Java数据结构与排序算法深度解析
需积分: 7 198 浏览量
更新于2024-09-16
收藏 171KB PDF 举报
"本章详细介绍了Java数据结构中的排序算法,包括交换式排序、选择式排序、插入式排序以及合并排序法。通过实例解析了这些排序算法的工作原理和应用场景,帮助理解不同排序方法的差异和适用情况。"
在计算机科学中,数据结构是组织和管理数据的一种方式,它直接影响到数据的存取效率。Java作为一种广泛使用的编程语言,提供了丰富的数据结构供开发者使用。本章节主要探讨的是数据结构中的一个重要应用——排序。
排序是将一组数据按照特定的顺序进行排列的过程,它可以是递增(从小到大)或递减(从大到小)。排序在数据处理中占据着重要地位,因为它经常被用于优化查询速度、数据分析和数据库操作等场景。根据数据是否全部在内存中处理,排序可以分为内部排序和外部排序。内部排序通常适用于数据量较小的情况,而外部排序则用于处理超出内存容量的大数据集。
内部排序有多种方法,本章提到了交换式排序、选择式排序和插入式排序:
1. 交换式排序,如冒泡排序和快速排序,它们的特点是通过比较数据值并交换位置来实现排序。例如,冒泡排序通过不断相邻元素之间的比较和交换,使得较大的元素逐渐“冒”到数组的末尾。
2. 选择式排序,包括简单的选择排序和堆排序,其基本思想是找到数组中最小(或最大)的元素,与数组的某个位置进行交换,然后继续寻找下一个未排序的最小(或最大)元素。这种方法通常不保证稳定性,即相等的元素可能会改变原有的相对顺序。
3. 插入式排序,如直接插入排序和希尔排序,它的工作机制是将每个元素插入到已排序部分的正确位置,以达到整体有序的效果。插入排序在处理部分有序的数据时表现良好,但对完全无序的数据效率较低。
4. 合并排序法,是外部排序中常用的一种方法,它采用分治策略,将大文件分成多个小文件进行排序,然后合并这些已排序的小文件以完成整个排序过程。合并排序通常适用于数据量太大无法一次性加载到内存的情况。
这些排序算法各有优缺点,选择哪种算法取决于具体的应用场景,如数据规模、数据的初始状态以及对排序稳定性的需求。理解并掌握这些排序算法对于提升程序性能至关重要,特别是在大数据处理和高性能计算领域。通过深入学习和实践,开发者可以根据实际情况灵活选择和优化排序算法,提高程序的运行效率。
数据结构(Java 语言)第七章
授课日期:2005/03/11 授课教师:张中强 授课课时:4(含上机 2 课时)
授课班级: 执笔:王宁 审核:何贵忠
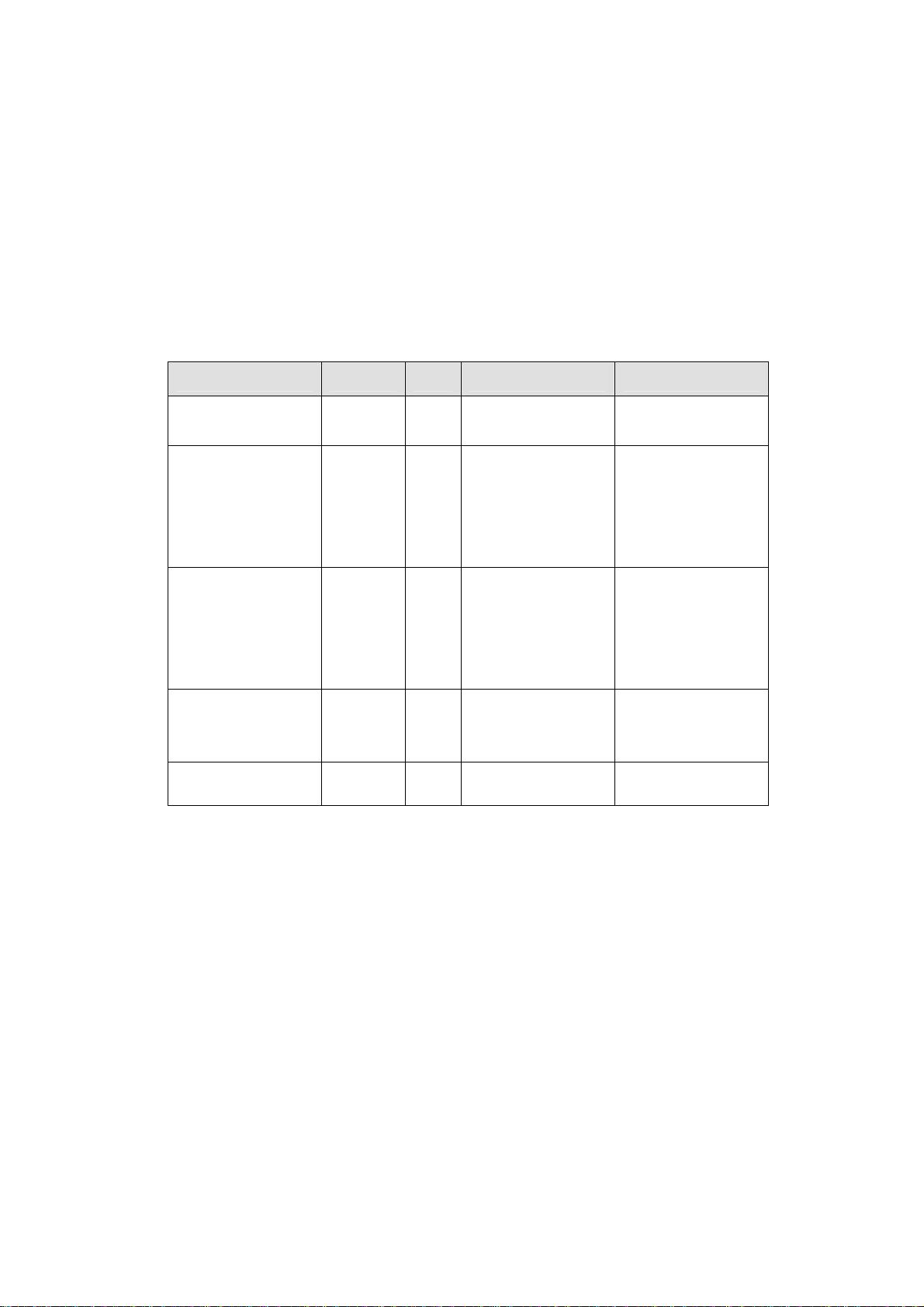
本章知识点
知识点 重要性 难度 简述 讲课实例
