决策树与随机森林:入门指南与深度解析
8 浏览量
更新于2024-08-29
1
收藏 236KB PDF 举报
决策树与随机森林是机器学习领域中的两种重要模型,它们被广泛应用于分类和预测任务中,因其直观性和易于理解而受到初学者的青睐。本文由作者汪毅雄撰写,通过实例深入浅出地讲解了这两个概念。
决策树是一种基本的监督学习算法,它通过构建一系列逻辑规则(决策路径)来对数据进行分类或回归。决策树的建立过程通常从选择具有最大信息增益或最小熵的特征作为根节点开始,然后递归地对子集进行划分,直至达到预设的停止条件,如达到最大深度或者所有样本属于同一类别。信息增益(ID3算法)和基尼不纯度是常用的信息度量方式,它们衡量了特征划分后样本的不确定性降低程度。
举个例子,如果要决定是否借钱给他人,决策树会依据借款人的信用、你的财务状况和需求等因素来做出决策。理想情况下,每个分支节点的样本应尽可能集中在单一类别,这有助于提高预测准确性。在选择特征时,ID3算法会优先选择信息增益最大的特征,而C4.5和CART算法则采用基尼指数和Gini不纯度来评估。
随机森林则是决策树的一种集成方法,它构建多棵独立的决策树并取它们的多数投票结果作为最终预测。随机森林通过以下方式提高预测性能:随机选取一部分特征(而不是全部)进行树的构建,以及在每个节点上随机抽取部分样本(bootstrap样本)进行训练。这种方法降低了过拟合风险,提高了模型的稳定性和泛化能力。
总结来说,决策树的核心是寻找最优特征划分,而随机森林则通过集成多个决策树来增强模型的鲁棒性。理解这两种模型的关键在于掌握特征选择策略(如信息增益、基尼不纯度)、决策树的构造过程以及随机森林的集成原理。通过实践和深入学习,初学者可以更好地应用决策树和随机森林进行实际问题的解决。
机器学习之决策树与随机森林模型机器学习之决策树与随机森林模型
