MapReduce_shuffle过程详解:从Mapper到Reducer的数据流
149 浏览量
更新于2024-08-28
收藏 1.31MB PDF 举报
MapReduce_shuffle过程剖析及调优
MapReduce_shuffle过程是MapReduce框架中的一個核心组件,它负责将Mapper的输出数据传输到Reducer端,并对数据进行排序和合并。本文将详细剖析MapReduce_shuffle过程,并对其进行深入分析和调优。
**Mapper端**
在Mapper端,map函数输出的数据不会直接写入到磁盘,而是写入到一个环形Buffer中。环形Buffer是一个内存中的数据结构,专门用来存储Key-Value格式的数据。Buffer中有数据区和索引区两个部分,数据区用于存储Key-Value数据,索引区用于存储索引信息。索引信息是对key-value在Buffer中的索引,是一个四元组,包括value的起始位置、key的起始位置、partition值和value的长度。
**环形Buffer数据结构**
环形Buffer是一个首尾相连的数据结构,map将输出写入到这个Buffer中。Buffer中有一个分界点,用于标识数据区和索引区的边界。分界点不是固定的,每次Spill之后都会更新一次。初始分界点为0,数据存储方向为向上增长,索引存储方向向下。
**Spill**
当Buffer中的数据达到一定阈值时,会触发Spill操作。Spill操作将Buffer中的数据写入到磁盘中,并将Buffer中的数据清空。Spill操作可以减少内存的使用,避免OOM错误。
**合并Spill文件**
在Spill操作完成后,会生成多个Spill文件。这些文件需要被合并,以便于Reducer端的处理。合并Spill文件可以使用多种策略,例如,使用多个线程来并行合并文件,或者使用磁盘上的文件来存储合并后的文件。
**Reducer端**
在Reducer端,Reducer会将Mapper端输出的数据进行合并和排序。Reducer会将数据分区,并将每个分区的数据进行排序。Reducer会将排序后的数据输出到HDFS中。
**性能调优**
MapReduce_shuffle过程的性能调优是非常重要的。可以通过多种方法来调优,例如,增加Mapper和Reducer的个数,增加Buffer的大小,使用多个磁盘来存储Spill文件等。
MapReduce_shuffle过程是MapReduce框架中的一個核心组件,它负责将Mapper的输出数据传输到Reducer端,并对数据进行排序和合并。深入理解这个过程对于MapReduce调优至关重要。
MapReduceshuffle过程剖析及调优过程剖析及调优
MapReduce简介
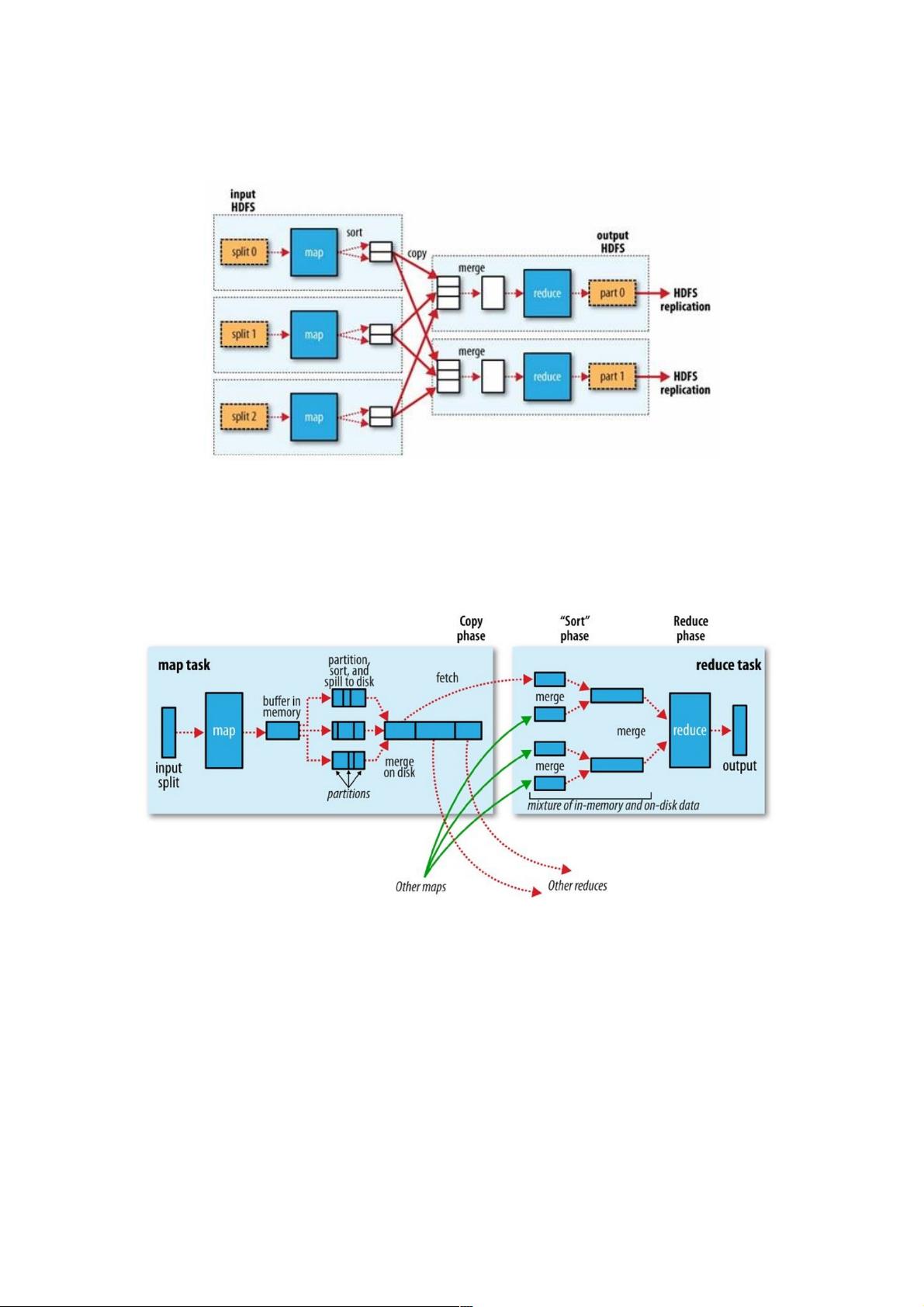
