Pandas入门教程:数据操作与分析
需积分: 0 185 浏览量
更新于2024-06-30
收藏 1.45MB PDF 举报
"关于Pandas库的介绍及数据操作实例"
在Python编程中,Pandas是一个强大的数据分析工具,尤其在处理结构化数据时表现出色。Pandas版本1代表了该库的一个更新,可能包含了性能优化、新功能以及对现有功能的改进。在描述中提到了与Python的兼容性,暗示Pandas 1可以无缝集成到Python环境中。
Pandas的核心对象是DataFrame,它是一种二维表格型数据结构,可以存储各种类型的数据(包括字符串、数字、日期等),并提供了丰富的数据分析和操作方法。在提供的代码示例中,我们看到了如何创建一个DataFrame来存储“grammer”(语法)和“score”(分数)两个列的数据。`pd.DataFrame()`是创建DataFrame的函数,`data`参数是一个包含两列的字典。
接下来,代码展示了如何填充缺失值(NaN)以及根据条件筛选数据。在Python中,`np.nan`表示浮点型的Not a Number,通常用于表示数据缺失。`df[df['grammer']=='Python']`这一行代码筛选出“grammer”列值为“Python”的所有行。为了处理含有缺失值的列,可以使用`fillna()`方法,这里将缺失值填充为False,并使用`inplace=True`让更改直接作用于原始DataFrame。
`df.columns`返回DataFrame的所有列名,显示了数据结构的组织方式。`rename()`函数用于修改列名,这里将“score”列重命名为“popularity”,`inplace=True`确保修改直接应用到DataFrame。
在实际的数据分析中,Pandas提供了多种数据清洗、聚合、排序、分组等操作,使得数据预处理和探索变得高效。例如,可以使用`groupby()`进行分组统计,使用`merge()`或`join()`合并数据集,使用`sort_values()`进行排序,以及使用`pivot_table()`创建透视表等。这些功能使得Pandas成为数据科学家和分析人员的首选库。
Pandas版本1提供了一个强大且灵活的数据操作环境,结合Python的易用性,使得数据分析任务变得更加简单。通过学习和掌握Pandas,开发者可以更有效地处理和理解复杂的数据集,从而做出更明智的决策。
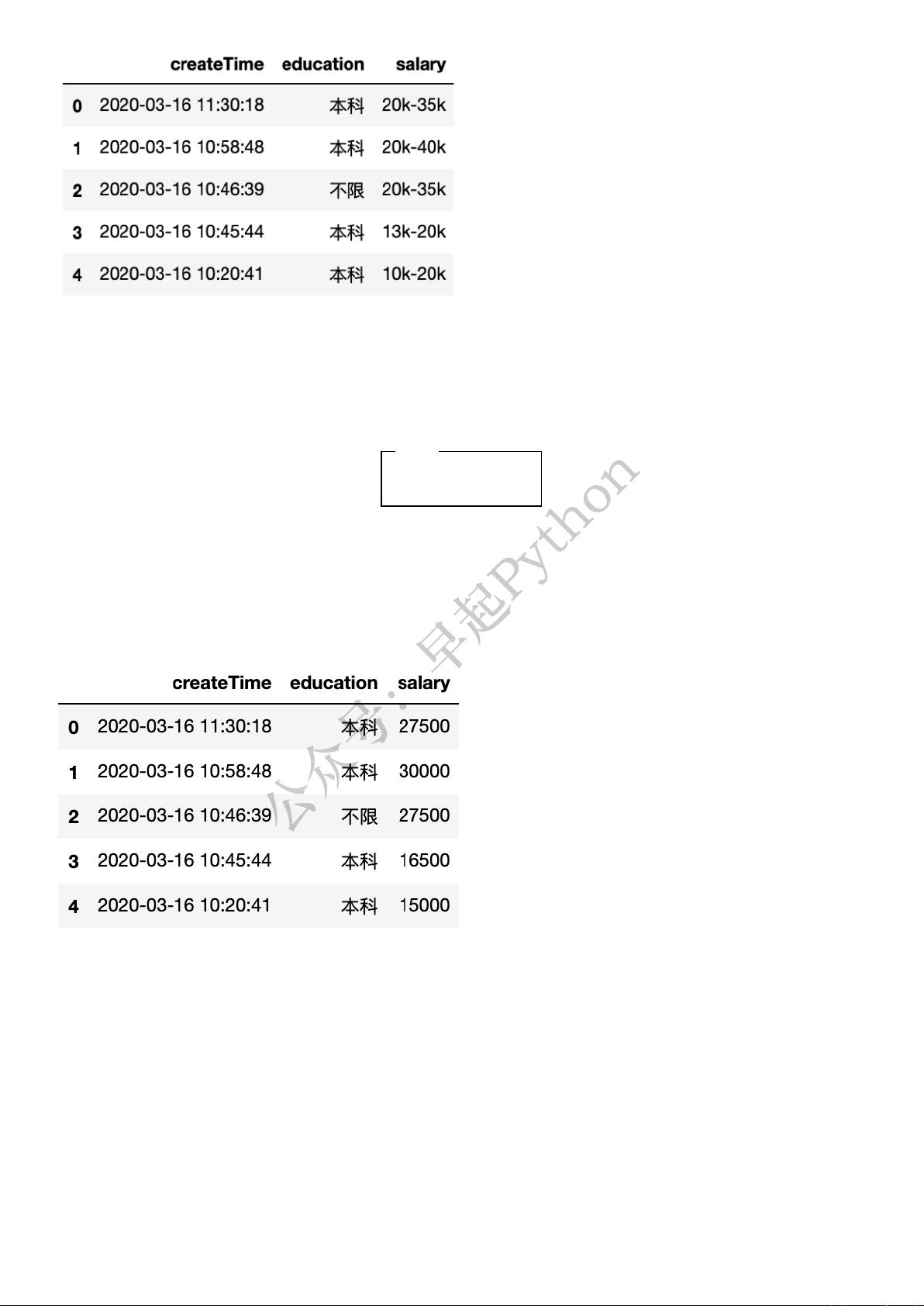
Python
df.head()
salary
⭐⭐⭐⭐
Python
#
apply +
def func(df):
lst = df['salary'].split('-')
smin = int(lst[0].strip('k'))
smax = int(lst[1].strip('k'))
df['salary'] = int((smin + smax) / 2 * 1000)
return df
23
公众号:早起Python

剩余44页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-30 上传
252 浏览量
355 浏览量
149 浏览量
2657 浏览量
198 浏览量

方2郭
- 粉丝: 32
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java入门示例:Mongodb压缩包文件解析
- 构建贷款违约预测模型:课程与精细分类技术应用
- 局域网远程监控解决方案:VC++实现视频传输
- STM32正交编码接口(QEI)源码资料完整指南
- MFC界面编程实现图形响应菜单项移动效果
- 易语言实现二叉堆算法的源代码分析
- iOS开发技巧:仿制橘子娱乐APP并优化性能
- 易语言实现SQLSERVER查询分析器源码分析
- 深入探究Webapi2在C#开发中的应用
- 掌握电磁处理算法 - 飞思卡尔比赛教材
- 掌握C++代码分析新工具 Understand C++ 1.4.410
- 易语言实现二分法求解函数零点教程
- iOS源码:XBStepper自动拉伸计数器控件实现与使用
- 建立人脸库的人脸检测系统功能详解
- LDC1000模块在STM32f103上的应用与铁丝寻迹小车项目
- iOS星级评价弹窗组件StsrAlertView封装教程
