基于词典合成与上下文聚类的分布式词义表示模型
136 浏览量
更新于2024-07-15
收藏 386KB PDF 举报
本文档探讨了一种基于词义合成与上下文聚类的分布式词义表示模型(GlossComposition and Context Clustering Based Distributed Word Sense Representation Model)。近年来,随着自然语言处理技术的发展,学习单词的不同意义(词义)的分布式表示方法日益受到关注。传统基于上下文聚类的模型往往需要精细调整参数,但在处理低频词义时表现欠佳。该研究旨在解决这些问题,提出一种创新的方法。
在传统的模型中,例如2015年《Entropy》期刊发表的文章(Entropy, Vol. 17, Issue 9, Pages 6007-6024, doi:10.3390/e17096007),作者们关注的是如何通过结合词典释义(gloss composition)和上下文信息,创建一个更加灵活且适用于各种频率词义的表示框架。这种方法可能采用词嵌入技术(如word2vec或GloVe),但重点在于改进模型的泛化能力,尤其是对那些在文本中出现较少但仍具有重要意义的词义的理解。
作者团队,由Tao Chen、Ruifeng Xu、Yulan He和Xuan Wang组成,分别来自深圳数字舞台性能机器人工程实验室(Shenzhen Engineering Laboratory of Performance Robots at Digital Stage, Harbin Institute of Technology, Shenzhen)和阿斯顿大学工程与应用科学学院(School of Engineering and Applied Science, Aston University, Birmingham),他们提出了一个自适应的框架,旨在减少对模型参数的依赖,并提高对稀有词义的捕捉能力。他们可能使用了如潜在语义分析(latent semantic analysis, LSA)或者深度学习算法,通过词义的共现和上下文中的语义相似性来构建词义的分布式表示。
论文的接收日期为2015年5月6日,经过审阅后于8月21日接受,最终于8月27日发表。文章的学术编辑为Raúl Alcaraz Martínez。该研究不仅关注理论创新,还可能包含了大量的实验数据和实例,用以评估新模型在词义识别任务中的性能对比,以及与现有方法的比较。
这篇研究论文提供了对如何利用词义合成和上下文聚类技术改进分布式词义表示模型的新视角,这对于自然语言处理领域,特别是在语义理解、信息检索和机器翻译等应用场景中,具有实际的应用价值。同时,它也为后续的研究者提供了一个有价值的基础,推动了词义表示领域的进一步发展。
Entropy 2015, 17 6010
2.2. Distributed Sentence Composition Model
Distributed Sentence Composition refers to representing a sentence in a low-dimensional space for
conveying the semantic information contained in the sentence. Various types of distributed sentence
representation models have been proposed recently. Socher et al. [16] proposed a recursive neural tensor
network (RNTN) for semantic compositionality over a sentiment Treebank which pushes the binary
classification accuracy on Stanford sentiment tree bank from 80% up to 85.4%. Kalchbrenner et al. [17]
proposed a dynamic convolutional neural network (DCNN) to handles the input sentences with varying
length and induced a feature graph over the sentence that is capable of explicitly capturing short and
long-range relations. It improves the above accuracy from 85.4% to 86.8%. Kim [18] presented two
simple CNN models with little hyper parameter tuning which are trained on pre-trained word vectors for
sentence-level classification tasks. It further improves the above accuracy to 88.1%. Le and Mikolov [19]
proposed an unsupervised algorithm that learns fixed-length feature representations from variable-length
pieces of texts, such as sentences, paragraphs and documents. The recurrent neural network (RNN) may
also be viewed as a sentence model. The layer computed at the last word represents the sentence [11,17].
3. Our Approach
In this study, we propose to learn distributed representation of word sense learning approach by
incorporating WordNet gloss compositionality and context words clustering in large-scale raw text.
