具`SpoutOutputCollector`和获取应用程序的配置信息`TopologyContext`。例如:
```java
public void open(Map<String, Object> conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
}
```
这里,`conf`提供了应用程序配置,`context`包含了运行时环境信息,而`collector`则用于将数据发送到Topology的其他组件。
2. declareOutputFields方法:
- 该方法用于声明Spout产生的Tuples的字段(域),这些字段的名称通常用于下游组件识别数据。它通过`OutputFieldsDeclare.declareStream`方法实现,如下所示:
```java
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
```
这里声明了一个名为"word"的字段。
3. getComponentConfiguration方法:
- 作为BaseComponent的一部分,`getComponentConfiguration`方法允许自定义组件特定的配置。例如,设置最大任务并行度:
```java
public Map<String, Object> getComponentConfiguration() {
if (!_isDistributed) {
Map<String, Object> ret = new HashMap<>();
ret.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, 3);
return ret;
} else {
return null;
}
}
```
这个方法可用于限制单个Spout实例的最大并发任务数。
4. nextTuple方法:
- `nextTuple`方法是Spout的核心逻辑,它负责生成并发送新的Tuples。在这个方法中,你可以根据需要编写数据处理逻辑。示例代码展示了如何简单地模拟每隔一段时间发送一个包含字符串数组的Tuples:
```java
public void nextTuple() {
try {
Thread.sleep(100);
final String[] words = new String[]{"two", "three", "four"};
// 发送一个包含单词的Tuple
_collector.emit(words);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
```
在实际应用中,`nextTuple`可能包含网络请求、文件读取、数据库查询等各种数据源操作。
学习Storm编程入门时,理解这些Spout组件的基础接口和方法至关重要,它们构成了实时流处理的基础架构,允许开发人员构建可扩展、高性能的数据流处理应用。
storm-编程入门编程入门
一 编程接口
Spout 接口
Spout组件的实现可以通过继承BaseRichSpout类或者其他*Spout类来完成,也可以通过实现IRichSpout接口来实现。需要根
据情况实方法有:
open方法
当一个Task被初始化的时候会调用此open方法。一般都会在此方法中对发送Tuple的对象SpoutOutputCollector和配置对象
TopologyContext初始化。示例如下:
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
_collector = collector;
}
declareOutputFields方法
此方法用于声明当前Spout的Tuple发送流的域名字。Stream流的定义是通过OutputFieldsDeclare.declareStream方法完成
的,其中参数为域名。示例如下:
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
getComponentConfiguration方法
此方法定义在BaseComponent类内,用于声明针对当前组件的特殊的Configuration配置。示例如下:
public Map<String, Object> getComponentConfiguration() {
if(!_isDistributed) {
Map<String, Object> ret = new HashMap<String, Object>();
ret.put(Config.TOPOLOGY_MAX_TASK_PARALLELISM, 3);
return ret;
} else {
return null;
}
}
下载后可阅读完整内容,剩余4页未读,立即下载
2014-12-11 上传
1046 浏览量
点击了解资源详情
2021-06-25 上传
2021-07-04 上传
2017-06-19 上传
2022-11-30 上传
点击了解资源详情
点击了解资源详情

weixin_38677227
- 粉丝: 4
- 资源: 929
 我的内容管理
展开
我的内容管理
展开







最新资源
- Struts教程(doc版)
- SIP协议的NAT穿越研究
- 架构风格与基于网络的软件架构设计.pdf
- MATLAB图像分割 [附MATLAB源码]
- oracle数据库的备份研究总结
- BeginningCFromNovicetoProfessional
- The C++ Standard Library: A Tutorial and Reference
- MD231模块运用手册,非常详细
- AT指令集中文版,适合开发者或初学者
- 基于细胞神经网的快速图像分割方法
- oracle数据库的备份与恢复
- 基于GIS的饮水安全评价与预测系统研究
- Linux常用命令服务器配置
- EMIStream Tool操作手冊
- EMIStream分析工具
- JAVA面试题解惑系列
