Double-Array Trie: 实现与敏感词过滤
需积分: 10 31 浏览量
更新于2024-09-12
收藏 304KB PDF 举报
"这篇文档主要介绍了Double-Array Trie(双数组字典树)的实现和应用,这是一种用于敏感词过滤系统的高效算法。文档包含了对Trie树的基本概念、实现原理、以及Double-Array Trie、Triple-Array Trie、后缀压缩、键插入、键删除等关键操作的详细讲解。"
在计算机科学中,Trie(发音类似“try”),又称为前缀树或字典树,是一种用于高效存储和检索字符串的数据结构。Trie是由Don Knuth在1972年详细介绍的数字搜索树类型,而“Trie”这个术语由Edward Fredkin于1960年提出,源自“检索”一词的缩写。Trie树是一种确定性的有限状态自动机(Deterministic Finite Automaton, DFA),其中每个节点对应DFA的一个状态,每条从父节点到子节点的有向边则代表一个DFA的转移。
在Trie树中,从根节点开始,通过沿着与输入字符串字符匹配的边进行遍历来寻找字符串。对于给定的键字符串,从第一个字符到最后一个字符,每次根据当前字符选择相应的边来移动到下一个状态。这样,通过遍历树结构,可以快速查找是否存在某个字符串或者进行字符串前缀的查找。
Double-Array Trie是Trie的一种优化实现,由两数组表示,它提高了空间效率和插入、删除操作的性能。相比于传统的单数组Trie,Double-Array Trie在存储结构上做了改进,使用两个数组分别记录字符位置和子节点索引,使得插入和删除操作更加高效,同时降低了空间开销。
文档中还提到了Triple-Array Trie,这是一种更为复杂但可能更节省空间的Trie实现方式。后缀压缩(Suffix Compression)是优化Trie结构的另一种技术,通过减少具有相同后缀的节点数量来减小空间需求。
此外,Key Insertion和Key Deletion是Trie操作的核心部分。Key Insertion涉及到如何在Trie中插入新的字符串,确保数据结构的完整性;而Key Deletion则涉及如何从Trie中安全地移除某个已存在的字符串,同时保持其他字符串的可访问性。
Double-Array Pool Allocation是Double-Array Trie中的内存管理策略,目的是优化内存分配和减少碎片化。
最后,文档中还提到了一个具体的Double-Array Trie实现的下载链接和其他实现参考,供读者进一步研究和实践。
Double-Array Trie是一种适用于敏感词过滤系统的高效算法,其结构和操作策略优化了字符串的查找和管理,对于处理大量词汇的数据过滤场景具有显著优势。
13-4-22 An Implementation of Double-Array Trie
3/12linux.thai.net/~thep/datrie/#Others
table.
2. next.Thisarray,incoordinationwithcheck,providesapoolfortheallocationofthesparsevectorsfor
therowsinthetrietransitiontable.Thevectordata,thatis,thevectoroftransitionsfromeverynode,
wouldbestoredinthisarray.
3. check.Thisarrayworksinparalleltonext.Itmarkstheownerofeverycellinnext.Thisallowsthe
cellsnexttooneanothertobeallocatedtodifferenttrienodes.Thatmeansthesparsevectorsof
