深度学习技术详解:前馈、卷积与循环网络
需积分: 9 112 浏览量
更新于2024-07-18
收藏 1.55MB PDF 举报
"这篇论文是深度学习领域的一个技术性介绍,涵盖了深度神经网络(DNN)的三个核心组件:前馈神经网络、卷积神经网络(CNN)和循环神经网络(RNN)。它深入探讨了这些网络的结构、工作原理以及优化算法。论文中包含了输入卷积层和输出卷积层的示例,还展示了ReLU激活函数及其导数的图形表示,以及神经网络中的隐藏层和输出层的结构。"
在深度学习中,前馈神经网络(Feedforward Neural Network,FNN)是最基础的模型,它由多层非循环节点组成,信息沿单一方向传递,从输入层到隐藏层,再到输出层,没有反馈路径。每个节点都包含一个激活函数,如sigmoid、tanh或ReLU,用于引入非线性特性。
卷积神经网络(Convolutional Neural Network,CNN)是图像处理和计算机视觉任务中的主力模型。CNN的核心特点是卷积层,如InputConvolutionLayer和OutputConvolutionLayer所示。卷积层通过滤波器(Filter)对输入数据进行扫描,滤波器大小通常为F×F,滑动步长(Stride)为S,填充(Padding)为P,用于保持输出尺寸与输入相似。每个滤波器会产生一个特征映射(Feature Map),多个滤波器可以捕获不同的特征。
循环神经网络(Recurrent Neural Network,RNN)则适用于处理序列数据,如文本和时间序列数据。RNN的特点是其内部状态会随时间变化,允许信息在时间维度上流动。在RNN的每个时间步长τ,都有一个隐藏状态h(τ),它可以记住过去的信息,并影响当前的输出。长短期记忆网络(LSTM)和门控循环单元(GRU)是RNN的改进版本,解决了传统RNN的梯度消失问题,增强了对长期依赖的捕捉能力。
在训练神经网络时,反向传播(Backpropagation)算法用于计算损失函数关于权重的梯度,以便进行权重更新。优化算法,如梯度下降、随机梯度下降(SGD)、动量法、Adagrad、RMSprop和Adam等,用于控制权重更新的方向和幅度,以最小化损失函数并提高模型性能。
