Google Bigtable:分布式结构化数据存储系统中文解析
需积分: 14 103 浏览量
更新于2024-07-23
收藏 2.39MB PDF 举报
“Google的Bigtable、GFS和MapReduce是云计算领域的经典论文,分别涉及分布式数据存储系统、大规模文件系统和并行数据处理模型。”
在云计算和大数据处理领域,Google的三大论文——Bigtable、GFS(Google File System)和MapReduce——具有深远的影响。这些技术是构建现代云服务和大规模数据处理平台的基础。
1. Bigtable:一个分布式的结构化数据存储系统
Bigtable是一种分布式NoSQL数据库,设计用于处理海量数据,可扩展到数千台服务器,存储PB级别的数据。它被广泛应用于Google的各种产品,如Web索引、Google Earth、Google Finance等。Bigtable的数据模型简洁,允许用户动态控制数据的分布和格式。其设计目标是灵活性、可扩展性、高性能和高可用性。Bigtable不支持完整的SQL关系数据模型,而是采用了一种列族模型,适合处理半结构化和非结构化数据。这种设计使得Bigtable在处理大规模数据时,既能支持高吞吐量的批处理,也能满足实时数据服务的需求。
2. GFS(Google File System):大规模文件系统
GFS是Google为解决超大规模数据存储和访问问题设计的分布式文件系统。它能够有效地管理并行处理大量数据的多个副本,确保数据的可靠性和可用性。GFS通过主服务器(Master Node)管理文件系统的元数据,而数据则分散存储在许多称为Chunkserver的节点上。这种设计使得GFS在处理大型文件时具有高并发读写能力,且能容忍硬件故障。
3. MapReduce:并行数据处理模型
MapReduce是一种编程模型,用于大规模数据集的并行计算。它将复杂的大数据处理任务分解为两个阶段:Map阶段和Reduce阶段。Map阶段将输入数据分割,应用函数生成中间键值对;Reduce阶段则将这些键值对进行聚合,生成最终结果。这种模型简化了编写处理海量数据的程序,并且能够自动在大量廉价服务器上并行执行,提高了处理效率。
这三篇论文共同展示了Google如何利用分布式系统解决大数据处理的挑战,为后来的Hadoop、Cassandra等开源项目提供了灵感和基础。这些技术不仅在Google内部广泛应用,也成为了现代云计算和大数据基础设施的重要组成部分。

