深度解析:SVM算法的理论与应用
需积分: 12 48 浏览量
更新于2024-07-18
收藏 2.18MB PDF 举报
支持向量机(SVM)是一种强大的机器学习算法,由Cortes和Vapnik在1995年提出,主要用于解决小样本、非线性和高维模式识别问题。它的核心理念基于统计学习理论,特别是VC维理论和结构风险最小化原则。VC维衡量了函数类的复杂性,一个高VC维意味着问题更复杂,而SVM通过寻找模型复杂度和学习能力之间的平衡,旨在提升模型的推广能力,也就是泛化性能。
Vapnik的贡献在于将统计机器学习提升到了一个新的层次,他强调统计机器学习能够提供精确的学习效果评估和预测样本需求,这与传统机器学习方法依赖经验技巧和结果差异显著。SVM的独特之处在于其对维度的不敏感性,即使面对高维数据(如文本分类),也能保持高效,这是通过引入核函数实现的,允许在原始特征空间中进行非线性映射。
结构风险最小化并非深奥概念,实际指的是在有限数据集上选择模型时,既要考虑模型对训练数据的拟合(误差),又要防止过拟合(过度复杂导致泛化能力下降)。SVM通过优化一个复杂的边界(支持向量),找到最优决策边界,这个边界尽可能远离训练数据点,从而最大化区分能力。
支持向量机是一种兼顾理论基础和实践效能的算法,它利用统计学习理论的优势,尤其是在处理复杂问题和高维数据时,展现了显著的性能。在实际应用中,SVM常用于图像分类、文本分类、生物信息学等领域,并且在数据挖掘和预测分析中占据重要地位。
2018/10/18 SVM-支持向量机算法概述 ---一篇非常深入浅出介绍SVM的文章 - U侠学子 - CSDN博客
https://blog.csdn.net/ljn113399/article/details/69220087?utm_source=blogxgwz1 4/16
但实际上对于这个目标,我们常常使用另一个完全等价的目标函数来代替,那就是:
(式1)
不难看出当||w||
2
达到最小时,||w||也达到最小,反之亦然(前提当然是||w||描述的是向量的长度,因而是非负的)。之所以采用这种形式,是因为后面
对目标函数作一系列变换,而式(1)的形式会使变换后的形式更为简洁(正如聪明的读者所料,添加的系数二分之一和平方,皆是为求导数所需)。
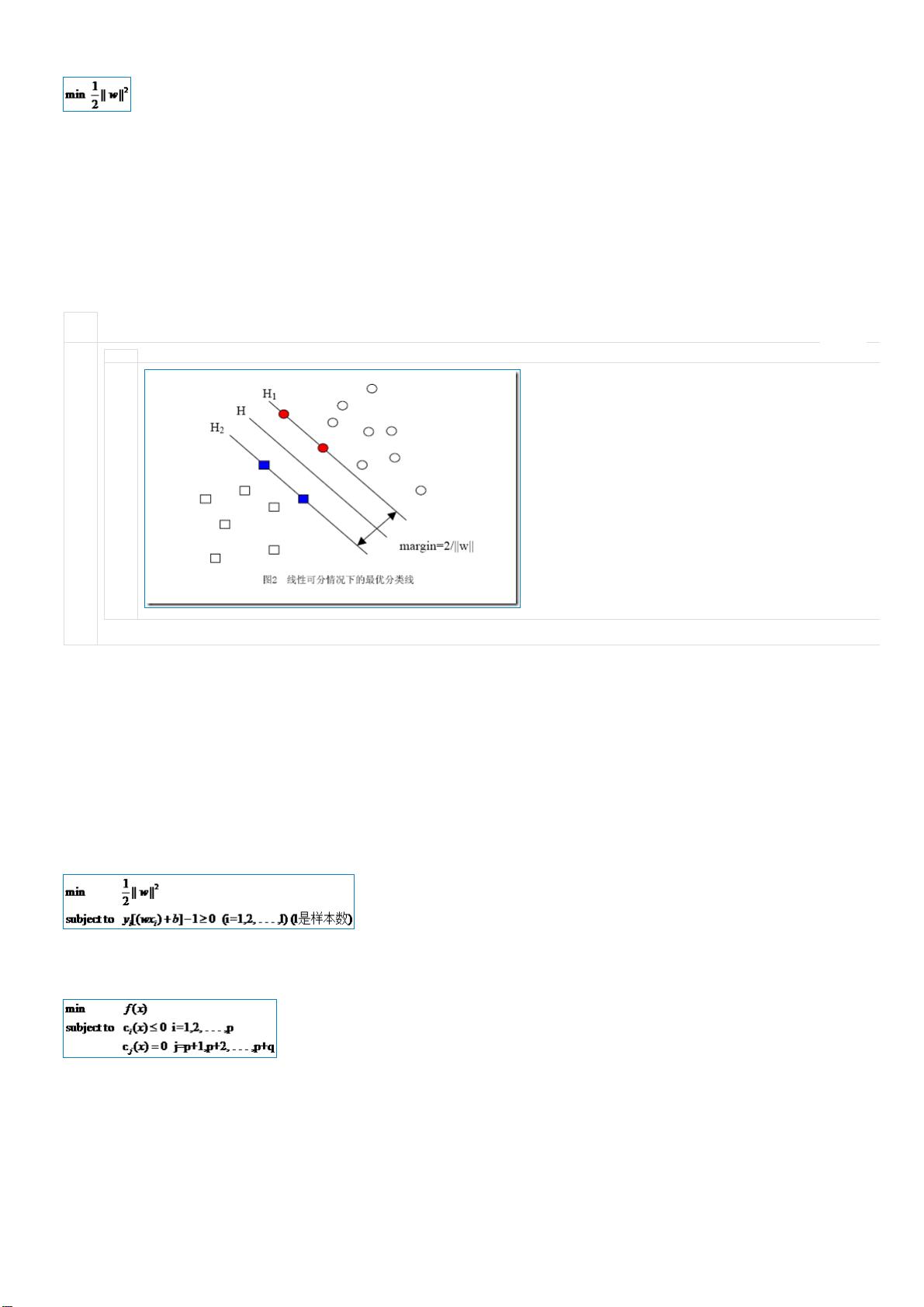
接下来我们自然会问的就是,这个式子是否就描述了我们的问题呢?(回想一下,我们的问题是有一堆点,可以被分成两类,我们要找出最好的分类面
如果直接来解这个求最小值问题,很容易看出当||w||=0的时候就得到了目标函数的最小值。但是你也会发现,无论你给什么样的数据,都是这个解!反
是H1与H2两条直线间的距离无限大,这个时候,所有的样本点(无论正样本还是负样本)都跑到了H1和H2中间,而我们原本的意图是,H1右侧的被分
左侧的被分为负类,位于两类中间的样本则拒绝分类(拒绝分类的另一种理解是分给哪一类都有道理,因而分给哪一类也都没有道理)。这下可好,所
入了无法分类的灰色地带。
造成这种结果的原因是在描述问题的时候只考虑了目标,而没有加入约束条件,约束条件就是在求解过程中必须满足的条件,体现在我们的问题中就是
H1或H2的某一侧(或者至少在H1和H2上),而不能跑到两者中间。我们前文提到过把间隔固定为1,这是指把所有样本点中间隔最小的那一点的间隔