论文还可能涉及到权重初始化、批量归一化(Batch Normalization)、dropout等技术,以减少过拟合,提高模型泛化能力。最后,可能会讨论如何调整超参数,如学习率、批次大小和网络层数,以优化训练过程。
这篇论文提供了深度学习的全面概述,对于理解和应用深度学习模型至关重要。无论是初学者还是经验丰富的研究者,都能从中受益,掌握深度学习的关键概念和技术。
16 CHAPTER 4. FEEDFORWARD NEURAL NETWORKS
Its derivative is
σ
0
(x) = σ(x)
(
1 − σ(x)
)
. (4.4)
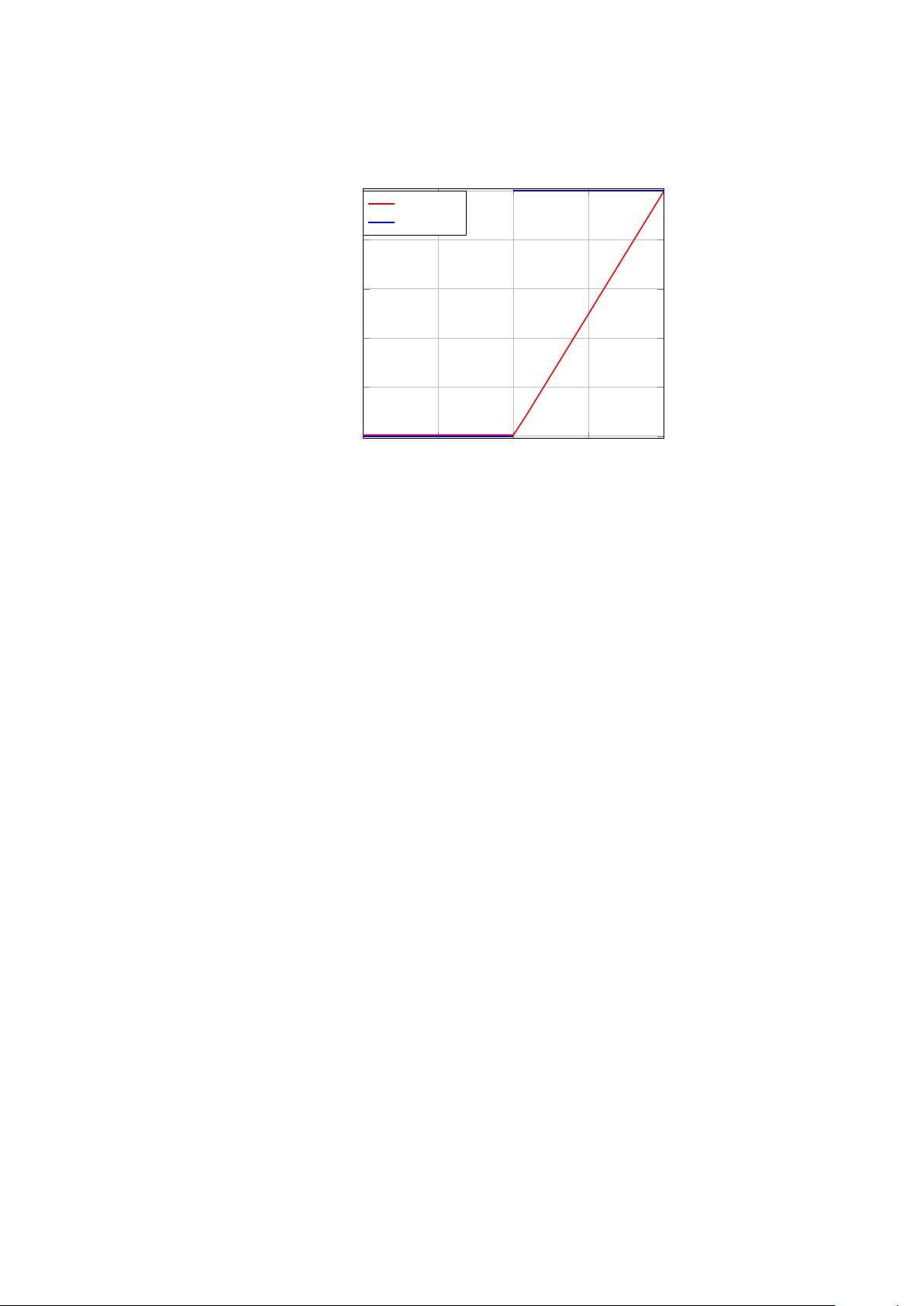
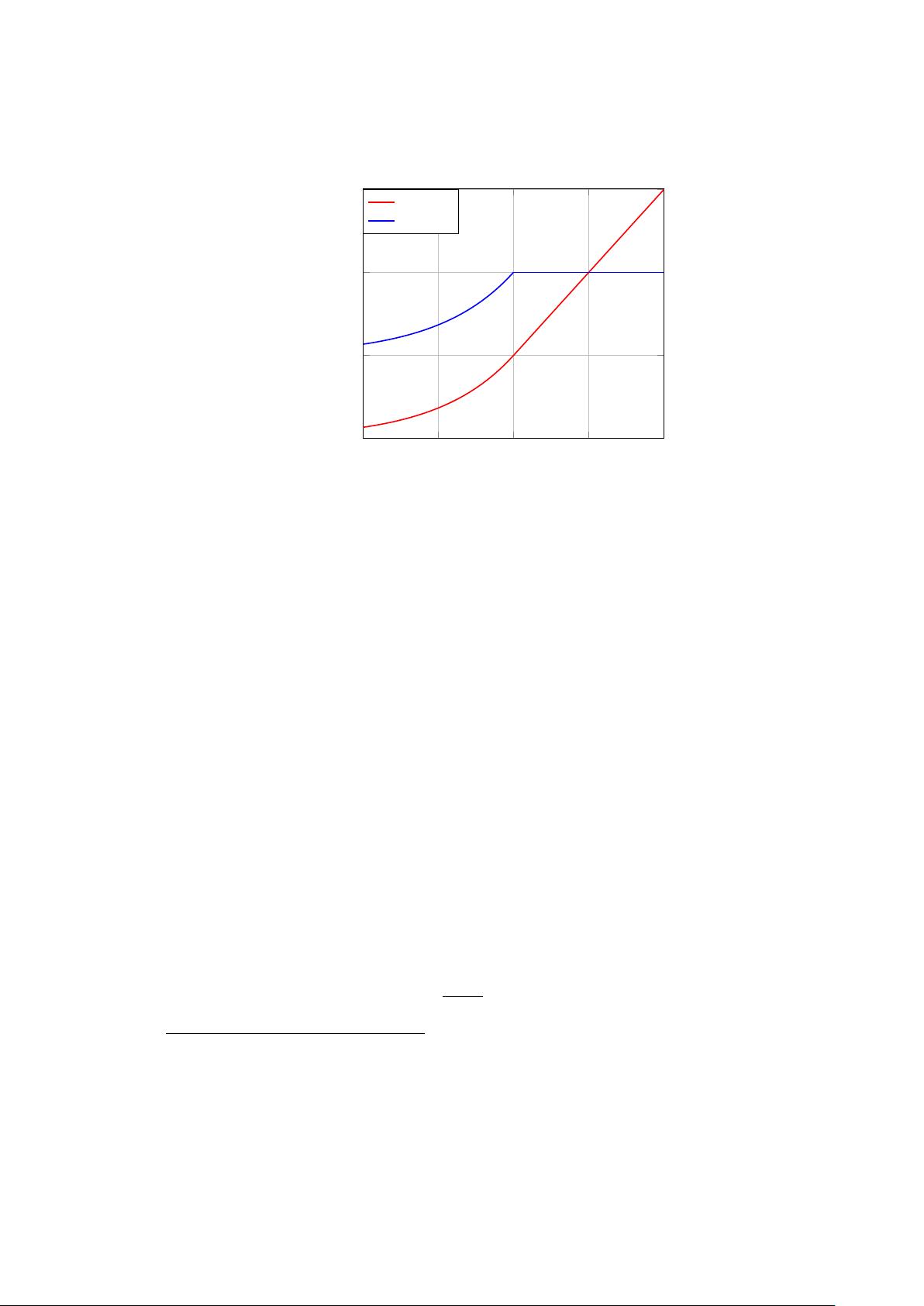
This activation function is not much used nowadays (except in RNN-LSTM
networks that we will present later in chapter 6).
