Scrapy分布式爬虫实践:利用scrapy-redis实现高效抓取
需积分: 26 144 浏览量
更新于2024-07-16
1
收藏 487KB PPTX 举报
"scrapy框架 分布式爬虫 原理 实战 scrapy-redis Redis 去重 防止中断"
Scrapy是一个强大的Python爬虫框架,它提供了多种类型的爬虫基类,如BaseSpider和sitemap爬虫,使得开发者能够方便地构建和管理网络数据的抓取和处理。在大规模数据爬取时,单机爬虫往往无法满足需求,这时就需要引入分布式爬虫。分布式爬虫通过多台主机协作,共同完成一个爬取任务,提高爬取效率和稳定性。
分布式爬虫的核心在于共享爬取队列。在Scrapy的单机爬虫中,有一个本地爬取队列Queue,用于存放待爬取的Request。而在分布式环境中,这个队列需要被多台主机共享,确保所有主机能访问和更新同一个队列。为了实现这一点,通常会使用一个支持分布式操作的中间件,比如Redis。Redis是一个高性能的键值数据库,它可以提供基于内存的存储,支持列表、集合、有序集合等多种数据结构,方便实现高效的数据存取。
在分布式爬虫中,每个主机都有自己的Scheduler和Downloader,它们从共享的Redis队列中取出Request进行调度和下载。同时,为了保证数据的一致性和完整性,去重机制至关重要。Scrapy自带的去重功能依赖于Request的指纹,即通过计算Request的Method、URL、Body、Headers等信息的散列值来生成指纹。在分布式环境中,这些指纹需要存储在一个共享的集合中,通常是Redis的集合。每次新生成Request时,先检查其指纹是否存在于集合中,如果存在则表示已爬取过,反之则添加指纹并爬取。
分布式爬虫还需要解决一个问题,那就是防止爬虫运行中断。在Scrapy的单机爬虫中,Request队列是保存在内存中的,一旦爬虫意外停止,这些数据将会丢失。在分布式环境中,使用Redis作为Request队列的存储,即使某台主机宕机,其他主机仍然可以继续从Redis中获取Request,保证了爬虫工作的连续性。
利用Scrapy构建分布式爬虫,需要理解其核心原理,包括Request队列的共享、去重机制的实现以及如何保证爬虫的稳定运行。通过集成scrapy-redis这样的扩展,可以有效地在多台主机间协调工作,提高爬虫的效率和可靠性。在实际开发中,还需要关注网络连接的稳定性、错误处理和数据清洗等环节,以确保分布式爬虫的高效和安全运行。
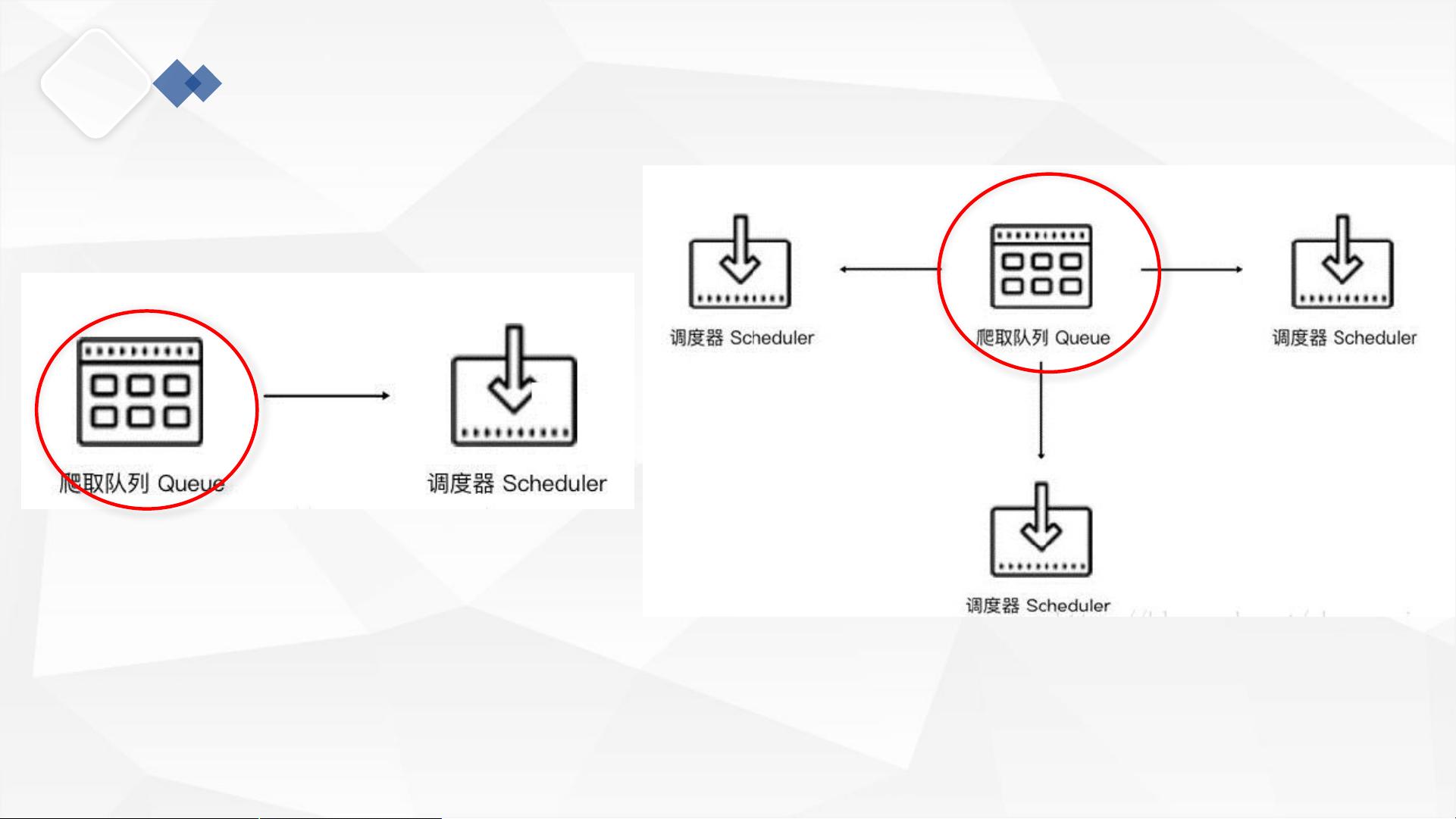
分布式爬虫原理
单机爬虫:一个
分布式爬虫:多个

剩余25页未读,继续阅读
2020-05-22 上传
2021-10-25 上传
2021-08-08 上传
2024-11-08 上传
2024-11-09 上传
2024-11-12 上传
2024-11-03 上传
2024-11-03 上传
2024-11-09 上传

沐呓耳总
- 粉丝: 15
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
