Hadoop安装教程:从单机到伪分布式
需积分: 12 157 浏览量
更新于2024-07-17
1
收藏 8.41MB DOCX 举报
"Hadoop安装教程,包括单机、伪分布式和分布式模式,涉及JAVA环境配置、SSH安装、Hadoop环境变量设置及测试案例"
在安装Hadoop之前,首先要确保你的系统上已经安装了Java环境,因为Hadoop依赖于Java运行。在描述中提到,所有的操作都是在非root用户下进行,这有助于保持系统的安全性和稳定性。
1. **JAVA安装**:
首先,你需要安装Java Development Kit (JDK)。在示例中,JDK的版本是1.8.0_112。你可以通过以下命令在Ubuntu系统中安装JDK:
```bash
sudo apt-get install default-jdk
```
安装完成后,确认JAVA_HOME环境变量指向JDK的安装路径。
2. **SSH安装**:
SSH用于在不同节点间建立安全的远程登录连接。在Hadoop的分布式环境中,SSH是必需的。你可以使用以下命令安装SSH:
```bash
sudo apt-get install ssh
```
安装完成后,通过`ssh localhost`测试SSH是否能正常工作。
3. **Hadoop的单机安装**:
Hadoop的单机安装是最简单的模式,主要用于学习和测试。首先解压下载的Hadoop二进制包,如hadoop-2.7.3.tar.gz。然后,使用`vim`编辑器修改`etc/hadoop/hadoop-env.sh`文件,设置JAVA_HOME为你的JDK安装路径。例如:
```bash
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
```
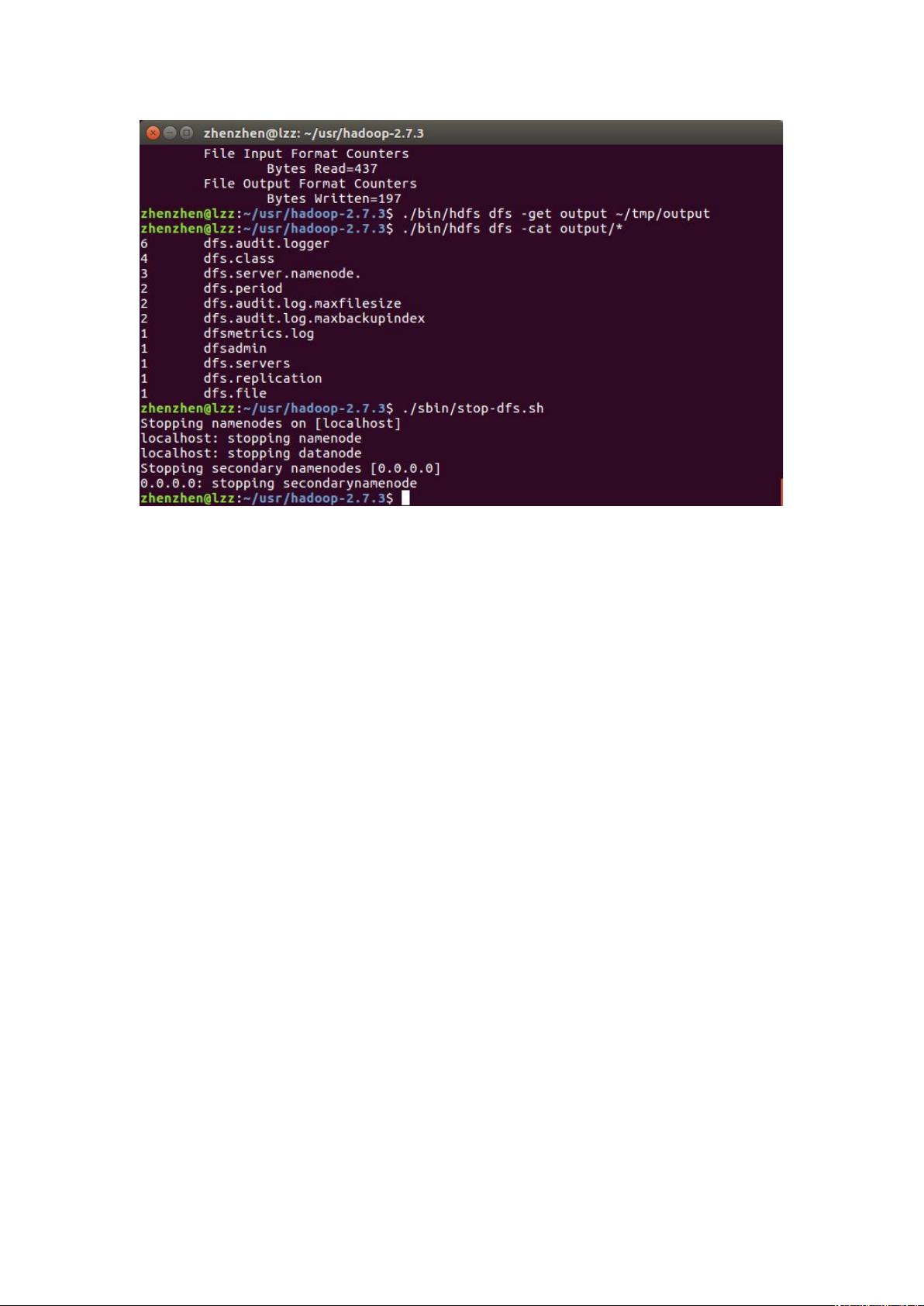
验证安装是否成功,可以运行`bin/hadoop`,如果显示出帮助信息,说明Hadoop已配置好。接着,可以进行简单的WordCount测试,创建输入文件,复制.xml文件到input目录,运行MapReduce任务,并查看输出结果。
4. **Hadoop伪分布式安装**:
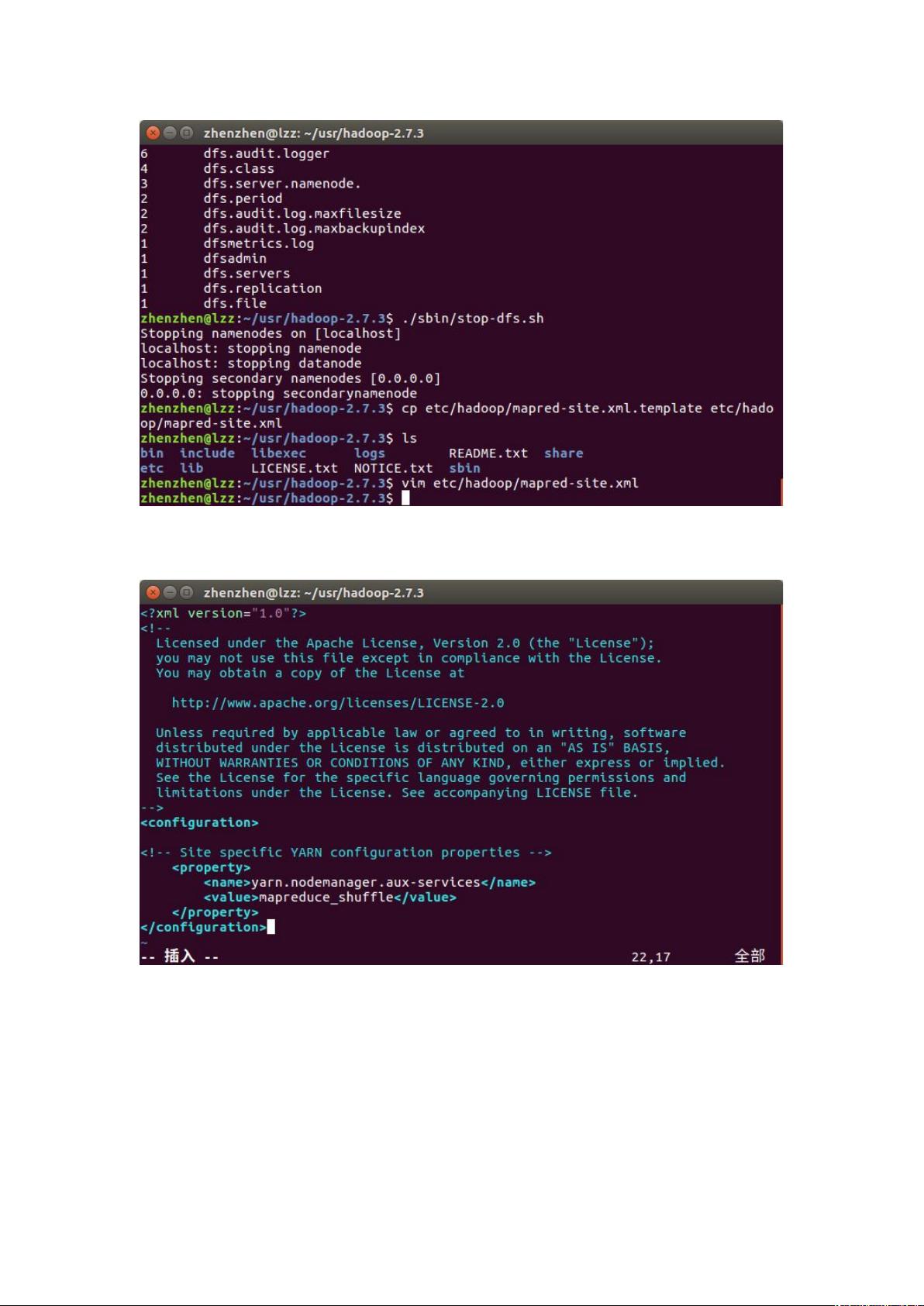
在伪分布式模式中,所有Hadoop守护进程都在同一台机器上运行,模拟分布式环境。你需要配置Hadoop的配置文件,比如`core-site.xml`、`hdfs-site.xml`和`mapred-site.xml`。在`hdfs-site.xml`中,设置`dfs.replication`为1,表示副本数为1。同时,还需要配置`mapred-site.xml`以启用YARN。
5. **格式化NameNode**:
在首次启动Hadoop时,需要对NameNode进行格式化,这会清空所有HDFS数据,因此只应在初次启动或恢复时执行:
```bash
