深度学习方法解决异构实体解析:序列到序列模型在ER中的应用
108 浏览量
更新于2024-08-27
收藏 358KB PDF 举报
深度序列到序列实体匹配(DeepSequence-to-SequenceEntityMatching,简称DS2SEM)是一种在异构数据源中实现实体解析的创新方法,特别是在面临复杂且不一致的数据结构时。传统的实体分辨率(Entity Resolution, ER)策略通常依赖于结构匹配机制,通过将不同数据源中的属性进行对齐、比较和聚合,以决定是否属于同一真实世界的实体。然而,这种方法存在局限性,主要体现在以下两个方面:
首先,异构性问题:由于实体来源于不同的数据源,它们的描述可能遵循不同的模式或架构(schema heterogeneity),这导致在处理过程中难以找到统一的比较标准。每个数据源可能使用不同的属性集来表示实体,这增加了匹配的复杂性和不确定性。
其次,脏数据问题:属性值可能存在缺失、错误或噪声。在实际应用中,记录中的数据质量参差不齐,这可能导致即使对于同一实体,其属性表示也可能存在差异,从而影响精确匹配。
DS2SEM方法突破了这些传统挑战,它利用深度学习技术,特别是序列到序列(Sequence-to-Sequence, Seq2Seq)模型,来处理这个问题。Seq2Seq模型最初在机器翻译领域大放异彩,它能够学习输入序列与输出序列之间的映射关系,这里被巧妙地应用于实体匹配场景。具体来说,该模型接受一个数据源的属性序列作为输入,经过编码器(Encoder)处理,将其转化为潜在的、抽象的向量表示;然后,解码器(Decoder)根据这个向量生成另一个数据源的潜在表示。通过比较这两个潜在向量的相似度,模型可以判断两个实体是否对应同一真实世界实体,而无需预先定义严格的属性对齐规则。
这种基于深度学习的方法的优势在于它可以自动学习和适应不同数据源的特征表示,并且能够处理属性值的缺失或噪声,提高了实体解析的鲁棒性和准确性。然而,DS2SEM也需要大量的标注数据来训练模型,同时对模型的计算资源和时间需求较高。此外,为了进一步提高性能,研究者们可能还需要考虑集成其他特征,如实体的上下文信息或者利用外部知识库,以及针对特定领域的领域知识进行定制化设计。
深度序列到序列实体匹配为解决异构实体解析提供了新的视角和强大的工具,它正在改变我们理解和处理大量异构数据的方式,有望在未来的研究和实践中发挥重要作用。
Deep Sequence-to-Sequence Entity Matching for
Heterogeneous Entity Resolution
Hao Nie
1,3
, Xianpei Han
1,2
, Ben He
3,1∗
, Le Sun
1,2
, Bo Chen
1
, Wei Zhang
4
, Suhui Wu
4
, Hao Kong
4
1
Chinese Information Processing Laboratory, Institute of Soware, Chinese Academy of Sciences, Beijing, China
2
State Key Laboratory of Computer Science, Institute of Soware, Chinese Academy of Sciences, Beijing, China
3
University of Chinese Academy of Sciences, Beijing, China
4
Alibaba Group, Hangzhou, China
1
{niehao2016, xianpei, sunle, chenbo}@iscas.ac.cn
3
benhe@ucas.ac.cn
4
{lantu.zw, linnai.wsh, konghao.kh}@alibaba-inc.com
ABSTRACT
Entity Resolution (ER) identies records from dierent data sources
that refer to the same real-world entity. Conventional ER approaches
usually employ a structure matching mechanism, where aributes
are aligned, compared and aggregated for ER decision. e struc-
ture matching approaches, unfortunately, oen suer from het-
erogeneous and dirty ER problems. at is, entities from dierent
data sources are described using dierent schemas, and aribute
values may be misplaced, missing, or noisy. In this paper, we pro-
pose a deep sequence-to-sequence entity matching model, denoted
Seq2SeqMatcher, which can eectively solve the heterogeneous and
dirty problems by modeling ER as a token-level sequence-to-sequence
matching task. Specically, we propose an align-compare-aggregate
neural network for Seq2Seq entity matching, which can learn the
representations of tokens, capture the semantic relevance between
tokens, and aggregate matching evidence for accurate ER decisions
in an end-to-end manner. Experimental results show that, by com-
paring entity records in token level and learning all components
in an end-to-end manner, our Seq2Seq entity matching model can
achieve remarkable performance improvements on 9 standard en-
tity resolution benchmarks.
