MASS:用于语言生成的掩码序列到序列预训练
需积分: 0 39 浏览量
更新于2024-08-05
收藏 7.48MB PDF 举报
"MASS Masked Sequence to Sequence Pre-training for Language Generation"
在自然语言处理领域,预训练和微调已经成为提升模型性能的关键技术。MASS(Masked Sequence to Sequence Pre-training)是由Song等人提出的一种用于语言生成的新方法,它借鉴了BERT(Devlin et al., 2018)在理解任务上的成功经验,并将其应用到序列到序列的生成任务中。
BERT是基于Transformer架构的预训练模型,通过掩码语言模型(Masked Language Model, MLM)在无监督的大量文本数据上学习语义表示。它随机选择部分单词进行掩蔽,然后让模型预测这些被遮掩的单词,以此来学习上下文依赖和词汇的表示。
MASS则针对序列到序列模型进行预训练,其核心思想是在输入序列中随机选择连续的词片段进行掩蔽,而不是单个词。然后,模型的编码器接收到带有掩蔽的句子,解码器的任务是根据未被掩蔽的部分预测出被掩蔽的序列。这种设计使模型在预训练阶段可以同时训练编码器和解码器,以提升其对输入序列的表示提取能力和语言建模能力。
通过这种方式,MASS能够学习到更复杂的上下文关系,因为它不仅需要理解整个句子,还需要在缺少部分信息的情况下生成丢失的片段。预训练后的MASS模型可以在各种低资源或零资源的语言生成任务中进行微调,如神经机器翻译、文本摘要和对话响应生成等,实现在这些任务上的高效表现。在多个任务和数据集上的实验表明,MASS相比于其他预训练方法能显著提高下游任务的性能,尤其是在语言生成任务上。
MASS为语言生成任务提供了一种新的预训练策略,通过掩蔽连续的序列片段,使得模型在无监督学习阶段就具备了理解和生成完整句子的能力。这一方法进一步拓宽了预训练技术在自然语言处理中的应用范围,对于提升低资源环境下的模型性能有着重要的意义。
MASS: Masked Sequence to Sequence Pre-training for Language Generation
X
6
X
8
_ X
7
X
1
X
2
_ _ _ _ _ _ X
4
X
5
X
3
Encoder
Decoder
__
X
3
X
5
X
4
Attention
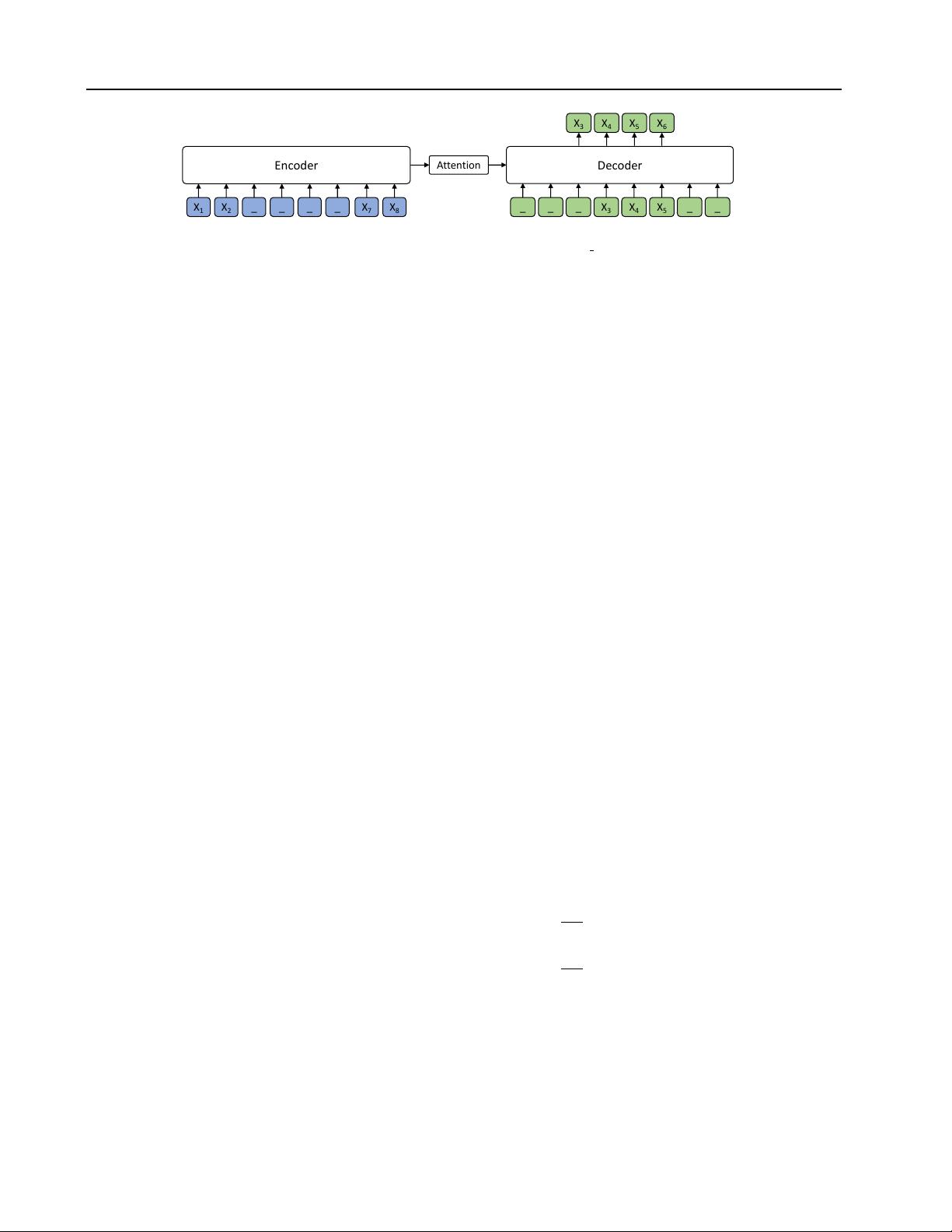
Figure 1. The encoder-decoder framework for our proposed MASS. The token “ ” represents the mask symbol [M].
accuracy on multiple language understanding tasks in the
GLUE benchmark (Wang et al., 2018) and SQuAD (Ra-
jpurkar et al., 2016).
