Flume架构详解与日志采集实践
44 浏览量
更新于2024-08-29
收藏 462KB PDF 举报
Flume架构以及应用介绍
在大数据处理的背景下,数据采集是一个至关重要的环节,尤其在Hadoop生态系统中。Flume作为一个专为日志收集设计的分布式系统,它的出现解决了大规模数据流的高效传输问题。本文首先通过Hadoop业务开发流程图,强调了数据采集在业务流程中的关键作用,从而引出Flume这一主角。
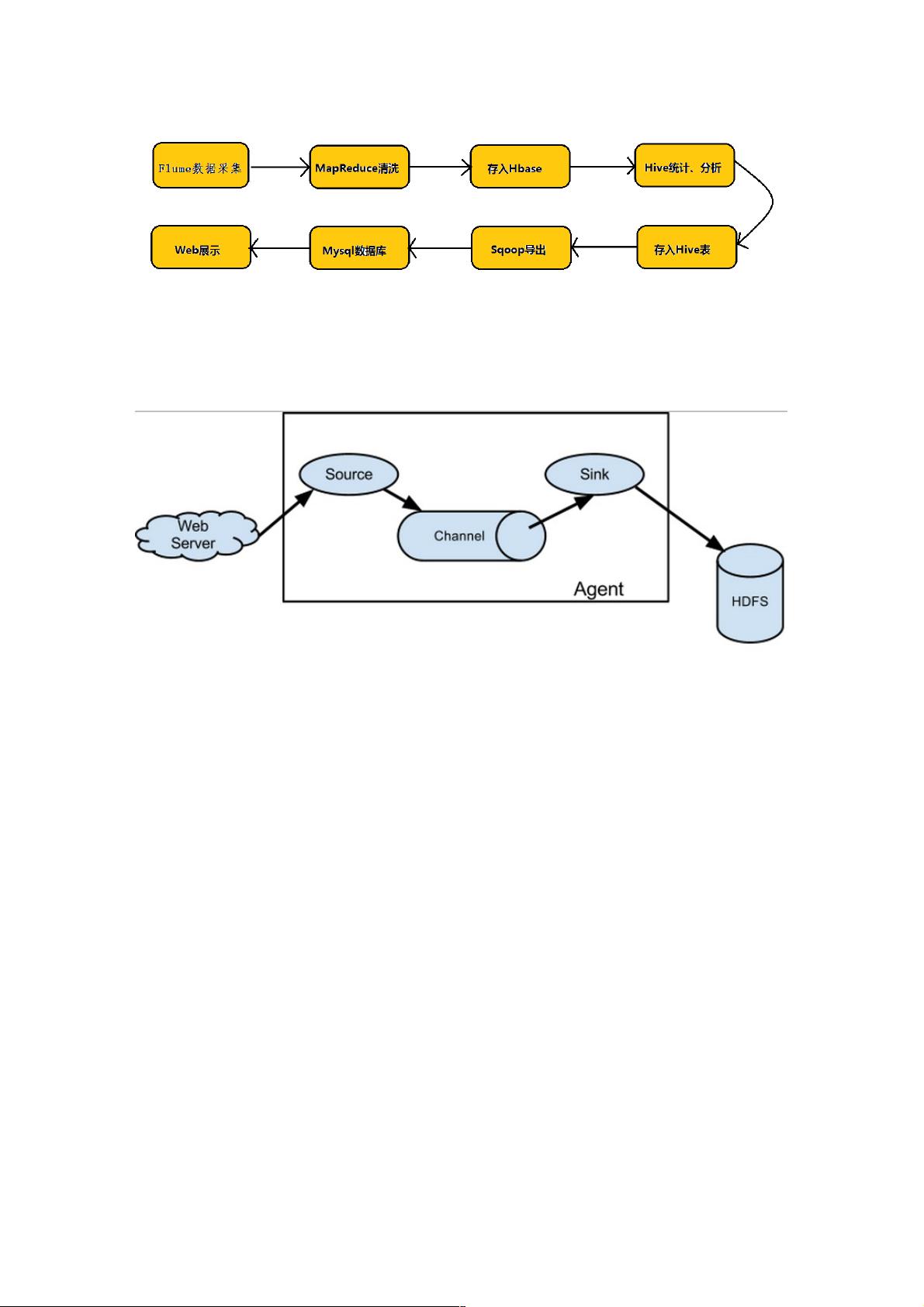
Flume的核心架构基于三个主要组件:Source、Channel和Sink,它们构成了一个类似于生产者-缓冲区-消费者的模型。Source负责从各种数据源(如Avro、Thrift、执行命令、JMS或Spoolingd等)收集数据,这里的Source是数据的"生产者",它根据特定协议解析并包装数据为Flume的事件(Event)形式。Event是Flume传输的基本单元,它封装了数据和相关的元信息(headers),保证数据在从源头到目标地的过程中保持完整性。
Event不仅包含原始的数据内容(event body,即文本文件中的单行记录),还带有事件头部信息(event headers),这些头部信息提供了额外的上下文和元数据。Event在被收集后,存储在Channel中,这是一个临时的缓冲区域,起到数据暂存的作用,直到Sink接收并处理完数据后,Event才会从Channel中移除。
Channel的设计允许Flume在数据传输过程中处理可能的故障情况,比如网络中断或节点失败,通过重试机制确保数据最终送达目的地。Sink则是数据的"消费者",它可以将Event发送到不同的目的地,如HDFS、Kafka或者数据库,甚至是其他Flume集群,实现了数据的可靠传输。
Flume的Agent设计使得它能够在分布式环境中部署,每个服务器节点上运行一个Agent实例,专门负责该节点的日志收集任务。这种模块化的设计使得Flume易于扩展和维护,能够适应各种复杂的日志监控和分析场景。
总结来说,本文详细介绍了Flume的架构特点,特别是其事件驱动的数据传输方式,以及如何通过Source、Channel和Sink组件有效地处理日志数据,无论是作为独立的日志收集工具,还是与Hadoop生态系统中的其他组件协同工作,Flume都扮演着重要角色,确保了大数据处理过程中的数据完整性和可靠性。
Flume架构以及应用介绍架构以及应用介绍
在具体介绍本文内容之前,先给大家看一下Hadoop业务的整体开发流程:
从Hadoop的业务开发流程图中可以看出,在大数据的业务处理过程中,对于数据的采集是十分重要的一步,也是不可避免的
一步,从而引出我们本文的主角—Flume。本文将围绕Flume的架构、Flume的应用(日志采集)进行详细的介绍。