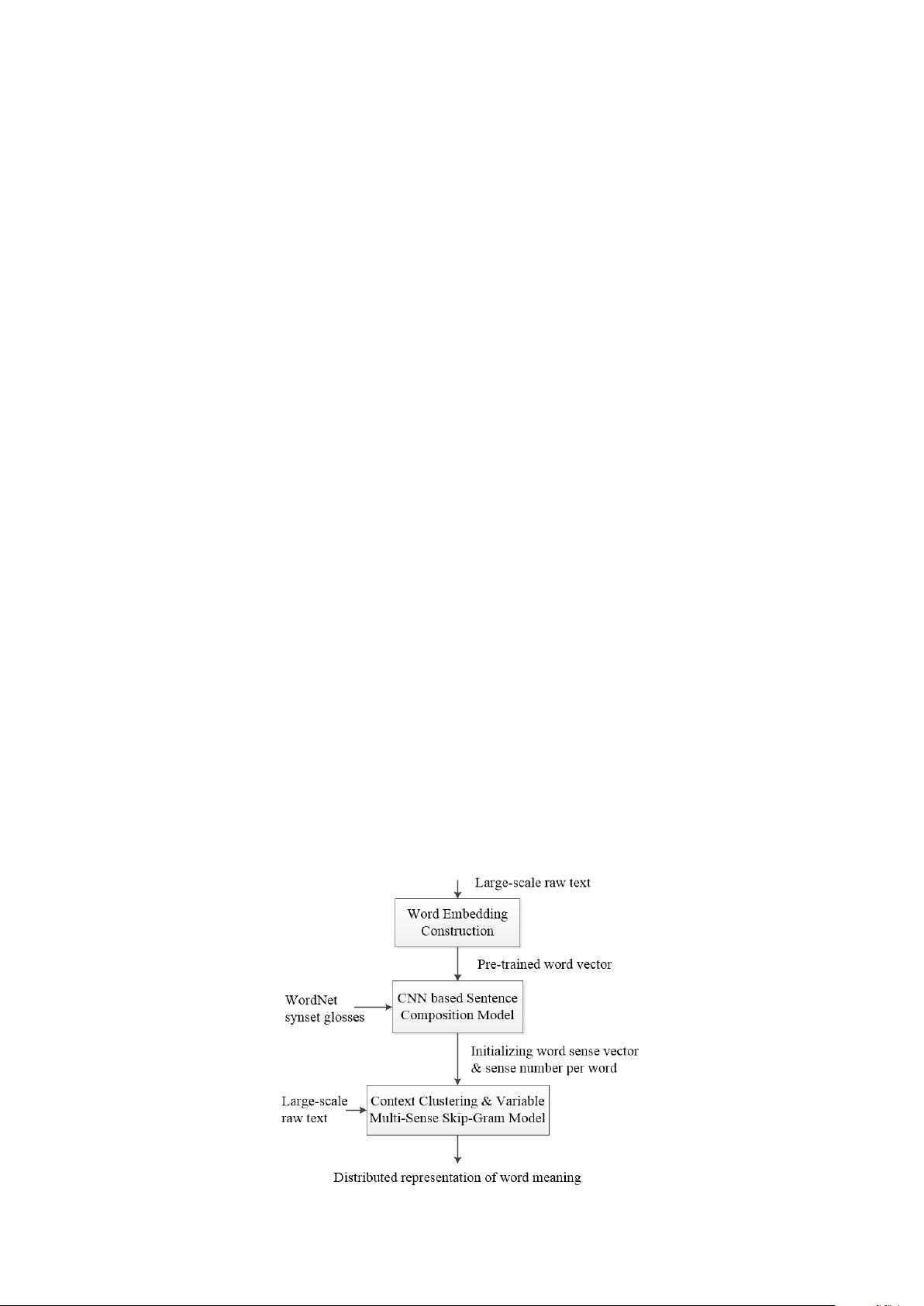
The system framework with three main components is shown in Figure 1. The first component, the
Word Embedding Construction Module, takes a large collection of raw text to train a word embedding
model. The word embeddings output by the model are then used by a Sentence Composition Model,
which takes glosses in WordNet as positive training data and randomly replacing part of the words as
negative training data to construct the corresponding word sense vectors based on the one-dimensional
CNN. The learned sense vectors are fed into a variant of the previously proposed Multi-Sense Skip-Gram
Model (MSSG) to generates distributed representations of word senses from a text corpus. We name our
approach as CNN-VMSSG.
Figure 1. Framework of our approach.
剩余17页未读,继续阅读
2012-04-24 上传
2012-09-10 上传
2010-04-11 上传
2023-05-10 上传
2023-09-10 上传
2023-05-19 上传
2023-06-09 上传
2023-12-14 上传
2023-12-14 上传
2023-06-09 上传

weixin_38693311
- 粉丝: 4
- 资源: 922
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
