Java JVM内存与垃圾回收详解
60 浏览量
更新于2024-07-16
收藏 11.17MB PDF 举报
"JAVA核心知识点整理.pdf"
这篇文档是关于Java核心知识点的全面总结,特别适合面试准备和学习者深入理解Java技术体系。主要内容包括JVM的结构、内存区域、垃圾回收机制以及相关的算法和Java中的四种引用类型。
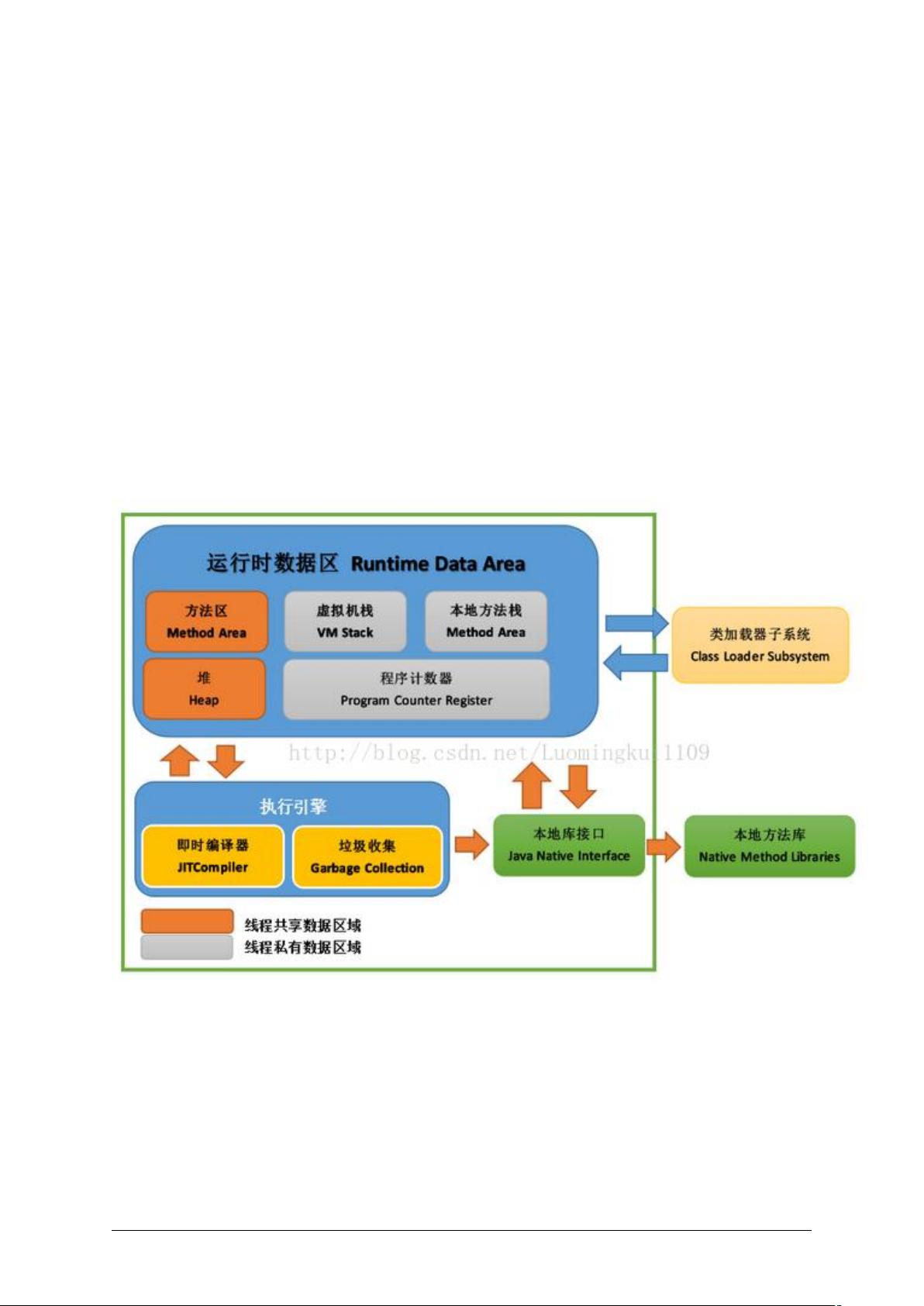
1. JVM (Java虚拟机) 是Java程序运行的基础,它负责解析和执行字节码。文档详细介绍了JVM的内部结构:
- 线程:JVM支持多线程执行,每个线程都有自己的程序计数器、虚拟机栈和本地方法栈。
- JVM内存区域分为程序计数器、虚拟机栈、本地方法栈、堆和方法区(在Java 8后被元空间取代)。这些区域各有其功能,例如:
- 程序计数器:记录当前线程的指令位置。
- 虚拟机栈:存储局部变量表、操作数栈、动态链接等信息。
- 本地方法栈:服务本地方法(如JNI)。
- 堆:存放对象实例,线程共享。
- 方法区/元空间:存储类信息、常量、静态变量等,也线程共享。
2. JVM运行时内存进一步细分为新生代、老年代和永久代(Java 8后为元空间):
- 新生代:用于存放新创建的对象,分为Eden区、SurvivorFrom区和SurvivorTo区,采用复制算法进行垃圾回收。
- 老年代:存放长期存活的对象,一般使用标记整理算法。
- 永久代/元空间:存储加载的类信息,Java 8后元空间替代了永久代,以减少对JVM内存的限制。
3. 垃圾回收(GC)是Java自动内存管理的关键部分,文档讨论了如何确定垃圾和多种垃圾回收算法:
- 确定垃圾的方法包括引用计数法和可达性分析。
- 常见的垃圾回收算法有标记清除、复制、标记整理和分代收集。这些算法各有优缺点,适用于不同的场景。
- 分代收集算法根据对象的生命周期将堆分为新生代和老年代,分别使用不同的算法进行垃圾回收。
4. Java提供了四种引用类型,以不同程度地控制对象的生命周期:
- 强引用:默认的引用类型,只要还有强引用指向对象,就不会被GC回收。
- 软引用:在系统内存不足时,会回收软引用指向的对象。
- 弱引用:比软引用更弱,只要有弱引用存在,不会阻止对象被回收。
- 虚引用:只用于跟踪对象何时被回收,不阻止回收。
5. 文档还涉及了不同类型的垃圾收集器,如Serial、ParNew、ParallelScavenge和SerialOld等,它们在单线程或多线程环境下应用不同的垃圾回收策略,以平衡系统的吞吐量和响应时间。
这份文档涵盖了Java开发者必须掌握的JVM内存管理和垃圾回收基础知识,对于理解Java程序的运行机制和优化性能具有重要意义。