transitionsfrommorethanonenodeareallowedtobeoverlapped.
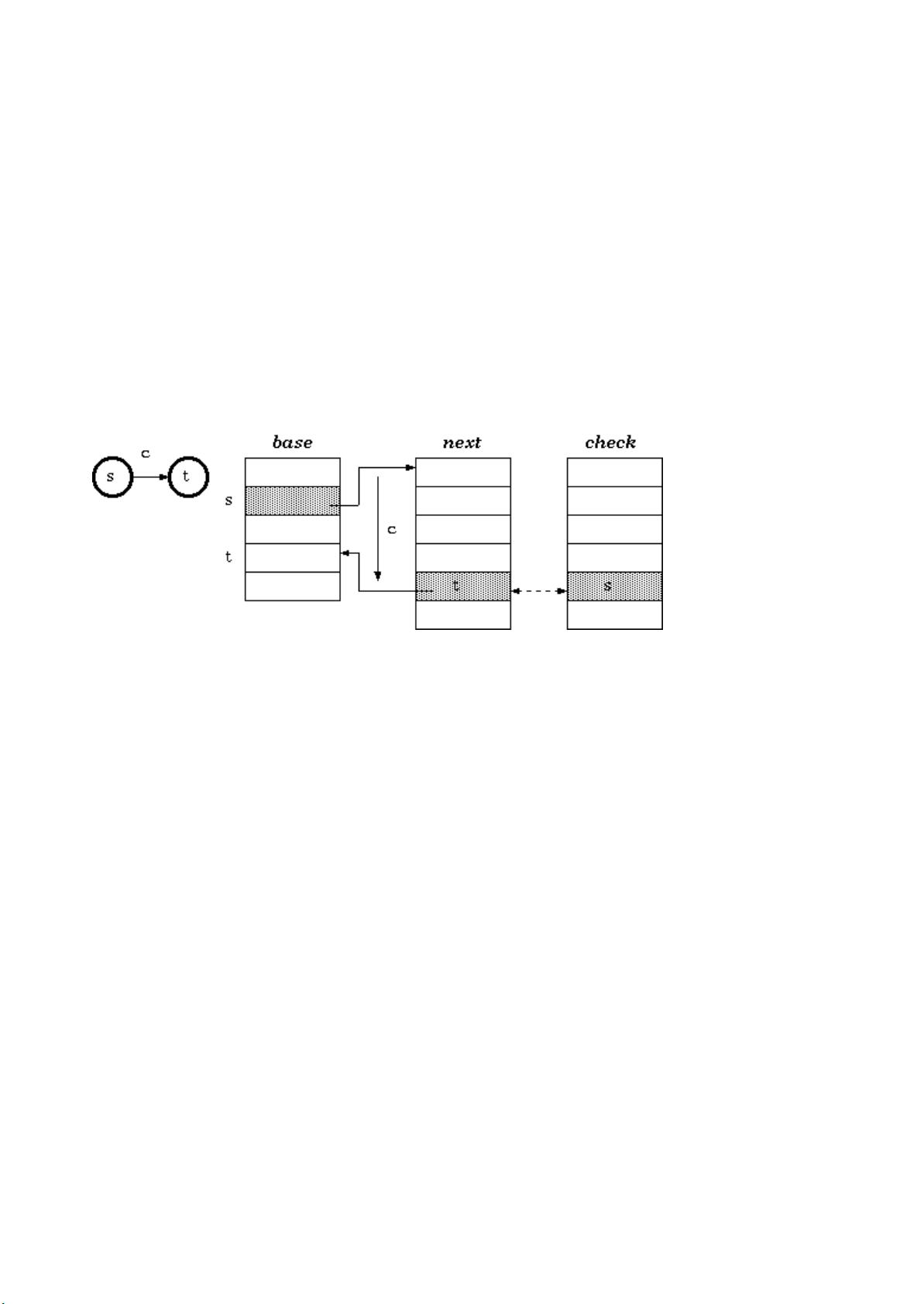
Definition1.Foratransitionfromstatestotwhichtakescharactercastheinput,the
conditionmaintainedinthetripplearraytrieis:
check[base[s]+c]=s
next[base[s]+c]=t
Walking
Accordingtodefinition1,thewalkingalgorithmforagivenstatesandtheinputcharactercis:
t:=base[s]+c;
ifcheck[t]=sthen
nextstate:=next[t]
else
fail
endif
Construction
Toinsertatransitionthattakescharacterctotraversefromastatestoanotherstatet,thecell
next[base[s]+c]]mustbemanagedtobeavailable.Ifitisalreadyvacant,wearelucky.Otherwise,eitherthe
entiretransitionvectorforthecurrentownerofthecellorthatofthestatesitselfmustberelocated.The
estimatedcostforeachcasecoulddeterminewhichonetomove.Afterfindingthefreeslotstoplacethe
vector,thetransitionvectormustberecalculatedasfollows.Assumingthenewplacebeginsatb,the
procedurefortherelocationis:
ProcedureRelocate(s:state;b:base_index)
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-09-20 上传
2021-03-11 上传
2021-05-09 上传
2022-07-12 上传
2021-04-24 上传
2013-01-06 上传

tangc08
- 粉丝: 0
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 正整数数组验证库:确保值符合正整数规则
- 系统移植工具集:镜像、工具链及其他必备软件包
- 掌握JavaScript加密技术:客户端加密核心要点
- AWS环境下Java应用的构建与优化指南
- Grav插件动态调整上传图像大小提高性能
- InversifyJS示例应用:演示OOP与依赖注入
- Laravel与Workerman构建PHP WebSocket即时通讯解决方案
- 前端开发利器:SPRjs快速粘合JavaScript文件脚本
- Windows平台RNNoise演示及编译方法说明
- GitHub Action实现站点自动化部署到网格环境
- Delphi实现磁盘容量检测与柱状图展示
- 亲测可用的简易微信抽奖小程序源码分享
- 如何利用JD抢单助手提升秒杀成功率
- 快速部署WordPress:使用Docker和generator-docker-wordpress
- 探索多功能计算器:日志记录与数据转换能力
- WearableSensing: 使用Java连接Zephyr Bioharness数据到服务器
