4D人-对象交互模型:联合事件分割与识别及对象定位
180 浏览量
更新于2024-07-14
收藏 2.47MB PDF 举报
"这篇研究论文提出了一种4D人与对象交互(4D HOI)模型,用于同时解决视频事件分割、事件识别与解析以及上下文对象定位这三项视觉任务。该模型通过描绘人类动作与环境物体之间的几何、时间和语义关系,来表示日常事件中的交互行为。在3D空间中,它利用语义共现和几何兼容性来建模人类姿势和上下文物体的交互。在时间轴上,交互被表示为原子事件的连续转换,其中涉及的物体保持一致性。4D HOI模型是一种层次化的时空图表示形式,可以用于推断场景功能和对象的效用。通过有序期望最大化算法学习图结构和参数,最小化事件的时空结构,从而从RGB-D数据中提取这些信息。"
这篇论文的核心知识点包括:
1. **4D人与对象交互模型(4D HOI Model)**:这是一个创新的模型,旨在同时处理视频分析中的多个关键任务。它不仅关注人与物体的交互,还考虑了交互的时间演变和语义含义。
2. **事件分割(Event Segmentation)**:通过对视频序列进行分析,4D HOI模型能够识别出事件的起始和结束,将视频划分为不同的行为片段。
3. **事件识别与解析(Event Recognition and Parsing)**:模型能够理解事件的类型,并解析出事件中的具体动作和参与者,这对于理解和解释视频内容至关重要。
4. **上下文对象定位(Contextual Object Localization)**:利用人类交互的上下文信息,模型可以定位到与事件相关的物体,帮助理解人类行为的环境背景。
5. **3D空间交互建模**:通过语义共现和几何兼容性,模型在三维空间中捕获了人与物体交互的几何特征,增强了交互的准确性。
6. **时间轴上的原子事件过渡**:在时间维度上,模型捕捉了事件的连续变化,通过原子事件的转换来表示动态的交互过程。
7. **时空图表示(Spatial-Temporal Graph Representation)**:4D HOI模型采用层次化的时空图结构,这种表示方式有助于解析复杂的场景结构和事件关系。
8. **有序期望最大化算法(Ordered Expectation Maximization Algorithm)**:论文中使用的优化方法,用于学习图结构和参数,以最小化事件的时空结构,从而更准确地从RGB-D数据中提取信息。
9. **场景功能和对象效用推理(Scene Functionality and Object Affordance Inference)**:4D HOI模型能够推断场景的用途以及物体可以支持哪些动作,增强了模型的智能和应用场景的广泛性。
这篇论文提供了一个综合的框架,通过4D HOI模型来理解和描述视频中的复杂交互行为,对于视频理解、行为分析以及智能监控等领域具有重要意义。
2.2 Object Modeling and Localization
Many existing methods for object detection represent objects
with appearance [5], [6], [30], [31], such as HOG [5] features.
Lai et al. [6] extended the HOG features to RGB-D images.
Such features are often weakened by low resolution, heavy
occlusion, and large appearance variation. To solve such
problems, contextual information was introduced into object
modeling. The methods in [32] and [33] incorporated rela-
tions with other objects to improve detection or recognition.
Zhao and Zhu [9] defined objects by integrating function,
geometry, and appearance information. Gupta et al. [10]
extended object localization and recognition to human-cen-
tric scene understanding by inferring human and 3D scene
interactions. These methods aim at object detection or recog-
nition in still images.
Some studies aim at recognizing and localizing objects in
videos [15], [34]. Gupta et al. [34] labeled objects according
to human actions in videos. The method in [15] tracked
objects in each video frame. In comparison, our method
localizes objects in both 3D point clouds and 2D images,
and does not need accurate initialization of object locations.
