Kafka权威指南:NehaNarkhede, GwenShapira & ToddPalino 联合力作
《Kafka:权威指南》是由NehaNarkhede、Gwen Shapira和Todd Palino共同编著的一本专业书籍,它深入探讨了Apache Kafka这个强大的分布式流处理平台。该书作为《The Definitive Guide》系列的一部分,旨在为读者提供全面而详尽的知识,涵盖了Kafka的设计理念、架构、工作原理、部署与管理,以及在现代数据处理场景中的应用实践。
本书不仅适合Kafka的初学者,对于已经在技术栈中使用或计划引入Kafka的专业人士同样具有价值。作者们凭借丰富的实战经验和深厚的技术底蕴,将Kafka的核心概念如主题(Topic)、生产者(Producer)、消费者(Consumer)和消息队列模型(Message Queueing)等进行了深入剖析。读者可以从中了解到Kafka如何实现实时数据的高效传输和处理,其分区(Partitioning)、复制(Replication)和高可用性设计,以及如何利用Kafka与其他技术(如Spark Streaming、Flume等)集成构建复杂的数据管道。
《Kafka:权威指南》还提供了关于Kafka最佳实践、性能调优和故障恢复策略的实用建议,帮助读者更好地理解和应对Kafka在大规模实时数据处理中的挑战。此外,书中还包含了最新的Kafka版本(如2.x和3.x)特性介绍,确保信息的时效性和实用性。
该书的版权信息表明,版权所有,未经许可不得复制或商业使用,且强调了在线版本的购买和获取途径。出版商O'Reilly Media对本书进行了严格的编辑、校对和设计,确保了内容的质量。书中的修订历史记录了自首次早期发布以来的更新情况,便于读者跟踪最新内容。
《Kafka:权威指南》是一本不可或缺的参考书籍,无论你是希望深入了解Kafka的开发者、系统管理员还是数据工程师,都将从这本书中收获丰富的理论知识和实践经验,以便在实际项目中充分利用Kafka的潜力。
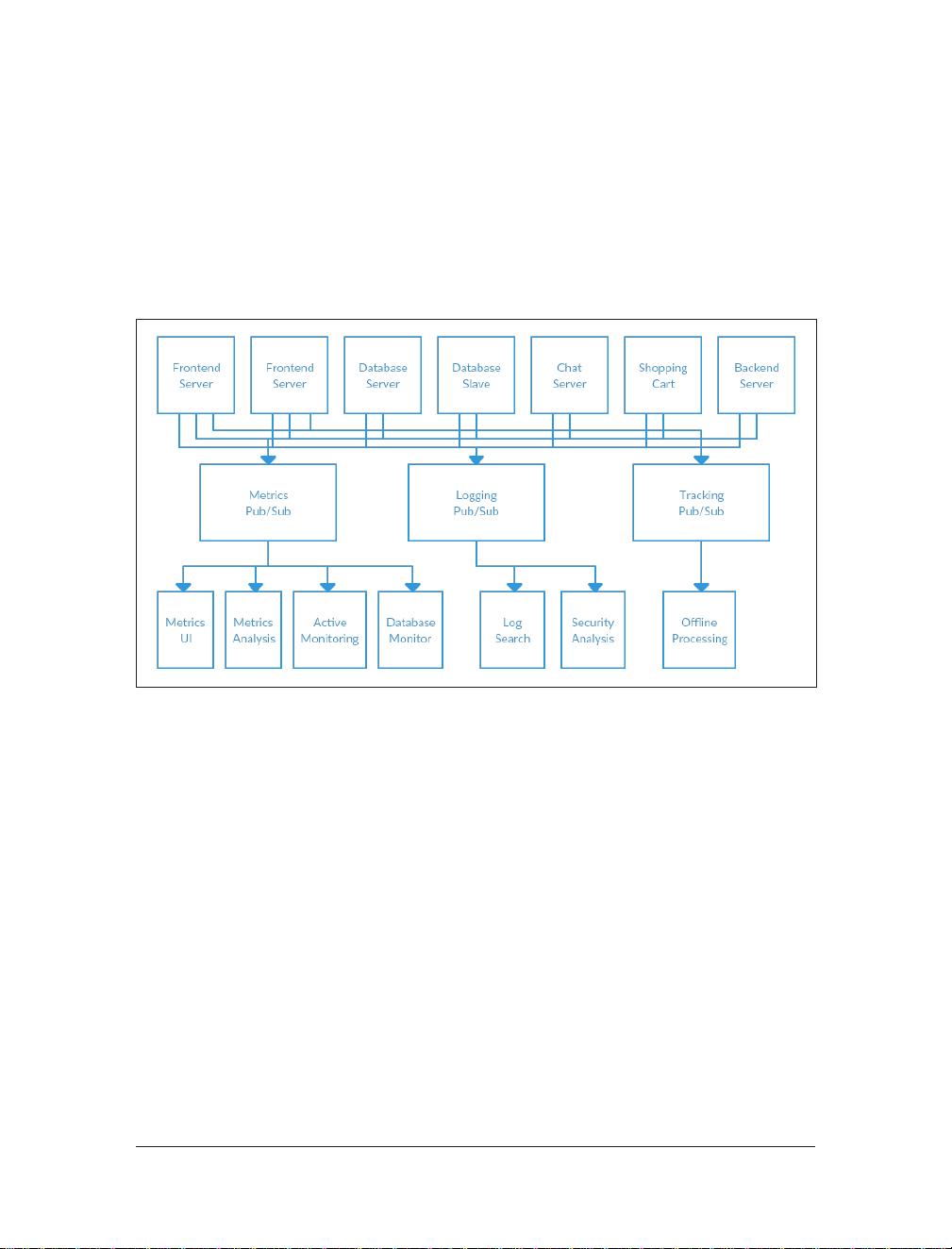
Individual Queue Systems
At the same time that you have been waging this war with metrics, one of your cow‐
