NVIDIA A100: 深度解析新一代数据中心GPU架构
需积分: 5 137 浏览量
更新于2024-06-23
收藏 7.37MB PDF 举报
“NVIDIA A100 Tensor Core GPU是NVIDIA推出的第8代数据中心GPU,专为弹性计算时代设计,提供了前所未有的加速能力。这款GPU在人工智能、高性能计算(HPC)和数据 analytics 领域展现出业界领先的性能。其关键特性包括全新的Streaming Multiprocessor(SM)、40GB HBM2内存与40MB L2缓存、Multi-Instance GPU(MIG)技术、第三代NVLink、对NVIDIA Magnum IO和Mellanox互连解决方案的支持、PCIe Gen4带SR-IOV功能,以及增强的错误检测和隔离机制。”
NVIDIA A100 Tensor Core GPU架构深度解析:
A100 Streaming Multiprocessor(SM):作为GPU的核心处理单元,SM进行了优化,提升了运算效率和并行处理能力,支持更多的CUDA核心,能够执行更复杂的计算任务。
第三代NVIDIA Tensor Core:Tensor Core是NVIDIA针对深度学习计算专门设计的硬件单元,第三代Tensor Core在前代基础上进一步提高了吞吐量,支持FP32、FP16、INT8和BFloat16等多种数据类型,为深度学习训练和推理提供了极高的加速效果。
A100 Tensor Cores Boost Throughput:通过引入混合精度计算,A100 Tensor Core能以更高的速度处理大型模型,同时保持高精度,显著提升计算效率。
A100 Tensor Cores Support All DL Data Types:支持各种深度学习数据类型,包括半精度浮点(FP16)、单精度浮点(FP32)、整数(INT8)和BFloat16,这使得A100 GPU可以适应多种不同的深度学习工作负载。
Mixed Precision Tensor Cores for HPC:混合精度计算不仅在AI领域表现出色,也适用于高性能计算。A100的Tensor Core支持混合精度,使得HPC应用在保持精度的同时,计算速度得到大幅提升。
A100 Introduces Fine-Grained Multi-Instance GPU (MIG):MIG技术允许将一个A100 GPU划分为多个独立的GPU实例,每个实例拥有自己的计算资源,如内存和带宽,提供隔离和资源优化,特别适合云服务提供商和数据中心,以满足不同用户和应用的需求。
Third-Generation NVLink:这一代NVLink提供更高的带宽,允许GPU之间的高速通信,增强了多GPU协同工作的性能,对于大数据处理和复杂计算任务尤为重要。
NVIDIA Magnum IO和Mellanox Interconnect Solutions:NVIDIA Magnum IO是针对I/O优化的一套软件框架,结合Mellanox互连解决方案,可以实现低延迟、高带宽的数据传输,优化数据中心的网络性能。
Asynchronous Copy、Asynchronous Barrier、Task Graph Acceleration:这些特性旨在提高并行处理的效率,异步复制允许在数据传输的同时进行其他计算,异步屏障则帮助协调多线程间的同步,而任务图加速则进一步优化了任务调度,提升整体系统性能。