2.3 Human-Object Interaction and Affordance
The concept of affordance was originally studied by Gibson
[7] and further developed by many studies to describe the
relations between organisms (humans) and environments
(objects) [35], [36], [37], [38], [39]. Many researchers have
recently applied human-object relations to event, object, and
scene modeling [10], [15], [34], [40], [41], [42], [43], [44], [45],
[46], [47], [48], [49], [50], [51]. Gupta et al. [34] combined spa-
tial and functional constraints between humans and objects
to recognize actions and objects. Prest et al. [44] inferred spa-
tial information of objects by modeling 2D geometric rela-
tions between human bodies and objects. Yao and Fei-
Fei [46] detected objects by modeling relations between
actions, objects, and poses in still images. These methods
define the human-object interactions in 2D images. Such con-
textual cues are often weakened by viewpoint change and
occlusion. Koppula et al. [15] modeled relations between
human activities and object affordance, and their changes
over time. This method requires videos to be pre-segmented,
and the object detection is independent of human actions.
Our model incorporates event recognition, segmentation,
and object localization into a unified framework, under
which these tasks mutually facilitate each other.
Human-object interactions are also used in robotics [52],
[53], [54]. Aksoy et al. [52] recognized manipulations by
learning object-action semantics. W
€
org
€
otter et al. [53] mod-
eled manipulation actions for robot task execution. This
stream of research demonstrates the significance of human-
object interactions from the perspective of robot learning
and task execution.
2.4 Action Structure Learning
Many existing approaches mine action structures by
explicitly modeling the latent structures [2], [4], [25],
[27], [55]. HMM [2] learned the hidden states a nd transi-
tion probabilities with maximum likelihood estimation.
Hidden conditional random fiel d (HCRF) [55] learned
the hidden structures of actions in a discriminative way.
These methods define the temporal structures on video
frames or fixed-size video segments, which can not effec-
tively characterize nor utilize the duration information of
hidden structures.
Yao and Fei-Fei [46] defined atomic poses in still images
and learned them through clustering human poses.
Zhou et al. [4] segmented an action sequence into motion
primitives with hierarchical cluster analysis. These cluster-