个日志记录都有一个序列号,因此,在恢复的时候,Tablet服务器能够检测出并忽略掉那些由于线程切换
而导致的重复的记录。
Tablet
恢复提速
当Master服务器将一个Tablet从一个Tablet服务器移到另外一个Tablet服务器时,源Tablet服务器会对这
个Tablet做一次Minor Compaction。这个Compaction操作减少了Tablet服务器的日志文件中没有归并
的记录,从而减少了恢复的时间。Compaction完成之后,该服务器就停止为该Tablet提供服务。在卸载
Tablet之前,源Tablet服务器还会再做一次(通常会很快)Minor Compaction,以消除前面在一次压缩
过程中又产生的未归并的记录。第二次Minor Compaction完成以后,Tablet就可以被装载到新的Tablet
服务器上了,并且不需要从日志中进行恢复。
利用不变性
我们在使用Bigtable时,除了SSTable缓存之外的其它部分产生的SSTable都是不变的,我们可以利用这
一点对系统进行简化。例如,当从SSTable读取数据的时候,我们不必对文件系统访问操作进行同步。这
样一来,就可以非常高效的实现对行的并行操作。memtable是唯一一个能被读和写操作同时访问的可变
数据结构。为了减少在读操作时的竞争,我们对内存表采用COW(Copy-on-write)机制,这样就允许读写
操作并行执行。
因为SSTable是不变的,因此,我们可以把永久删除被标记为“删除”的数据的问题,转换成对废弃的
SSTable进行垃圾收集的问题了。每个Tablet的SSTable都在METADATA表中注册了。Master服务器采用
“标记-删除”的垃圾回收方式删除SSTable集合中废弃的SSTable【25】,METADATA表则保存了Root
SSTable的集合。
最后,SSTable的不变性使得分割Tablet的操作非常快捷。我们不必为每个分割出来的Tablet建立新的
SSTable集合,而是共享原来的Tablet的SSTable集合。
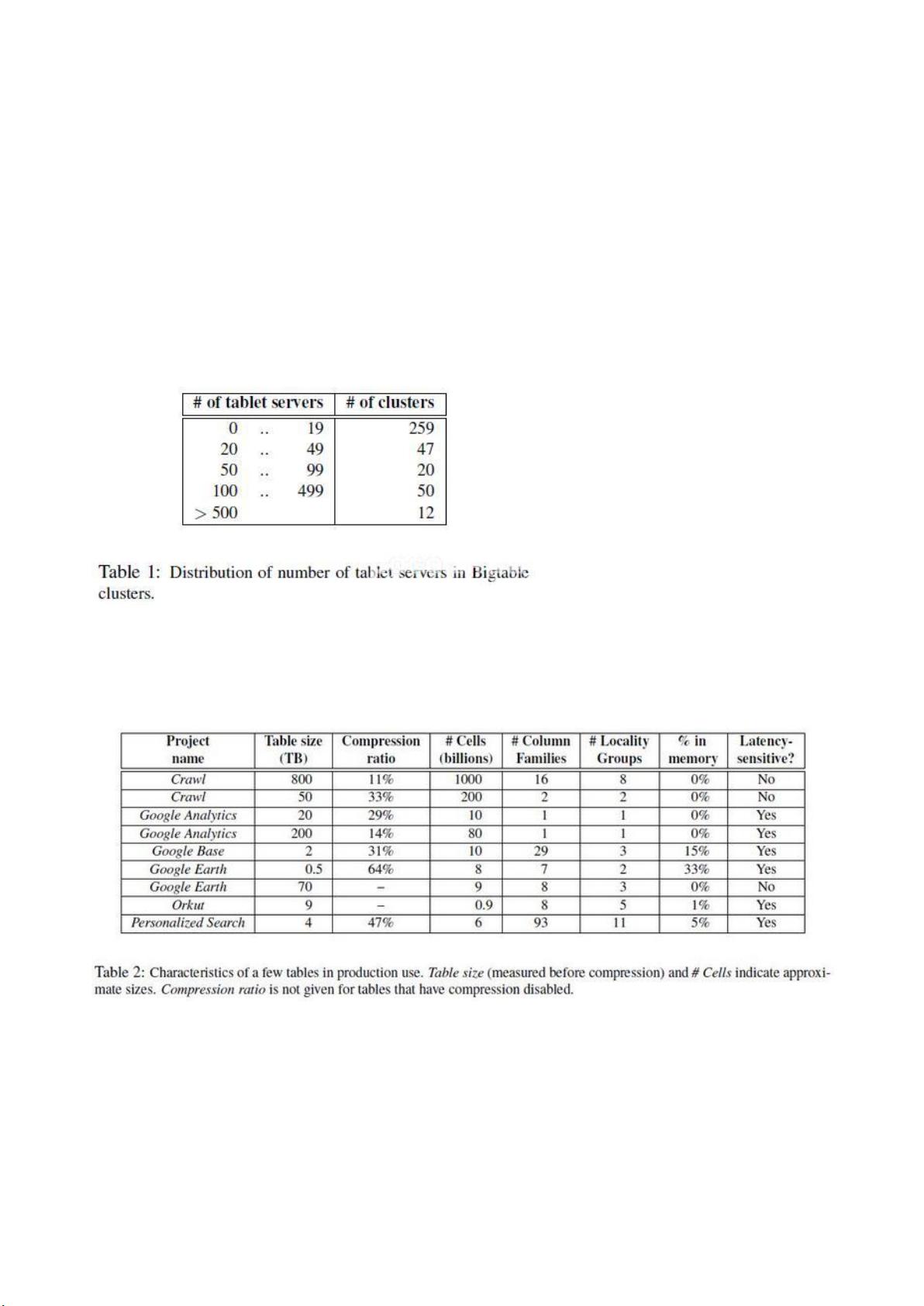
7 性能评估
为了测试Bigtable的性能和可扩展性,我们建立了一个包括N台Tablet服务器的Bigtable集群,这里N是可
变的。每台Tablet服务器配置了1GB的内存,数据写入到一个包括1786台机器、每台机器有2个IDE硬盘
的GFS集群上。我们使用N台客户机生成工作负载测试Bigtable。(我们使用和Tablet服务器相同数目的
客户机以确保客户机不会成为瓶颈。) 每台客户机配置2GZ双核Opteron处理器,配置了足以容纳所有进
程工作数据集的物理内存,以及一张Gigabit的以太网卡。这些机器都连入一个两层的、树状的交换网络
里,在根节点上的带宽加起来有大约100-200Gbps。所有的机器采用相同的设备,因此,任何两台机器
间网络来回一次的时间都小于1ms。
Tablet服务器、Master服务器、测试机、以及GFS服务器都运行在同一组机器上。每台机器都运行一个
GFS的服务器。其它的机器要么运行Tablet服务器、要么运行客户程序、要么运行在测试过程中,使用这
组机器的其它的任务启动的进程。
R是测试过程中,Bigtable包含的不同的列关键字的数量。我们精心选择R的值,保证每次基准测试对每台
Tablet服务器读/写的数据量都在1GB左右。
在序列写的基准测试中,我们使用的列关键字的范围是0到R-1。这个范围又被划分为10N个大小相同的区
间。核心调度程序把这些区间分配给N个客户端,分配方式是:只要客户程序处理完上一个区间的数据,
调度程序就把后续的、尚未处理的区间分配给它。这种动态分配的方式有助于减少客户机上同时运行的其
它进程对性能的影响。我们在每个列关键字下写入一个单独的字符串。每个字符串都是随机生成的、因此
也没有被压缩
(
alex
注:参考第
6
节的压缩小节)
。另外,不同列关键字下的字符串也是不同的,因此也
就不存在跨行的压缩。随机写入基准测试采用类似的方法,除了行关键字在写入前先做Hash,Hash采用
按R取模的方式,这样就保证了在整个基准测试持续的时间内,写入的工作负载均匀的分布在列存储空间
内。
序列读的基准测试生成列关键字的方式与序列写相同,不同于序列写在列关键字下写入字符串的是,序列

剩余59页未读,继续阅读
2017-05-03 上传
2013-08-27 上传
2021-06-06 上传
点击了解资源详情
点击了解资源详情
2011-04-08 上传

尘世伴读小书童
- 粉丝: 7
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