orkers has been doing similar work with log messages. Another has been working on
tracking user behavior on the front-end website and providing that information to
developers who are working on machine learning, as well as creating some reports for
management. You have all followed a similar path of building out systems that decou‐
ple the publishers of the information from the subscribers to that information. Figure
1-4 shows such an infrastructure, with three separate pub/sub systems.
Figure 1-4. Multiple publish/subscribe systems
This is certainly a lot better than utilizing point to point connections (as in Figure
1-2), but there is a lot of duplication. Your company is maintaining multiple systems
for queuing data, all of which have their own individual bugs and limitations. You
also know that there will be more use cases for messaging coming soon. What you
would like to have is a single centralized system that allows for publishing of generic
types of data, and that will grow as your business grows.
Enter Kafka
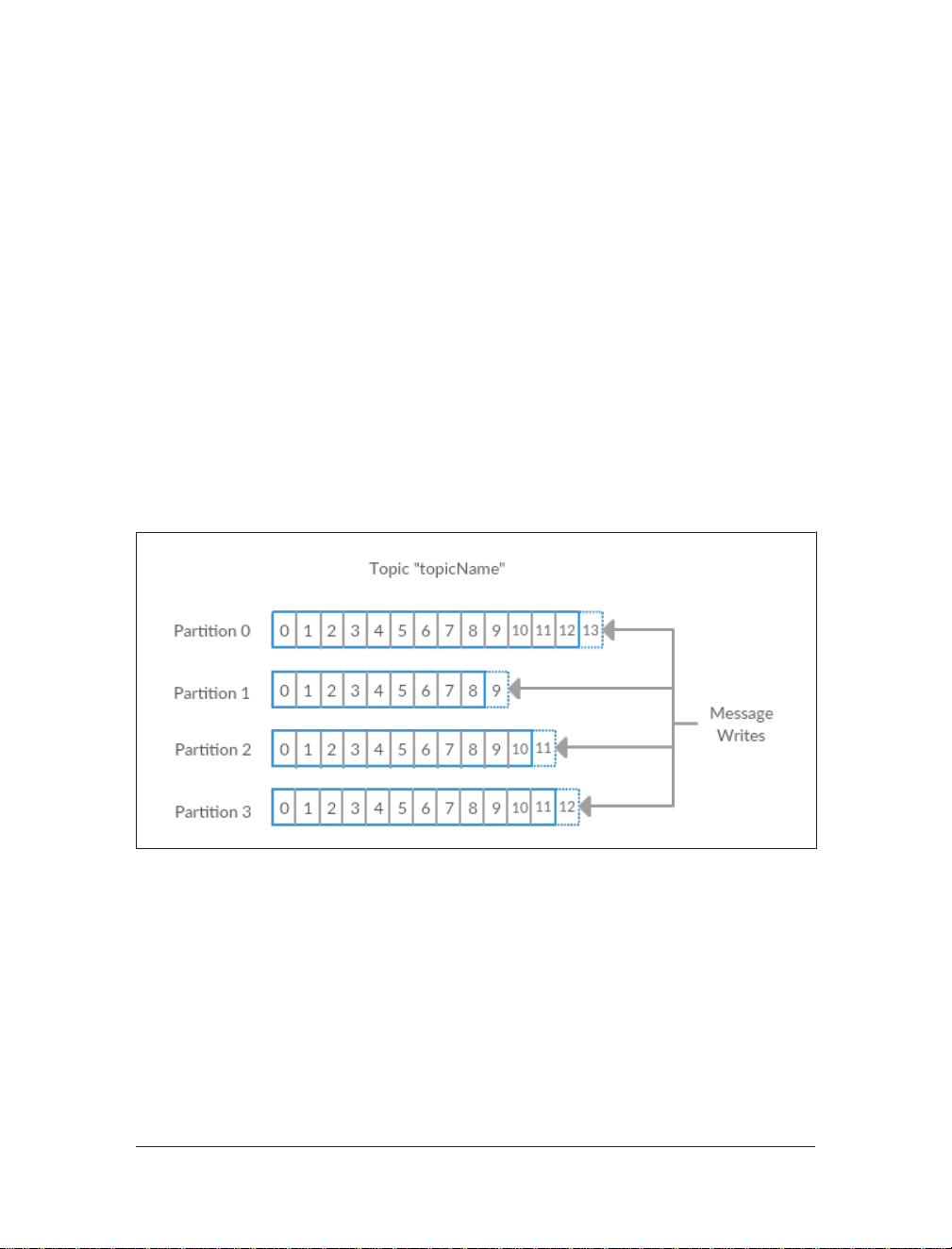
Apache Kafka is a publish/subscribe messaging system designed to solve this prob‐
lem. It is often described as a “distributed commit log”. A filesystem or database com‐
mit log is designed to provide a durable record of all transactions so that they can be
replayed to consistently build the state of a system. Similarly, data within Kafka is
stored durably, in order, and can be read deterministically. In addition, the data can
14 | Chapter 1: Meet Kafka


剩余117页未读,继续阅读
185 浏览量
223 浏览量
107 浏览量
125 浏览量
111 浏览量
2018-06-15 上传

苏州一点红
- 粉丝: 2
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- 相册展示类CSS模板-相册 展示 相片 黑色.rar
- 智慧交通综合管控解决方案.zip
- DT:jQuery插件数据表的R接口
- HFS模板_HFS模板_
- disparity
- Windows下预览SVG图片扩展包
- soe:埃拉托色尼筛法的实现
- modules-huds0n-inheriter
- potrace.js:Potrace矢量跟踪库Emscripten'd到JS中
- 基于C++的回溯法解决旅行售货员(TSP)问题.zip
- cgiirc:CGI:IRC基于Web的IRC客户端
- 智慧交通建设方案.zip
- L2-L4-2014_Matlab程序设计学习-1_
- Spring5Lab3
- 结露测试
- 3D-face-procedural-generations:3D人脸的程序生成