何谓排序
3
1
将一群数据进行顺
序排列
举例,归纳特点
交换式排序
3
2
运用数据值比较
后,依判断规则对
数据位置进行交
换,以达到排序的
目的
案例讲解
选择式排序
2 3
按指定的规则选出
某一元素,经过和
其他元素重整,再
依原则交换位置后
达到排序的目的
案例讲解
插入式排序
2 3
以插入的方式找寻
元素的适当位置,
以达到排序的目的
案例讲解
合并排序法
2 3
外部排序最常使用
的排序方法
概念介绍
7.1 排序
排序是将一群数据,依指定的顺序进行排列的过程。排序的分类:内部排序,将需要处
理的所有数据都加载到内部存储器中进行排序(交换式排序法、选择式排序法和插入式排序
法);外部排序法:数据量过大,无法全部加载到内存中,需要借助外部存储器进行排序(合
并排序法和直接合并排序法)。
排序(Sorting)是数据处理中一种很重要的运算,同时也是很常用的运算,一般数据处
理工作 25%的时间都在进行排序。简单地说,排序就是把一组记录(元素)按照某个域的
值的递增(即由小到大)或递减(即由大到小)的次序重新排列的过程。例如一个学生档案
表的排序过程。
1
下载后可阅读完整内容,剩余8页未读,立即下载
1531 浏览量
977 浏览量

chenyubao_2012
- 粉丝: 2
- 资源: 51
 我的内容管理
展开
我的内容管理
展开







最新资源
- 评估网球运动员
- SimCity-2000-portable:SimCity 2000 win95版的便携式运行程序和修补程序,可在Windows Vista7810上运行
- 当其包含的两个库中的两个具有相同符号(例如函数/变量)时,如何使用VC ++构建映像(DLL / EXE)
- hk1.3_ReciverFunction_
- ember_example
- 大型采访指南:MEGA采访指南,JavaSciript,前端,Comp Sci
- copr_scripts:COPR自定义构建脚本以构建各种RPM
- 基于知识图谱的推荐算法-RippleNet的实现.zip
- 雷神FFmpeg + SDL 的视频播放器修正版.rar
- Free Roblox Gift Card | Robux Gift Card 2021-crx插件
- asp+sql订单管理系统.zip
- 蓝黄扁平化商务图表整套下载PPT模板
- 电脑软件EfficientPIM-Setup日程管理软件.rar
- markdowns:存一些markdown【笑哭】
- 静态js
- 北京科技大学Reborn战队2024赛季老飞镖新代码.zip
