大数据技术分享:HBase的基本原理与应用
141 浏览量
更新于2024-01-13
收藏 1.04MB PPTX 举报
本文将对大数据技术进行分享,主要涵盖数据存储、数据分析、实时计算、数据传输、数据采集以及大数据架构等方面的内容。
首先介绍了HBase是什么,它是Apache Hadoop中的一个子项目,并通过使用Hadoop的DFS工具来存储数据。HBase依赖于HDFS作为最基本的存储基础单元,并可以通过Map/Reduce的框架对HBase进行操作,具有HRegionServer、HRegion、Hmemcache、Hlog、HStore等组件。接下来解释了为什么采用HBase,它是一种适合于非结构化数据存储的数据库,以基于列存储的方式来读写大数据,查询速度非常快。
然后介绍了其他的数据存储技术,包括MongoDB和NoSQL数据库。MongoDB是一个面向文档的数据库,以文档的形式存储数据,具有高度灵活的模式设计。NoSQL是一种非关系型数据库,与传统的关系型数据库不同,它可以处理大量结构化和半结构化数据,并且具有高度可扩展性。
在数据分析方面,介绍了Hive、MapReduce和MR,其中Hive是基于Hadoop的数据仓库基础设施,它能够提供类似SQL的查询语言来查询存储在Hadoop中的数据。MapReduce是一种将大规模数据分解为小块并进行并行处理的计算框架,可以解决大规模数据处理的问题。
在实时计算方面,介绍了Storm和Spark。Storm是一个分布式实时计算系统,可以处理实时数据流,并进行流处理和分析。Spark是一个快速、通用的大数据处理引擎,支持流处理、批处理和机器学习等多种数据处理模式。
然后介绍了数据传输技术,包括Sqoop和Kafka。Sqoop是一个用于在Hadoop和关系型数据库之间传输数据的工具,可以实现数据的批量导入和导出。Kafka是一个分布式流处理平台,可以实现高吞吐量的发布/订阅模式。
最后介绍了数据采集技术,包括Flume和Kafka。Flume是一个分布式、可靠的和高可用的大数据采集系统,用于收集、聚合和移动大量的日志数据。Kafka是一个分布式流平台,用于收集和传输实时的数据流。