CCS CONCEPTS
• Information systems → Entity resolution; Deduplication; •
Computing methodologies → Ontology engineering.
KEYWORDS
entity resolution; aribute heterogeneity; matching; deep learning
ACM Reference Format:
Hao Nie, Xianpei Han, Ben He, Le Sun, Bo Chen, Wei Zhang, Suhui Wu,
Hao Kong. 2019. Deep Sequence-to-Sequence Entity Matching for Hetero-
geneous Entity Resolution. In
e 28th ACM International Conference on
*Corresponding authors.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full cita-
tion on the rst page. Copyrights for components of this work owned by others than
ACM must be honored. Abstracting with credit is permied. To copy otherwise, or re-
publish, to post on servers or to redistribute to lists, requires prior specic permission
and/or a fee. Request permissions from permissions@acm.org.
CIKM ’19, November 3–7, 2019, Beijing, China
© 2019 Association for Computing Machinery.
ACM ISBN 978-1-4503-6976-3/19/11…$15.00
https://doi.org/10.1145/3357384.3358018
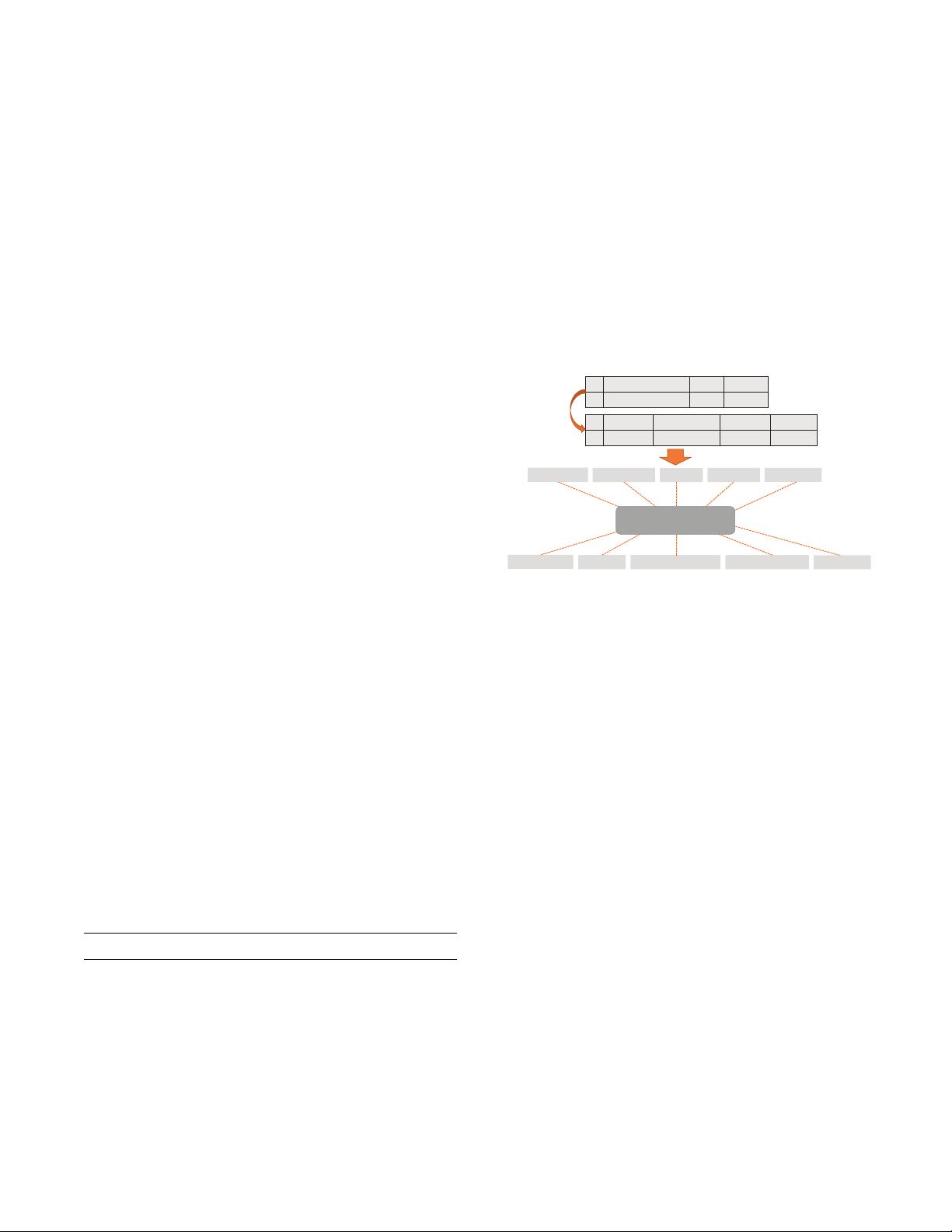
Name Brand $GGUHVV
݁
ଵ
Apple iphone 8 plus CA
Name Manufacturer Location Price
݁
ଶ
iphone 8p Apple California 699.9
match or
non-match ?
[Name, iphone]
[Name, 8p] [Manufacturer, Apple] [Location, CaliforQia][Price, 699.9]
[Name Apple]
[
Name
,
iphone]
[Name, 8]
[Name, plus]
[$GGUHVV,CA]
Sequence-to-Sequence
Matching
Figure 1: An entity resolution example under the Seq2Seq
entity matching framework.
Information and Knowledge Management (CIKM’19), November 3–7, 2019,
Beijing, China. ACM, New York, NY, USA, 10 pages. https://doi.org/10.1145/
3357384.3358018
1 INTRODUCTION
Entity resolution (ER) aims to identify records referring to the same
real-world entity. For example in Figure 1, the entity records e
1
and
e
2
correspondingly from Walmart and Amazon would be resolved