在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的。数据从Mapper输出到Reducer接收,是一
个很复杂的过程,框架处理了所有问题,并提供了很多配置项及扩展点。一个MapReduce的大致数据流如下图:
Mapper的输出排序、然后传送到Reducer的过程,称为shuffle。本文详细地解析shuffle过程,深入理解这个过程对于
MapReduce调优至关重要,某种程度上说,shuffle过程是MapReduce的核心内容。
Mapper端
当map函数通过context.write()开始输出数据时,不是单纯地将数据写入到磁盘。为了性能,map输出的数据会写入到缓冲
区,并进行预排序的一些工作,整个过程如下图:
环形Buffer数据结构
每一个map任务有一个环形Buffer,map将输出写入到这个Buffer。环形Buffer是内存中的一种首尾相连的数据结构,专门用来
存储Key-Value格式的数据:
下载后可阅读完整内容,剩余8页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2008-12-10 上传
2023-06-06 上传
2009-02-11 上传
2009-02-11 上传
2009-02-11 上传

weixin_38739044
- 粉丝: 2
- 资源: 950
 我的内容管理
展开
我的内容管理
展开







最新资源
- epsschool-api-2021:创建项目以展示我的C#技能并开始我的投资组合
- theExile
- 电气
- node-express-course:在这个应用程序中,我们讨论如何使用节点以及表达和表达使创建服务器端应用程序变得容易
- langstroth-server:接受从 Langstroth Android 应用程序上传的服务器
- Android应用源码SeeJoPlayer视频播放器-IT计算机-毕业设计.zip
- ncomatlab代码-LO:LiveOcean代码项目的新版本
- idelub:用颤抖重拍我的投资组合
- 基于Java web的图书馆管理系统(源码+数据库).zip
- HotelMongoDbSpring:一个基于酒店管理执行CRUD操作的基本SPRING BOOT应用程序
- stat101:解决所有与统计有关的问题的网站
- 118-redux-from-scratch-rxjs:第118集-使用RxJS和Angular从头开始构建Redux样式的状态容器
- poker-royal-flush
- 行业文档-设计装置-一种利用乙醇制浆废液改性制备纸张增强剂的方法.zip
- react-schedule-daily:React日常计划管理
- ncomatlab代码-chk2021-lengthscale-dry:chk2021-lengthscale-dry