(一)Flume架构介绍
1、Flume的概念
flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到图中的HDFS,简单来
说flume就是收集日志的。
2、Event的概念
在这里有必要先介绍一下flume中event的相关概念:flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到
指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的
地(sink)后,flume在删除自己缓存的数据。
在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。那么什么是event呢?—–event将传输的数
据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从
source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单
元,从外部数据源来,向外部的目的地去。
为了方便大家理解,给出一张event的数据流向图:
下载后可阅读完整内容,剩余6页未读,立即下载
117 浏览量
108 浏览量
363 浏览量
229 浏览量
点击了解资源详情
点击了解资源详情
109 浏览量
207 浏览量

weixin_38749863
- 粉丝: 3
- 资源: 912
 我的内容管理
展开
我的内容管理
展开







最新资源
- Progra2Tarea3:传承主题
- 《鼠小弟和大象哥哥》绘本故事PPT模板
- Testrepo
- 标志::Sweden:标志扩展使标志表情符号,图像
- gulp-createjs-example:这个 repo 是一个使用 gulp、easeljs、preloadjs 等的示例 repo。
- Grumpy Cat HD Wallpapers and New Tab-crx插件
- python代码自动办公 在Excel中按条件筛选数据并存入新的表项目源码有详细注解,适合新手一看就懂.rar
- BKacprzyk-营销页面
- Lummix
- rustorm:一个生锈的球
- 旅游图_dfs_bfs_
- python代码自动办公 excel处理实例(单工作表拆分到多工作表)项目源码有详细注解,适合新手一看就懂.rar
- heimdall:协同数据可视化和业务监控系统
- ExchangeOrb:此存储库不再活动 - 请参阅特定版本的存储库
- Swface-master.rar
- Pixel Apocalypse Infection Bio-crx插件