as the same entity because they refer to the same real-world prod-
uct. ER is important in knowledge integration [8–10], data cleaning
[6] and information management [16] and has therefore received
signicant research aention in recent years [13, 15, 17, 27, 35].
In entity resolution, each record is a structured object composed
of one or more <aribute, value> pairs. Conventional approaches
usually model entity resolution as a structure-to-structure match-
ing task. Concretely, aributes are rstly aligned either manually
or automatically, then similarities between corresponding aribute
values are computed, nally similarity scores between aligned at-
tributes are aggregated to get the nal similarity between records.
For example, to resolve e
1
and e
2
in Figure 1, structure match-
ing systems rst identify Name and Address (Location) as
aligned aributes, then the total similarity is computed by aggre-
gating the similarities of the corresponding aribute values (“Ap-
ple iphone 8 plus”, “iphone 8p”) under Name and (CA, California)
under Address (Location).
e structure matching approaches, unfortunately, oen face
problems when entity records are heterogeneous or dirty. Firstly,
下载后可阅读完整内容,剩余9页未读,立即下载
2140 浏览量
2217 浏览量
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38680764
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Openaea:Unity下开源fanmad-aea游戏开发
- Eclipse中实用的Maven3插件指南
- 批量查询软件发布:轻松掌握搜索引擎下拉关键词
- 《C#技术内幕》源代码解析与学习指南
- Carmon广义切比雪夫滤波器综合与耦合矩阵分析
- C++在MFC框架下实时采集Kinect深度及彩色图像
- 代码研究员的Markdown阅读笔记解析
- 基于TCP/UDP的数据采集与端口监听系统
- 探索CDirDialog:高效的文件路径选择对话框
- PIC24单片机开发全攻略:原理与编程指南
- 实现文字焦点切换特效与滤镜滚动效果的JavaScript代码
- Flask API入门教程:快速设置与运行
- Matlab实现的说话人识别和确认系统
- 全面操作OpenFlight格式的API安装指南
- 基于C++的书店管理系统课程设计与源码解析
- Apache Tomcat 7.0.42版本压缩包发布