sbin/hadoop namenode -format
```
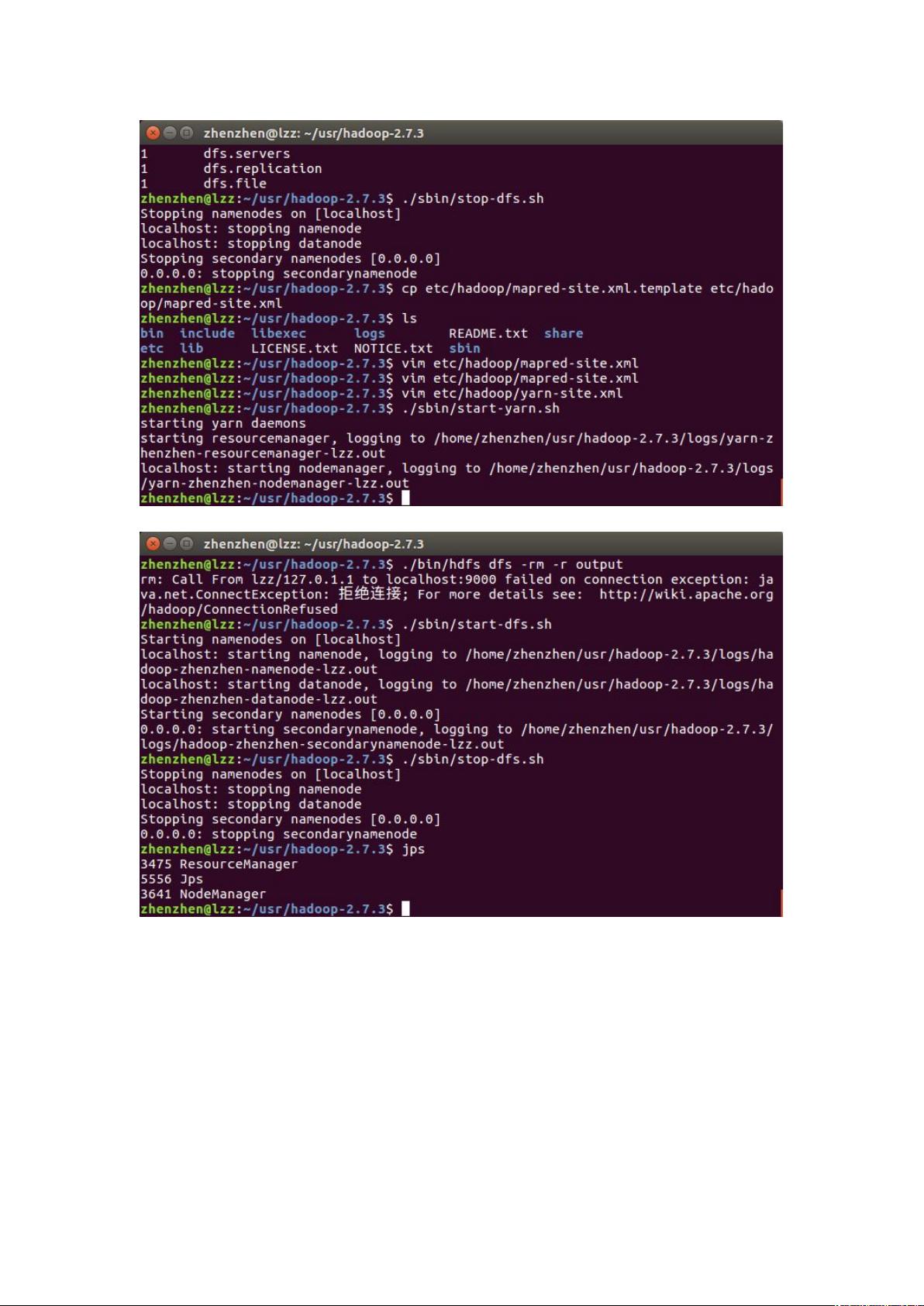
6. **启动和停止Hadoop服务**:
使用以下命令启动所有Hadoop守护进程:
```bash
sbin/start-dfs.sh
sbin/start-yarn.sh
```
同样,使用`stop-dfs.sh`和`stop-yarn.sh`来停止服务。
7. **Hadoop分布式安装**:
分布式安装涉及到多台机器,每个节点都需要安装Java和Hadoop,配置SSH互信,以及复制配置文件到所有节点。NameNode和ResourceManager在主节点上运行,DataNode和NodeManager在每个数据节点上运行。确保所有节点间的网络通信畅通,且配置文件中的`masters`和`slaves`文件正确指定主机名。
在完成以上步骤后,你就可以在你的系统上运行Hadoop了,无论是用于学习还是实际的分布式处理任务。记住,配置过程中要细心检查每一步,避免因小错误导致大问题。在遇到问题时,查阅官方文档和社区资源通常都能找到解决方案。
在单节点机器上运行 yarn
通过配置一些参数,你可以在伪分布式模型中的 9 上运行 %? 任务。然后在额外
启动 ?% 守护进程和 K% 守护进程
配置 4文件
先把 安装包里面的这个模板文件复制一份
345,
编辑文件
345,
设置 %? 的计算框架使用 9
67*8
698
68!@/68
6 896 8
698
67*8
剩余61页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-08-03 上传
2019-04-14 上传
2022-09-13 上传

Day_Romantic
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- PureMVC AS3在Flash中的实践与演示:HelloFlash案例分析
- 掌握Makefile多目标编译与清理操作
- STM32-407芯片定时器控制与系统时钟管理
- 用Appwrite和React开发待办事项应用教程
- 利用深度强化学习开发股票交易代理策略
- 7小时快速入门HTML/CSS及JavaScript基础教程
- CentOS 7上通过Yum安装Percona Server 8.0.21教程
- C语言编程:锻炼计划设计与实现
- Python框架基准线创建与性能测试工具
- 6小时掌握JavaScript基础:深入解析与实例教程
- 专业技能工厂,培养数据科学家的摇篮
- 如何使用pg-dump创建PostgreSQL数据库备份
- 基于信任的移动人群感知招聘机制研究
- 掌握Hadoop:Linux下分布式数据平台的应用教程
- Vue购物中心开发与部署全流程指南
- 在Ubuntu环境下使用NDK-14编译libpng-1.6.40-android静态及动态库
