SparkStreaming与Kafka直接整合实战
需积分: 32 48 浏览量
更新于2024-09-07
收藏 1.01MB PDF 举报
该资源主要涉及的是Spark Streaming与Kafka的整合,以及使用Python进行相关练习的背景。在Spark Streaming应用程序中,它演示了如何直接从Kafka消费数据,使用KafkaUtils创建输入流,并设置了特定的配置参数,如SparkConf、StreamingContext、DStream等。同时,还提到了Kafka的broker列表和ZooKeeper集群的地址,用于协调和存储Kafka消费者偏移量。
正文:
在大数据处理领域,Apache Spark Streaming是一个流行的选择,它提供了实时数据流处理的能力。Spark Streaming通过微批处理的方式实现流计算,能够处理来自不同源的数据流。而Kafka作为高吞吐量的分布式消息系统,常被用来作为数据流的生产者和消费者。将Spark Streaming与Kafka整合,可以实现高效的数据处理和分析。
在提供的代码示例中,首先定义了消费者组名`group`,这在Kafka中用于标识不同的消费者群体,每个组内的消费者会共享数据负载。接着,创建了一个`SparkConf`对象,用于设置Spark应用的基本属性,如应用名称和运行模式(这里使用本地模式,`local[2]`表示启动2个工作线程)。
然后,创建了一个`StreamingContext`,这是Spark Streaming的核心组件,它定义了流处理的上下文和时间间隔。在这个例子中,时间间隔设置为5000毫秒,意味着Spark Streaming会每5秒钟处理一次数据批次。
`topic`变量定义了要消费的Kafka主题名,而`brokerList`包含了Kafka broker的地址列表,这些是Spark Streaming的task直接连接的节点,以获取数据。这种方式称为“Direct Stream”模式,它避免了ZooKeeper的中间层,提高了数据读取的效率。
`zkQuorum`参数是ZooKeeper的地址,虽然在这个Direct模式下,Spark Streaming不需要ZooKeeper来发现Kafka的brokers,但是为了保存和更新消费者的偏移量,ZooKeeper仍然是必要的。在实际应用中,也可以选择使用其他持久化存储如Redis或MySQL来存储偏移量。