−10 −5 0 5 10
0
0.2
0.4
0.6
0.8
1
x
σ(x)
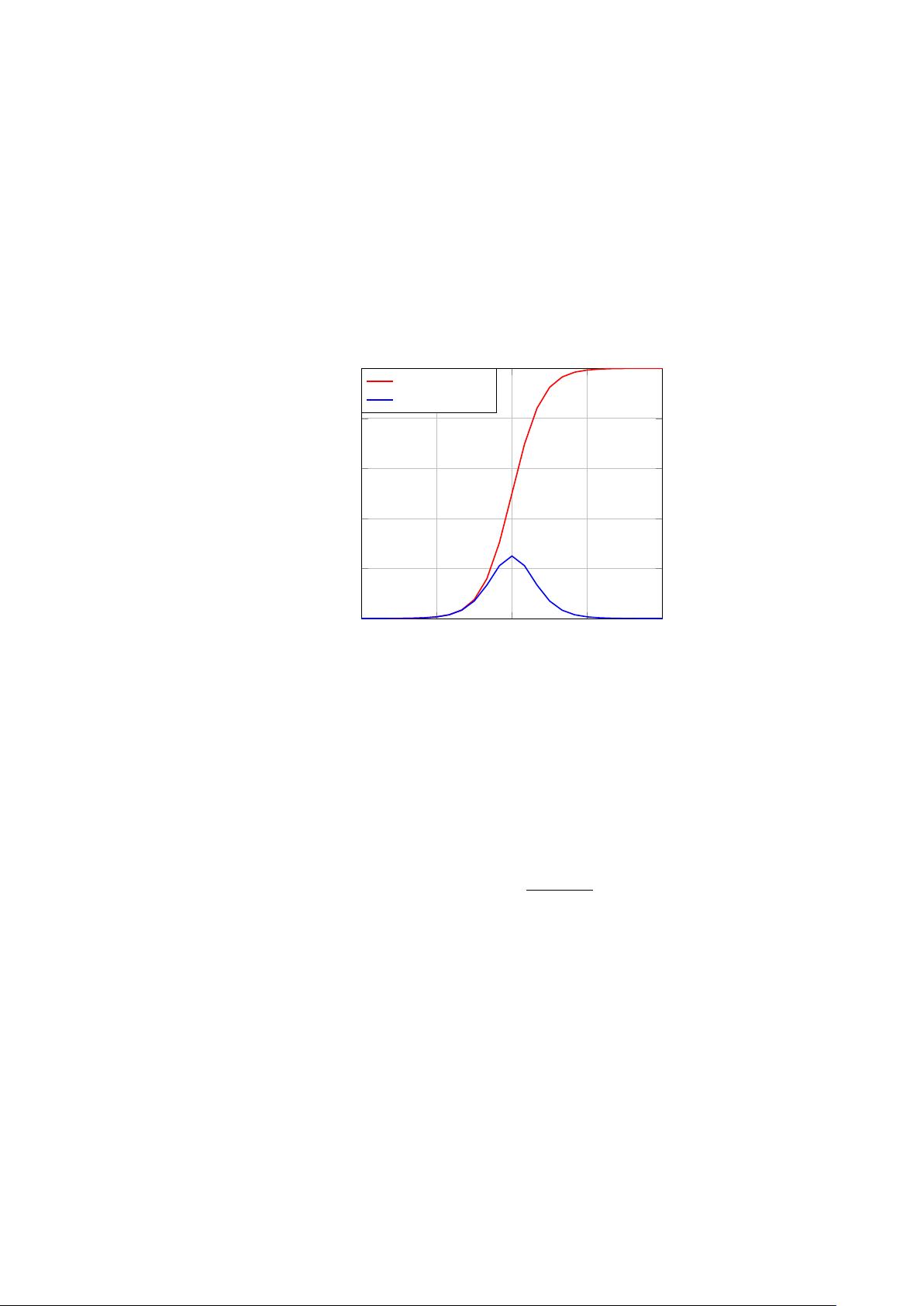
Sigmoid function and its derivative
σ(x)
σ(x)(1 − σ(x))
Figure 4.3: the sigmoid function and its derivative.
