单机Ubuntu上详尽的Hadoop搭建教程与SSH配置
需积分: 9 158 浏览量
更新于2024-07-20
1
收藏 721KB DOCX 举报
本文档详细介绍了如何在一台单机上进行Hadoop环境的搭建过程,适合对Hadoop技术感兴趣且初次接触者参考。首先,作者强调了Hadoop项目的重要性和团队协作的经历。整个安装过程包括以下步骤:
1. **安装Linux操作系统**:
使用Ubuntu 11.10作为操作系统,由于是Windows用户,选择通过虚拟光驱安装Wubi方法,虽然这种方法存在可能卡顿的问题,但操作相对简单。
2. **创建用户组和用户**:
为了专门管理和操作Hadoop,作者创建了一个名为'hadoop'的用户组和用户,确保权限管理清晰。
3. **安装JDK**:
JDK(Java Development Kit)是Hadoop运行的基础,安装过程在这里没有详述,但这是必不可少的一步。
4. **修改机器名**:
为了便于管理和通信,需要为服务器设置一个有意义的主机名。
5. **安装SSH服务**:
SSH(Secure Shell)用于远程登录,是Hadoop集群管理的重要工具。
6. **无密码SSH登录**:
为提升管理效率,配置SSH免密登录,确保安全的前提下简化操作流程。
7. **安装Hadoop**:
安装Hadoop核心组件,包括HDFS(Hadoop Distributed File System)和MapReduce框架,文档未提供具体的安装包来源和命令行步骤,但这是一个关键环节。
8. **运行Hadoop**:
在单机上运行简单的MapReduce程序,验证Hadoop环境是否配置正确。
在整个过程中,作者强调了实践操作中的注意事项和遇到的问题,对于初学者来说,这是一份实用且具有指导性的教程。阅读本文后,读者将对Hadoop的安装和基础配置有深入理解,有助于后续在集群环境下扩展和管理Hadoop集群。
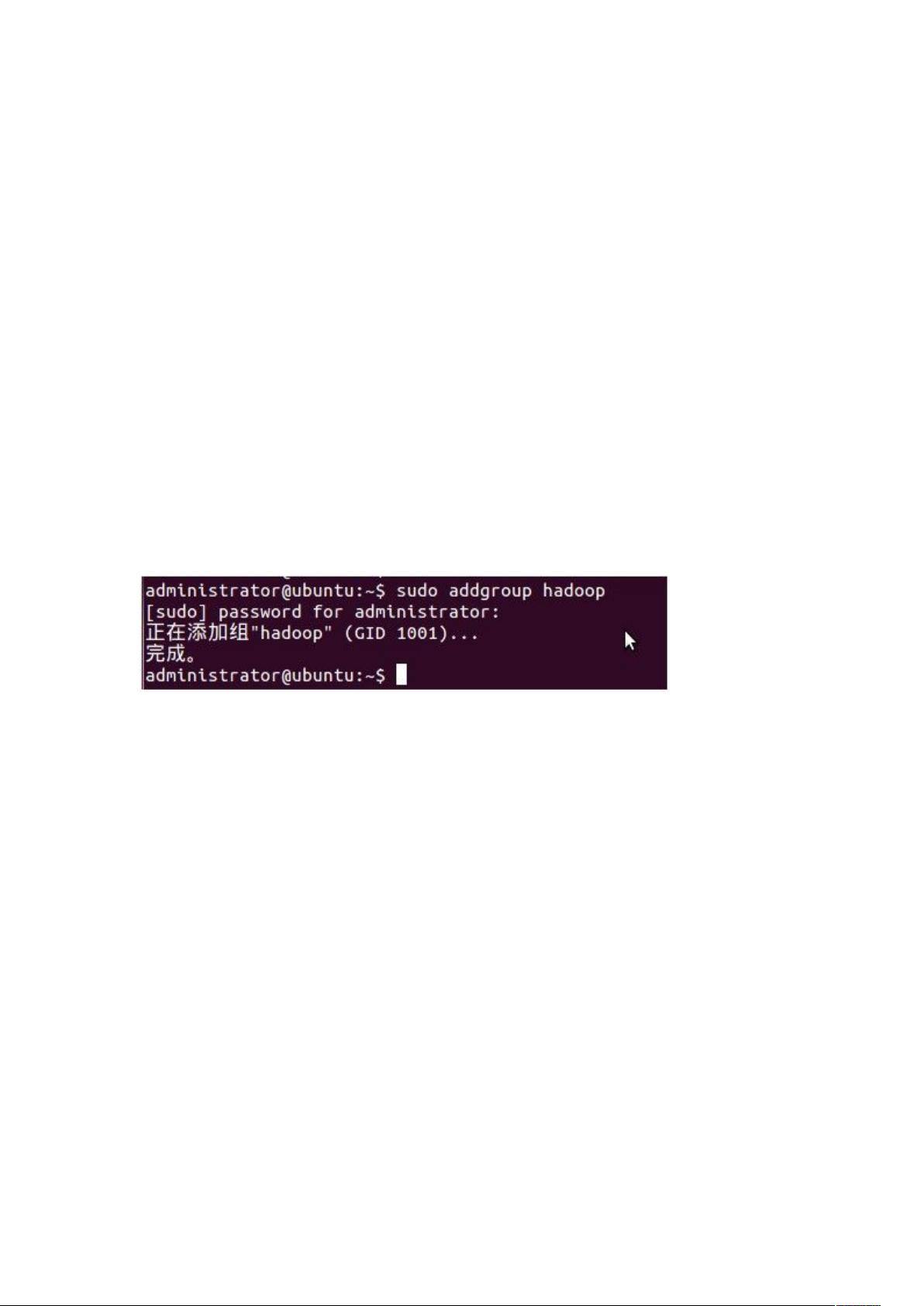
二、在 Ubuntu 下创建 hadoop 用户组和用户
这里考虑的是以后涉及到 hadoop 应用时,专门用该用户操作。用户组名和用
户名都设为:hadoop。可以理解为该 hadoop 用户是属于一个名为 hadoop
的用户组,这是 linux 操作系统的知识,如果不清楚可以查看 linux 相关的书
籍。
1、创建 hadoop 用户组,如图(3)
"
"
2、创建 hadoop 用户,如图(4)
"
剩余15页未读,继续阅读
105 浏览量
204 浏览量
182 浏览量
197 浏览量
108 浏览量
2023-03-31 上传

nxt
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Linux与iOS自动化开发工具集:SSH免密登录与一键调试
- HTML5基础教程:深入学习与实践指南
- 通过命令行用sonic-pi-tool控制Sonic Pi音乐创作
- 官方发布droiddraw-r1b22,UI设计者的福音
- 探索Lib库的永恒春季:代码与功能的融合
- DTW距离在自适应AP聚类算法中的应用
- 掌握HTML5前端面试核心知识点
- 探索系统应用图标设计与ioc图标的重要性
- C#窗体技巧深度解析
- KDAB发布适用于Mac Touch Bar的Qt小部件
- IIS-v6.0安装文件压缩包介绍
- Android疫情数据整合系统开发教程与应用
- Simulink下的虚拟汽车行驶模型设计
- 自学考试教材《操作系统概论》概述
- 大型公司Java面试题整理
- Java 3D技术开发必备的jar包资源