决策树
引言
决策树,是机器学习中一种非常常见的分类方法,也可以说是所有算法中最直观也最好理解的算法。先举个最简单的例子:
A:你去不去吃饭?
B:你去我就去。
“你去我就去”,这是典型的决策树思想。
再举个例子:
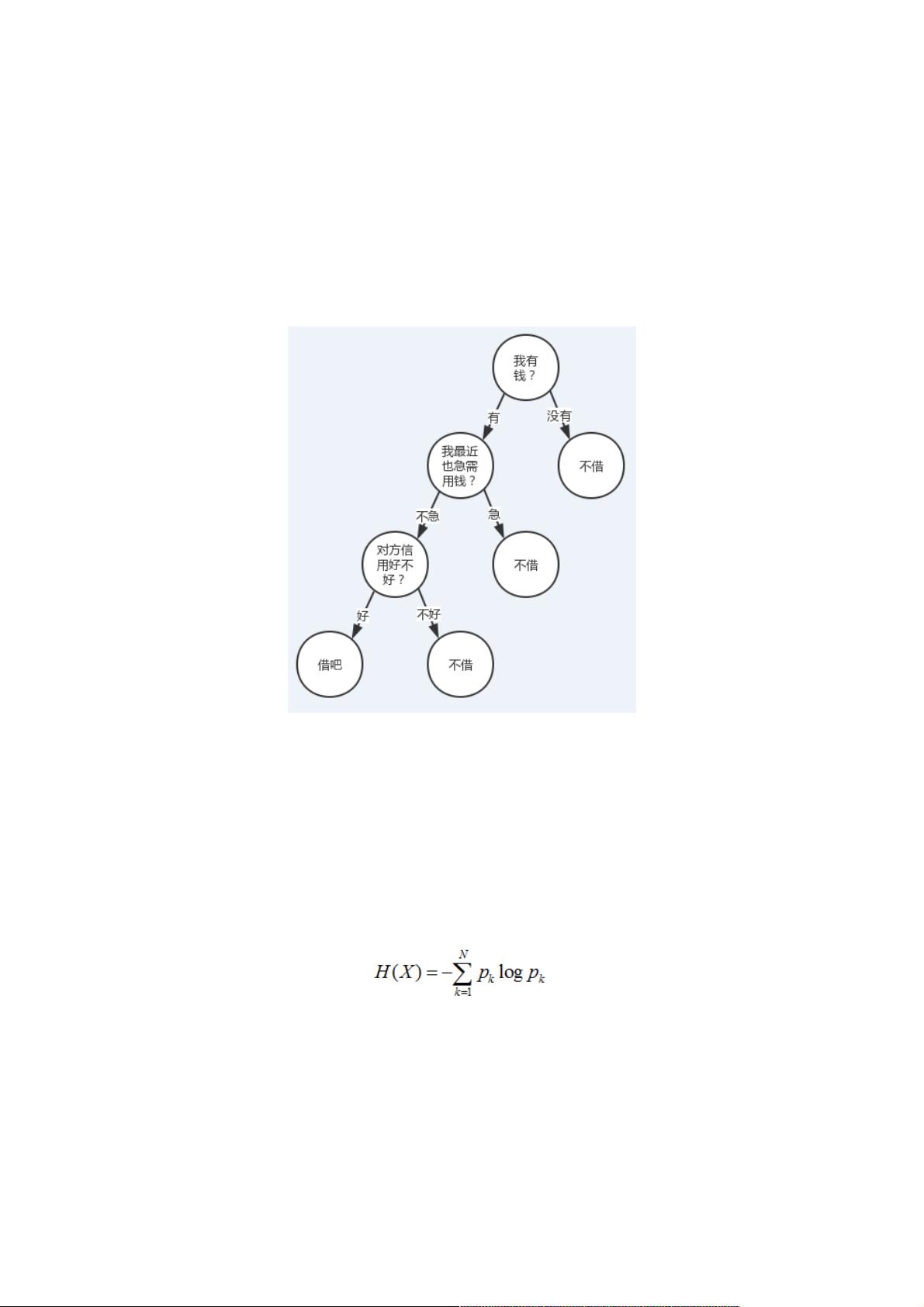
有人找我借钱(当然不太可能。。。),借还是不借?我会结合根据我自己有没有钱、我自己用不用钱、对方信用好不好这三
个特征来决定我的答案。
我们把转到更普遍一点的视角,对于一些有特征的数据,如果我们能够有这么一颗决策树,我们也就能非常容易地预测样本的
结论。所以问题就转换成怎么求一颗合适的决策树,也就是怎么对这些特征进行排序。
在对特征排序前先设想一下,对某一个特征进行决策时,我们肯定希望分类后样本的纯度越高越好,也就是说分支结点的样本
尽可能属于同一类别。
所以在选择根节点的时候,我们应该选择能够使得“分支结点纯度最高”的那个特征。在处理完根节点后,对于其分支节点,继
续套用根节点的思想不断递归,这样就能形成一颗树。这其实也是贪心算法的基本思想。那怎么量化“纯度最高”呢?熵就当仁
不让了,它是我们最常用的度量纯度的指标。其数学表达式如下:
其中N表示结论有多少种可能取值,p表示在取第k个值的时候发生的概率,对于样本而言就是发生的频率/总个数。
熵越小,说明样本越纯。
以一个两点分布样本X(x=0或1)的熵的函数图像来说明吧,横坐标表示样本值为1的概率,纵坐标表示熵。
下载后可阅读完整内容,剩余5页未读,立即下载
2021-09-29 上传
2018-11-21 上传
点击了解资源详情
点击了解资源详情
2020-12-22 上传
2019-09-05 上传
2021-09-10 上传
2021-10-11 上传
2021-01-20 上传