There are also some works pre-training the encoder-decoder
model for language generation. Dai & Le (2015); Ra-
machandran et al. (2016) leverage a language model or
auto-encoder to pre-train the encoder and decoder. Their
improvements, although observed, are limited and not as
general and significant as the pre-training methods (e.g.,
BERT) for language understanding. Zhang & Zong (2016)
designed a sentence reordering task for pre-training, but
only for the encoder part of the encoder-decoder model.
Zoph et al. (2016); Firat et al. (2016) pre-train the model
on similar rich-resource language pairs and fine-tuned on
the target language pair, which relies on supervised data on
other language pairs. Recently, XLM (Lample & Conneau,
2019) pre-trained BERT-like models both for the encoder
and decoder, and achieved the previous state of the art re-
sults on unsupervised machine translation. However, the
encoder and decoder in XLM are pre-trained separately and
the encoder-decoder attention mechanism cannot be pre-
trained, which are sub-optimal for sequence to sequence
based language generation tasks.
Different from previous works, our proposed MASS is care-
fully designed to pre-train both the encoder and decoder
jointly using only unlabeled data, and can be applied to
most language generations tasks.
3. MASS
In this section, we first introduce the basic framework of
sequence to sequence learning, and then propose MASS
(MAsked Sequence to Sequence pre-training). We then
discuss the differences between MASS and previous pre-
training methods including the masked language modeling
in BERT and standard language modeling.
3.1. Sequence to Sequence Learning
We denote
(x, y) ∈ (X , Y)
as a sentence pair, where
x = (x
1
, x
2
, ..., x
m
)
is the source sentence with
m
to-
kens, and
y = (y
1
, y
2
, ..., y
n
)
is the target sentence with
n
tokens, and
X
and
Y
are the source and target do-
mains. A sequence to sequence model learns the param-
eter
θ
to estimate the conditional probability
P (y|x; θ)
,
and usually uses log likelihood as the objective function:
L(θ; (X , Y)) = Σ
(x,y )∈(X ,Y)
log P (y|x; θ)
. The condi-
tional probability
P (y|x; θ)
can be further factorized accord-
ing to the chain rule:
P (y|x; θ) =
Q
n
t=1
P (y
t
|y
<t
, x; θ)
,
where y
<t
is the proceeding tokens before position t.
A major approach to sequence to sequence learning is the
encoder-decoder framework: The encoder reads the source
sequence and generates a set of representations; the decoder
estimates the conditional probability of each target token
given the source representations and its preceding tokens.
Attention mechanism (Bahdanau et al., 2015a) is further
introduced between the encoder and decoder to find which
source representation to focus on when predicting the cur-
rent token.
3.2. Masked Sequence to Sequence Pre-training
We introduce a novel unsupervised prediction task in this
section. Given an unpaired source sentence
x ∈ X
, we
denote x
\u:v
as a modified version of x where its fragment
from position
u
to
v
are masked,
0 < u < v < m
and
m
is
the number of tokens of sentence
x
. We denote
k = v−u+1
as the number of tokens being masked from position
u
to
v
. We replace each masked token by a special symbol
[M]
,
and the length of the masked sentence is not changed.
x
u:v
denotes the sentence fragment of x from u to v.
MASS pre-trains a sequence to sequence model by predict-
ing the sentence fragment
x
u:v
taking the masked sequence
x
\u:v
as input. We also use the log likelihood as the objec-
tive function:
L(θ; X ) =
1
|X |
Σ
x∈X
log P (x
u:v
|x
\u:v
; θ)
=
1
|X |
Σ
x∈X
log
v
Y
t=u
P (x
u:v
t
|x
u:v
<t
, x
\u:v
; θ).
(1)
We show an example in Figure 1, where the input sequence
has 8 tokens with the fragment
x
3
x
4
x
5
x
6
being masked.
Note that the model only predicts the masked fragment
x
3
x
4
x
5
x
6
, given
x
3
x
4
x
5
as the decoder input for position
4 − 6
, and the decoder takes the special mask symbol
[M]
as inputs for the other positions (e.g., position
1 − 3
and
剩余10页未读,继续阅读

月小烟
- 粉丝: 823
 我的内容管理
展开
我的内容管理
展开







最新资源
- VC++多线程与网络编程实战:进程与线程,Winsock基础
- VC++对话框与标准控件详解:模式对话框与编程入门
- 深入理解MFC应用程序:框架与消息处理
- 深入理解VC++动态链接库(DLL):原理与实战
- 运用软件工程思想开发扫雷游戏
- Windows Server 2003服务器群集配置实战指南
- Ruby 技巧解析:面向 Rails 开发者
- Shell编程入门指南:从Cygwin到Bash命令
- Linux环境下的C++编程实践与库对比
- Protel99使用指南:从安装到原理图设计
- ActionScript 3 RIA 开发权威指南
- 提升全文检索速度的有序单词搜索树与索引文件压缩算法
- Visual C# 中创建系统热键的方法
- AT91SAM7A3 ARM处理器数据手册详解
- SAS宏基础教程:文本操作与变量控制
- 固件开发必备:如何高效阅读DataSheet