NVIDIA A100 Tensor Core GPU以其创新的架构和特性,为人工智能、高性能计算和数据分析等领域的应用提供了强大的计算动力,是现代数据中心和云计算平台的理想选择。
NVIDIA A100 Tensor Core GPU Overview
14
NVIDIA A100 Tensor Core GPU Architecture
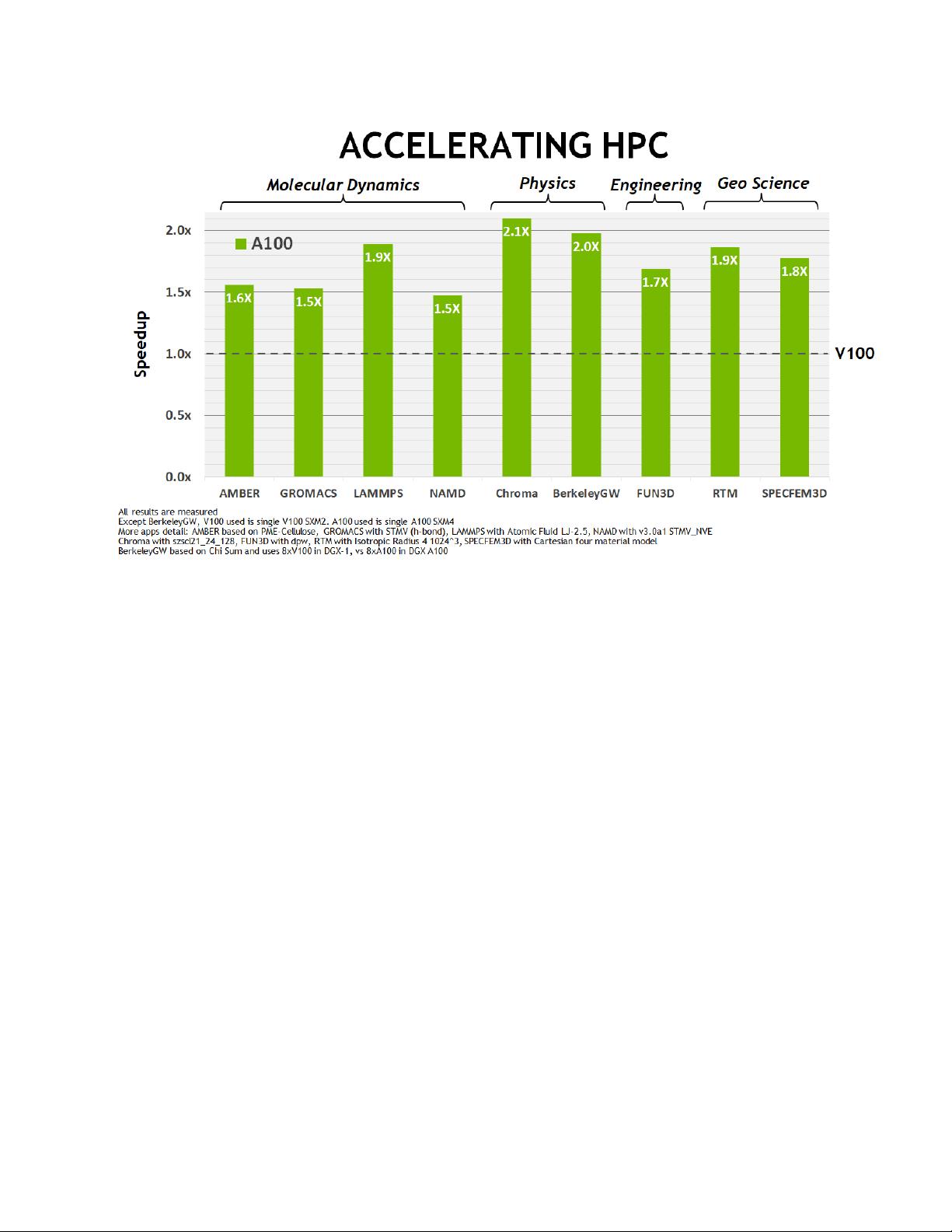
Figure 5. A100 GPU HPC application speedups compared to NVIDIA Tesla
V100
A100 GPU Key Features Summary
The NVIDIA A100 Tensor Core GPU is the world’s fastest cloud and data center GPU
accelerator designed to power computationally-intensive AI, HPC, and data analytics
applications.
Fabricated on TSMC’s 7nm N7 manufacturing process, the NVIDIA Ampere architecture-based
GA100 GPU that powers A100 includes 54.2 billion transistors with a die size of 826 mm2.
A high-level summary of key A100 features is provided below for a quick understanding of the
important new A100 technologies and performance levels. In-depth architecture information is
presented in subsequent sections.


剩余82页未读,继续阅读
481 浏览量
点击了解资源详情
470 浏览量
811 浏览量
107 浏览量
点击了解资源详情
点击了解资源详情
168 浏览量

wangye_nwpu
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网络你让我难过中的经典好资源用过都说好
- 批处理教程(txt)
- C#拷屏代码.txt
- 高数知识点高数总结。。。。
- SQL 语言 艺术 适合SQL数据库开发者
- Web_Dynpro_for_ABAP NW2004s_SPS8
- 严蔚敏数据结构习题集答案
- max197AD说明书
- wince 驱动快速编译的方法
- grails-reference-documentation-1.1.x.pdf
- asp.net图书管理系统
- Cdma高FER优化
- Manning.Publications.wxPython.in.Action.Mar.2006(pdf版)
- 快速精通linux-from window to linux
- 无线分布式网络图像视频编码
- 单片机设计数字音乐盒