ing methods are under the framework similar to the expec-
tation-maximization (EM) clustering [12]. Conventional EM
does not consider the temporal order of sequence frames,
which may produce undesirable clustering results. For
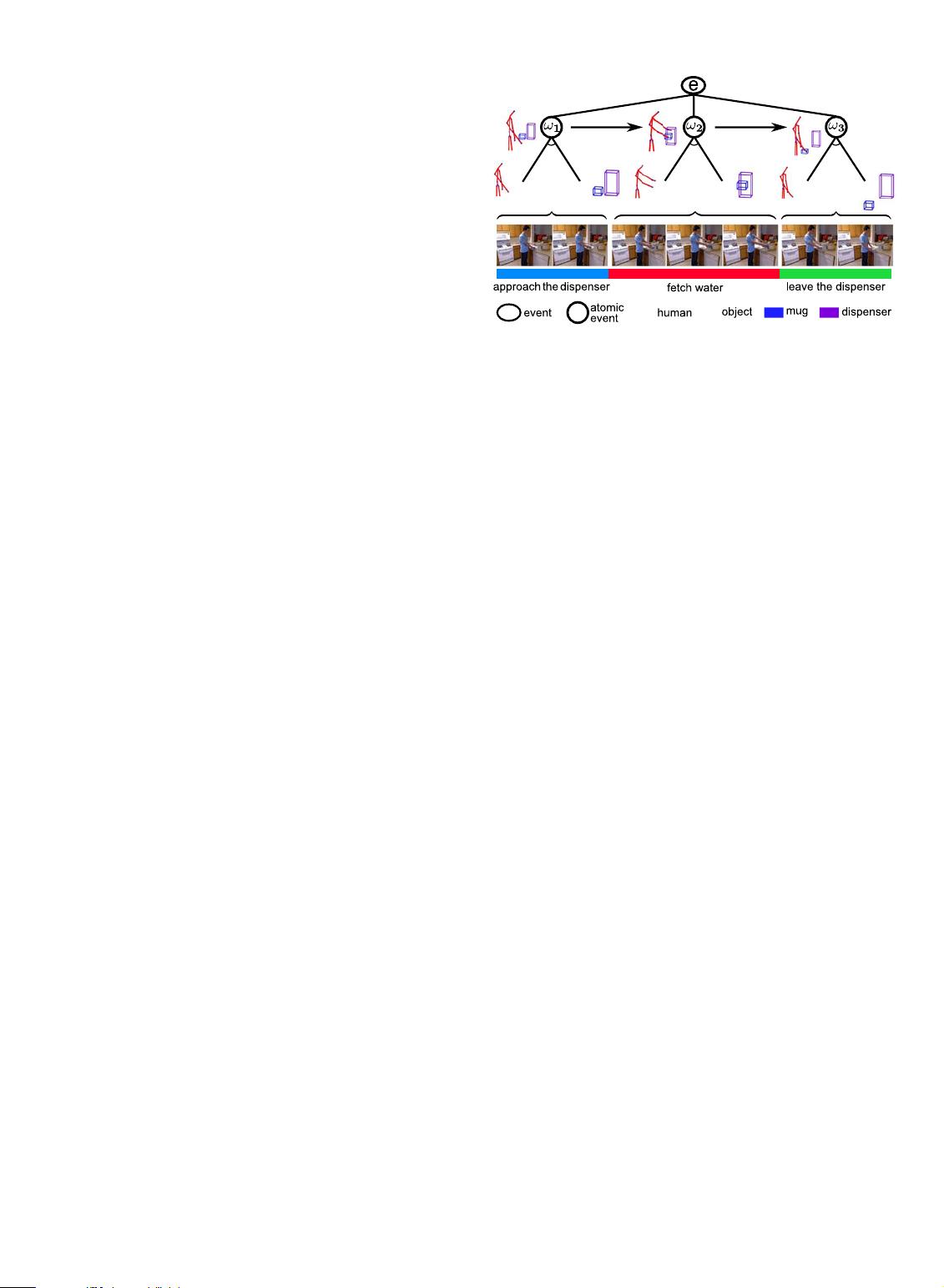
example, as is shown in Fig. 3, the poses of approach the dis-
penser and leave the dispenser are very similar. Without con-
sidering the temporal order, these two poses may be
clustered into the same cluster. Though the method in [4]
introduced the temporal order into clustering, it did not
consider the mutual constraints among the sequences of the
same category, but rather carried out the frame clustering
for each independent sequence.
2.5 Our Contributions
In comparison with the previous work, this paper makes
four contributions.
1. It presents a 4D human-object interaction model as a
stochastic hierarchical spatial-temporal graph, which
represents the 3D human-object relations and the
temporal relations between atomic events in RGB-D
videos.
2. It develops a unified framework for joint inference of
event recognition, sequence segmentation, and object
localization.
3. It proposes an unsupervised algorithm to learn the
latent temporal structures of events and the model
parameters from sequence samples.
4. It tests the model on three challenging datasets, and
the performance demonstrates the strength of the
model.
34DHUMAN-OBJECT INTERACTION MODEL
As Fig. 3 illustrates , the 4DHOI model is a hierarchical
graph for an event. On the time axis, an event is decom-
posedintoseveralorderedatomicevents.Forexample,
the event fetch water from dispenser is decomposed into
Fig. 3. A hierarchical graph of the 4D human-object interactions for an
example event fetch water from dispenser.
WEI ET AL.: MODELING 4D HUMAN-OBJECT INTERACTIONS FOR JOINT EVENT SEGMENTATION, RECOGNITION, AND OBJECT... 1167
下载后可阅读完整内容,剩余14页未读,立即下载
2821 浏览量
188 浏览量
点击了解资源详情
点击了解资源详情
234 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38599712
- 粉丝: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java人事管理系统源码Myeclipse开发下载
- 掌握PHP:十个高级技巧让你成为编程高手
- 前端开发必读:Github前端代码规范精析
- SQL Server 2000企业级管理案例教学
- 关键词邮箱自动搜索工具:超能邮箱搜索
- 基于JSP和Servlet的人力资源管理系统实例分享
- 神州100网站源码美化版发布 - 管理后台简易访问
- 以太坊血浆实施:技术细节与发展历程
- 全面提升WiFi管理效率的强大扫描工具
- Ougishi软件:手写字个性化字体转换工具
- 第三方支付网关接口整理与常见问题汇总
- Java Socket多线程实现图片轮播视频效果
- C#语言开发的ASP.NET版BBS论坛社区程序
- ASP在线攒机系统Ayin版修复与优化
- IE11即将终止支持:小工具及倒计时
- 三级联动实用版:省市区联动HTML模板免费下载