KafkaUtils是Spark Streaming中用于与Kafka交互的关键类,它提供了从Kafka创建输入流的方法。代码中没有显示这部分,但在实际应用中,通常会用到`KafkaUtils.createDirectStream`函数,传入`topic`、`brokerList`、以及解码器(如`StringDecoder`)来创建一个`InputDStream`。
这个例子中的代码片段只展示了配置部分,完整的应用还需要定义如何处理从Kafka读取的数据,例如使用map、reduceByKey、foreachRDD等操作对数据进行转换和聚合。在处理完成后,还需要定义如何输出结果,以及如何处理和提交offset,以确保数据的一致性。
Python练习100题的题目与本主题无关,但暗示可能在学习Spark Streaming的过程中,同时进行Python编程的练习,以提升编程技能和理解力。整合Spark Streaming和Kafka是大数据实时处理的一个重要实践,它结合了Spark的并行计算能力和Kafka的高效数据传输,使得大规模实时数据分析变得可能。
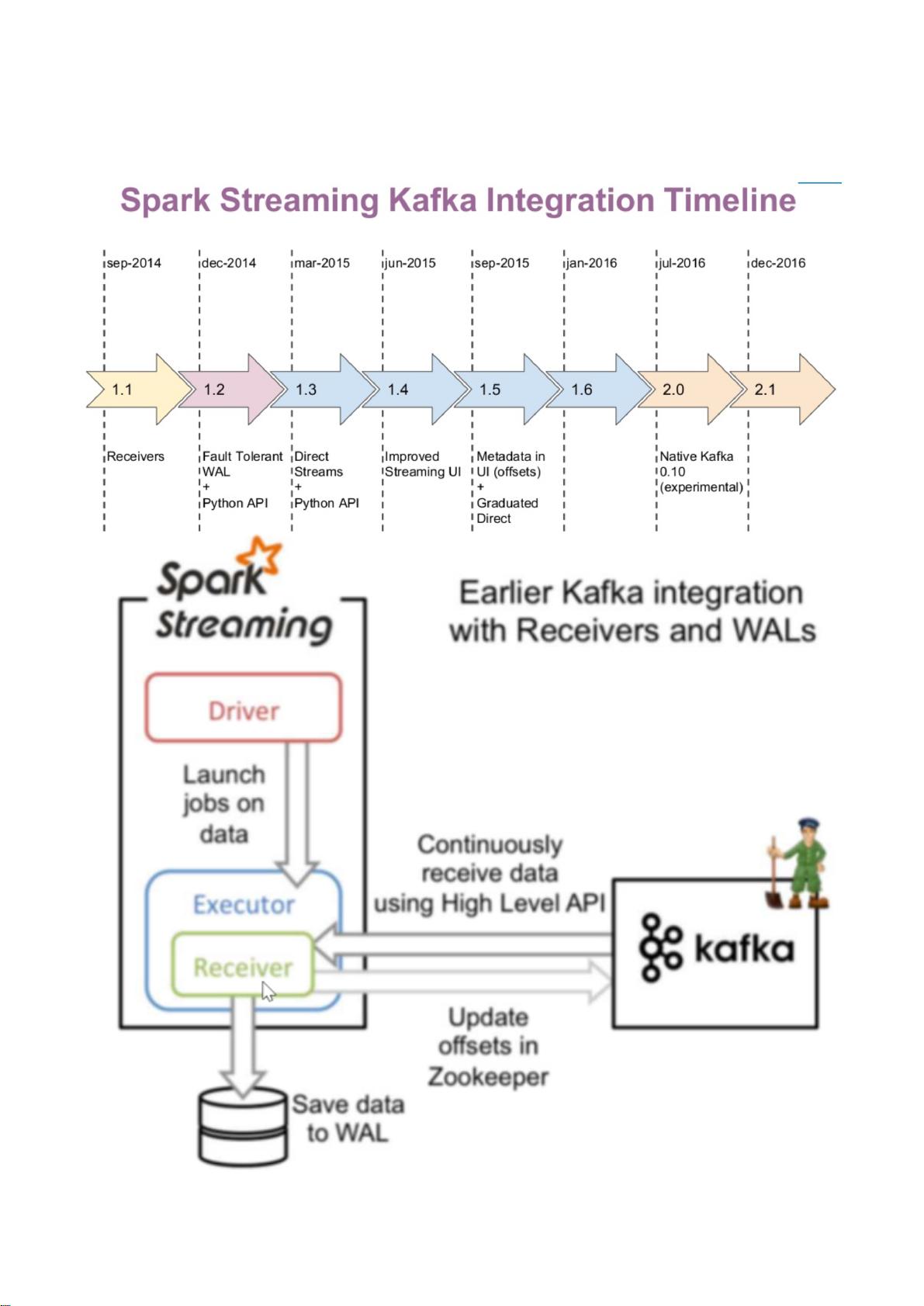
SparkStreaming和kafka的整合
下载后可阅读完整内容,剩余6页未读,立即下载
2015-01-17 上传
2018-03-26 上传
2018-03-01 上传
2021-12-05 上传
2021-08-08 上传
2022-11-17 上传
2021-08-15 上传
2019-12-18 上传
2022-12-24 上传

尬聊码农
- 粉丝: 17
- 资源: 44
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索AVL树算法:以Faculdade Senac Porto Alegre实践为例
- 小学语文教学新工具:创新黑板设计解析
- Minecraft服务器管理新插件ServerForms发布
- MATLAB基因网络模型代码实现及开源分享
- 全方位技术项目源码合集:***报名系统
- Phalcon框架实战案例分析
- MATLAB与Python结合实现短期电力负荷预测的DAT300项目解析
- 市场营销教学专用查询装置设计方案
- 随身WiFi高通210 MS8909设备的Root引导文件破解攻略
- 实现服务器端级联:modella与leveldb适配器的应用
- Oracle Linux安装必备依赖包清单与步骤
- Shyer项目:寻找喜欢的聊天伙伴
- MEAN堆栈入门项目: postings-app
- 在线WPS办公功能全接触及应用示例
- 新型带储订盒订书机设计文档
- VB多媒体教学演示系统源代码及技术项目资源大全