最后介绍了DPI大数据架构,它是一种集成了数据存储、数据分析、实时计算、数据传输和数据采集等多种技术的大数据架构。在架构中使用了HBase、MongoDB、Lucene/Solr等多种技术,以满足大规模数据处理的需求。
总结来说,本文分享了大数据技术的各个方面,包括数据存储、数据分析、实时计算、数据传输和数据采集等。这些技术可以帮助我们处理海量的数据,并对数据进行有效的存储、分析和处理,以满足大规模数据处理的需求。
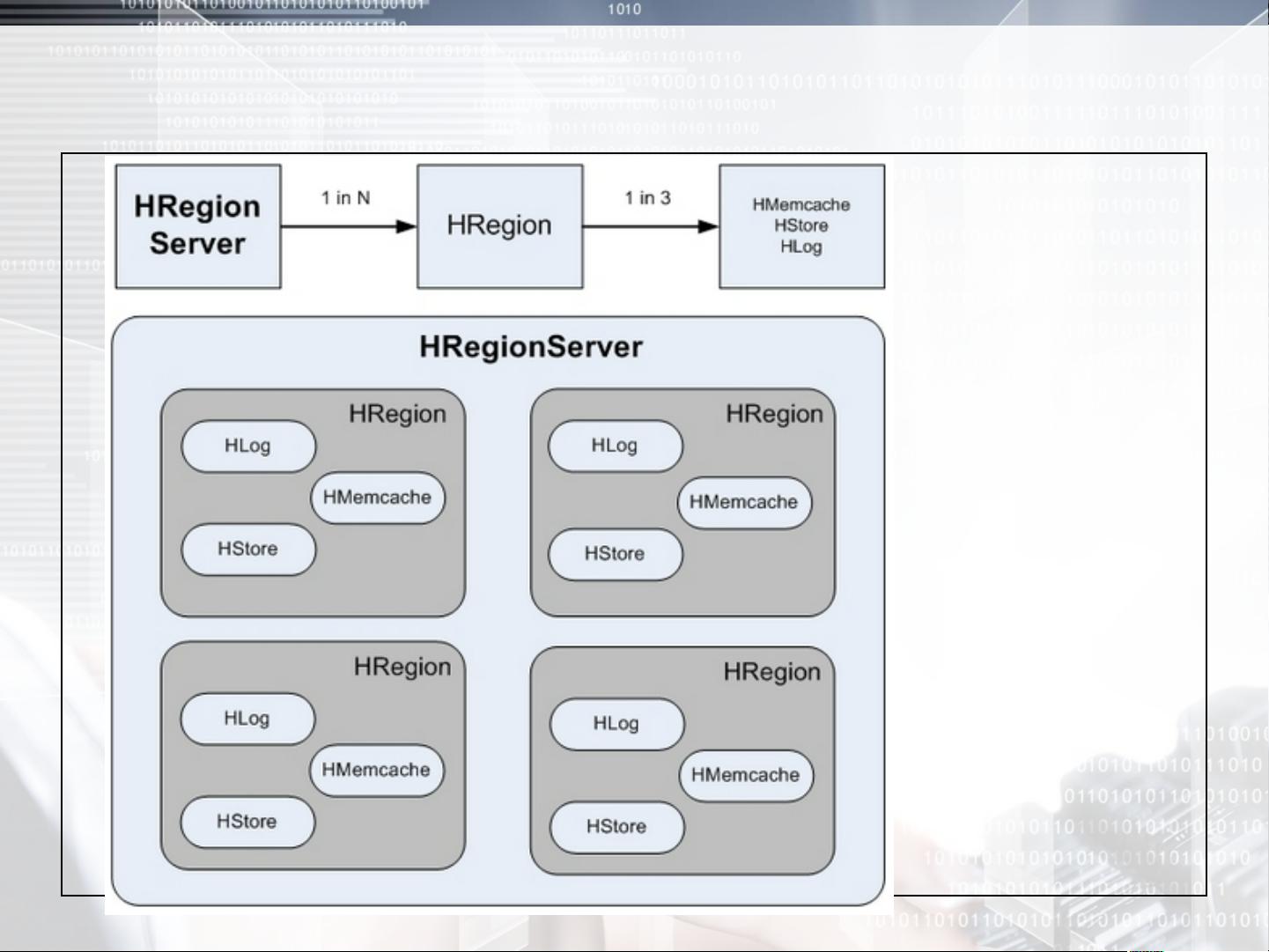
HRegionServer、HRegion、Hmemcache、Hlog、
HStore之间的关系
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-06-02 上传
2022-12-24 上传
2021-09-21 上传
2021-11-08 上传
2023-10-04 上传
2022-12-24 上传

猫一样的女子245
- 粉丝: 231
- 资源: 2万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 菜单前面带小图标的VC++特色菜单
- elixir-convert:十六进制<->十进制<->二进制的转换模块来学习elixir
- Zarbi-开源
- CoolMOS动力电池充电器-项目开发
- bannana:bannana存储库
- GMAP-开源
- VC++ 动态更改菜单
- JavaAdvanced:Java高级课程2018年5月@ SoftUni
- 计步器matlab代码-sensibility_testbed:感性_试验台
- Ling_567
- portfolio_projects
- ProgramowanieObiektowe
- 手机号码转换成ASCII码.zip昆仑通态触摸屏案例编程源码资料下载
- serialaio:尝试开发通用协议和传输以使用python3的新asyncio lib
- StackoverflowSearch
- building-frontend-web-applications:使用纯JavaScript的简单图书CRUD应用程序,用于学习