13/04/2018
Page 16 of 283
24. 分布式缓存 ...................................................................................................................................... 257
24.1.1.
缓存雪崩
.................................................................................................................................... 257
24.1.2.
缓存穿透
.................................................................................................................................... 257
24.1.3.
缓存预热
.................................................................................................................................... 257
24.1.4.
缓存更新
.................................................................................................................................... 257
24.1.5.
缓存降级
.................................................................................................................................... 257
25. HADOOP ........................................................................................................................................ 259
25.1.1.
概念
............................................................................................................................................ 259
25.1.2. HDFS ......................................................................................................................................... 259
25.1.2.1. Client .................................................................................................................................................. 259
25.1.2.2. NameNode ........................................................................................................................................ 259
25.1.2.3. Secondary NameNode ................................................................................................................. 259
25.1.2.4. DataNode......................................................................................................................................... 259
25.1.3. MapReduce ............................................................................................................................... 260
25.1.3.1. Client ................................................................................................................................................. 260
25.1.3.2. JobTracker ....................................................................................................................................... 260
25.1.3.3. TaskTracker ...................................................................................................................................... 261
25.1.3.4. Task ................................................................................................................................................... 261
25.1.3.5. Reduce Task 执行过程 ................................................................................................................... 261
25.1.4. Hadoop MapReduce
作业的生命周期
................................................................................... 262
1.作业交与初始化........................................................................................................................................... 262
2.任务调度与监控。........................................................................................................................................... 262
3.任务运行环境准备........................................................................................................................................... 262
4.任务执行 .......................................................................................................................................................... 262
5.作业完成。 ...................................................................................................................................................... 262
26. SPARK ............................................................................................................................................ 263
26.1.1.
概念
............................................................................................................................................ 263
26.1.2.
核心架构
.................................................................................................................................... 263
Spark Core ......................................................................................................................................................... 263
Spark SQL .......................................................................................................................................................... 263
Spark Streaming ................................................................................................................................................ 263
Mllib ..................................................................................................................................................................... 263
GraphX ................................................................................................................................................................ 263
26.1.3.
核心组件
.................................................................................................................................... 264
Cluster Manager-制整个集群,监控 worker ................................................................................................. 264
Worker 节点-负责控制计算节点 ....................................................................................................................... 264
Driver: 运行 Application 的 main()函数......................................................................................................... 264
Executor:执行器,是为某个 Application 运行在 worker node 上的一个进程 .......................................... 264
26.1.4. SPARK
编程模型
...................................................................................................................... 264
26.1.5. SPARK
计算模型
...................................................................................................................... 265
26.1.6. SPARK
运行流程
...................................................................................................................... 266
1. 构建 Spark Application 的运行环境,启动 SparkContext .................................................................... 267
2. SparkContext 向资源管理器(可以是 Standalone,Mesos,Yarn)申请运行 Executor 资源,并启
动 StandaloneExecutorbackend, .................................................................................................................. 267
3. Executor 向 SparkContext 申请 Task ..................................................................................................... 267
4. SparkContext 将应用程序分发给 Executor ............................................................................................ 267
5. SparkContext 构建成 DAG 图,将 DAG 图分解成 Stage、将 Taskset 发送给 Task Scheduler,最
后由 Task Scheduler 将 Task 发送给 Executor 运行 ..................................................................................... 267
6. Task 在 Executor 上运行,运行完释放所有资源................................................................................... 267
26.1.7. SPARK RDD
流程
.................................................................................................................... 267
26.1.8. SPARK RDD ............................................................................................................................. 267
(1)RDD 的创建方式........................................................................................................................................... 267
(2)RDD 的两种操作算子(转换(Transformation)与行动(Action)) .............................................. 268
27. STORM ........................................................................................................................................... 269



剩余282页未读,继续阅读
2021-10-15 上传
2020-10-19 上传
2019-03-27 上传

DanielMaster
- 粉丝: 544
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- Windows Vista Performance and Tuning
- Flex flex 代码 flex 教程 Flex 高级教程 Flex 经典学习资源本书附有大量的源代码 原版无录制电子书
- YC2440开发指南-Ads1.2篇-20090319
- 手把手教你配置Windows2003集群(图)
- 开发规范之详细设计说明书
- Oracle10g安装手册(图).
- 摄像机标定程序 opencv在vc6.0环境
- pro django
- 单片机学习步骤 网上收集
- iBATIS学习教程
- EXT2.0中文文档
- 51单片机C语言手册
- 轻松搞定XML.pdf
- Apache Log的每日一个日志文件及选择性记录设置
- UML入门教程(中文版)电子书
- 地线干扰与抑制 .pdf