是集合的间隔的定义,有点绕嘴),也就意味着集合中的其他点间隔都不会小于1,按照间隔的定义,满足这些条件就相当于让下面的式子总是成立:
y
i
[(w·x
i
)+b]≥1 (i=1,2,…,l) (l是总的样本数)
但我们常常习惯让式子的值和0比较,因而经常用变换过的形式:
y
i
[(w·x
i
)+b]-1≥0 (i=1,2,…,l) (l是总的样本数)
因此我们的两类分类问题也被我们转化成了它的数学形式,一个带约束的最小值的问题:
从最一般的定义上说,一个求最小值的问题就是一个优化问题(也叫寻优问题,更文绉绉的叫法是规划——Programming),它同样由两部分组成,目
束条件,可以用下面的式子表示:
(式1)
约束条件用函数c来表示,就是constrain的意思啦。你可以看出一共有p+q个约束条件,其中p个是不等式约束,q个等式约束。
关于这个式子可以这样来理解:式中的x是自变量,但不限定它的维数必须为1(视乎你解决的问题空间维数,对我们的文本分类来说,那可是成千上万
f(x)在哪一点上取得最小值(反倒不太关心这个最小值到底是多少,关键是哪一点),但不是在整个空间里找,而是在约束条件所划定的一个有限的空间
有限的空间就是优化理论里所说的可行域。注意可行域中的每一个点都要求满足所有p+q个条件,而不是满足其中一条或几条就可以(切记,要满足每
时可行域边界上的点有一个额外好的特性,它们可以使不等式约束取得等号!而边界内的点不行。
关于可行域还有个概念不得不提,那就是凸集,凸集是指有这么一个点的集合,其中任取两个点连一条直线,这条线上的点仍然在这个集合内部,因此
象的(一个反例是,二维平面上,一个月牙形的区域就不是凸集,你随便就可以找到两个点违反了刚才的规定)。
剩余15页未读,继续阅读
2024-09-08 上传
2022-09-20 上传
2024-02-20 上传
2012-01-05 上传
2015-07-15 上传

yh_sk
- 粉丝: 2
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Elasticsearch核心改进:实现Translog与索引线程分离
- 分享个人Vim与Git配置文件管理经验
- 文本动画新体验:textillate插件功能介绍
- Python图像处理库Pillow 2.5.2版本发布
- DeepClassifier:简化文本分类任务的深度学习库
- Java领域恩舒技术深度解析
- 渲染jquery-mentions的markdown-it-jquery-mention插件
- CompbuildREDUX:探索Minecraft的现实主义纹理包
- Nest框架的入门教程与部署指南
- Slack黑暗主题脚本教程:简易安装指南
- JavaScript开发进阶:探索develop-it-master项目
- SafeStbImageSharp:提升安全性与代码重构的图像处理库
- Python图像处理库Pillow 2.5.0版本发布
- mytest仓库功能测试与HTML实践
- MATLAB与Python对比分析——cw-09-jareod源代码探究
- KeyGenerator工具:自动化部署节点密钥生成