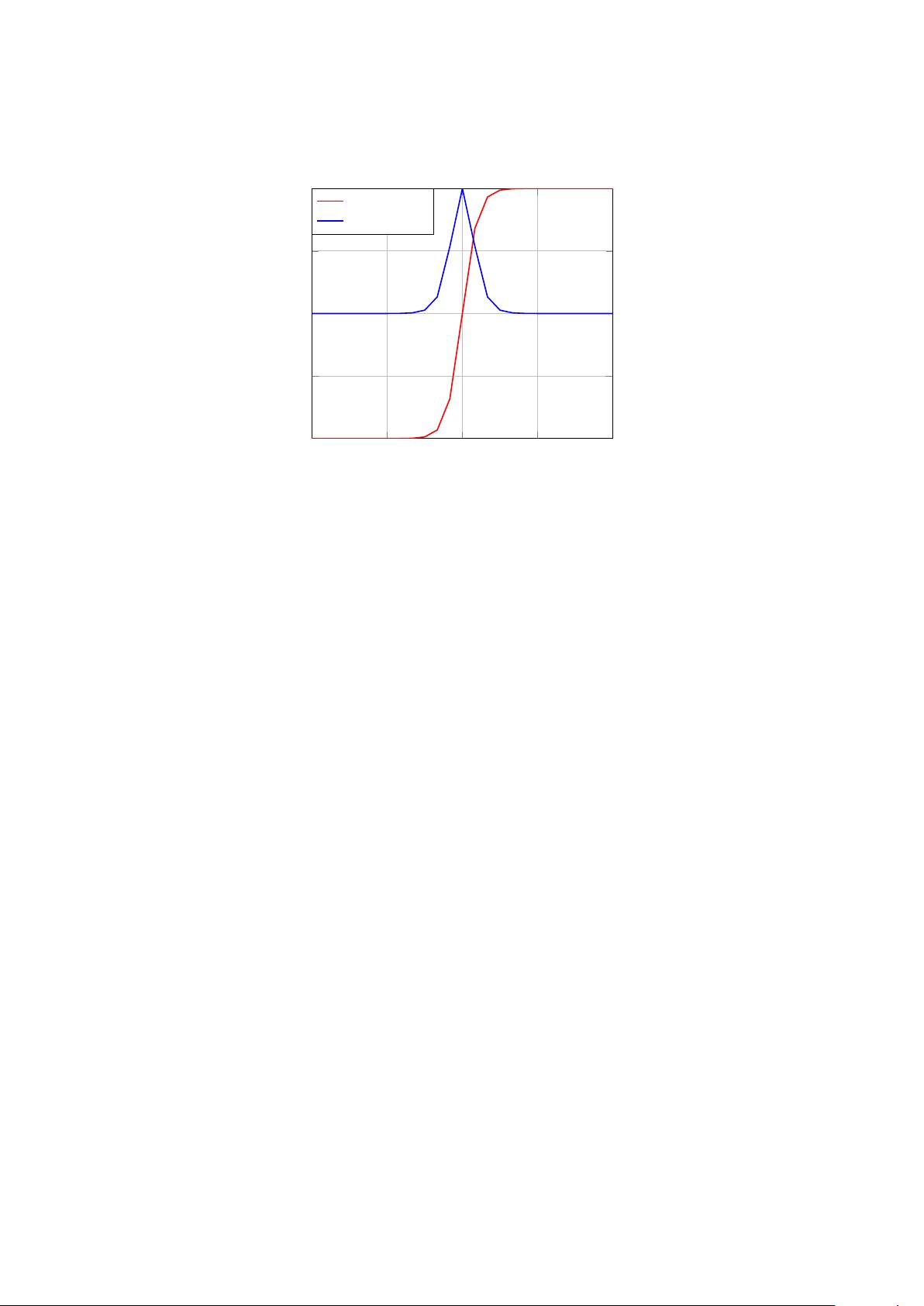
4.5.2 The tanh function
the tanh function takes its value in ] −1, 1[ and reads
g(x) = tanh(x) =
1 − e
−2x
1 + e
−2x
. (4.5)
Its derivative is
tanh
0
(x) = 1 −tanh
2
(x) . (4.6)
This activation function has seen its popularity drop due to the use of the
activation function presented in the next section.

剩余105页未读,继续阅读
2017-09-28 上传
2022-07-03 上传
2021-10-04 上传
2021-01-07 上传
2022-07-15 上传
2021-04-29 上传
2021-10-11 上传
2021-10-02 上传

top_geek_001
- 粉丝: 198
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
