关系数据库系统中Top-k查询处理技术的调查
需积分: 1 188 浏览量
更新于2024-07-29
收藏 1.93MB PDF 举报
"本文档是一份关于关系数据库系统中Top-k查询处理技术的调查报告,由Ihab F. Ilyas、George Besselaes和Mohamed A. Soliman撰写,来自滑铁卢大学。报告详细探讨了在处理大量数据的交互环境中,高效Top-k查询处理的重要性,特别是在Web、多媒体搜索和分布式系统中的应用。报告对当前的技术进行了描述和分类,并讨论了设计维度,包括查询模型、数据访问方法、实现层次、数据和查询的确定性以及支持的评分函数。此外,还涉及了XML领域的Top-k查询及其与关系方法的联系。"
在关系数据库系统中,Top-k查询处理技术是关键,它涉及到从海量数据中快速获取排名前k的结果。这些查询在诸如搜索引擎、推荐系统和在线分析处理等实时交互场景中扮演着重要角色。报告首先强调了高效处理Top-k查询对于性能提升的显著影响。
接着,报告详细阐述了不同的设计维度:
1. **查询模型**:不同的Top-k查询模型关注于如何表达和处理查询,例如基于排序的查询、基于窗口的查询或动态更新的查询。
2. **数据访问方法**:这包括索引结构的使用,如B树、R树、倒排索引等,以及如何利用这些索引来加速Top-k查询的执行。
3. **实现层次**:处理可以在查询处理器、存储管理系统或者应用层等多个层面进行,每种层次都有其优势和挑战。
4. **数据和查询的确定性**:不确定性可能来源于数据的不精确性或查询的动态性,处理这些不确定性需要特定的策略。
5. **评分函数**:不同的应用场景需要不同的评分标准,例如基于距离、相关性或其他复杂度量的函数。
报告还讨论了Top-k查询在XML数据环境中的应用,XML数据具有层次结构,处理起来更具挑战性。XML领域的Top-k查询通常需要考虑结构信息,而不仅仅是数值比较。
最后,报告提到了"rank-aware processing"(排名感知处理)、"rank aggregation"(排名聚合)和"voting"等额外的关键概念,这些都是优化Top-k查询性能的重要策略。
总结来说,这份报告为读者提供了一个全面的框架,理解并比较各种Top-k查询处理技术,对于数据库研究人员和系统开发者来说,是一份宝贵的参考资料。通过深入研究这些技术和方法,可以更好地设计和优化数据库系统,以满足现代大数据环境中的高性能查询需求。

11:10 I. F. Ilyas et al.
whenever p
i
≤ ´p
i
for every i. We elaborate on the impact of function monotonicity on
top-k processing in Section 6.1.
In more complex applications, a ranking function might need to be expressed as a
numeric expression to be optimized. In this setting, the monotonicity restriction of the
ranking function is relaxed to allow for more generic functions. Numerical optimization
tools as well as indexes are used to overcome the processing challenges imposed by such
ranking functions.
Another group of applications address ranking objects without specifying a ranking
function. In some environments, such as data exploration or decision making, it might
not be important to rank objects based on a specific ranking function. Instead, objects
with high quality based on different data attributes need to be reported for further
analysis. These objects could possibly be among the top-k objects of some unspecified
ranking function. The set of objects that are not dominated by any other objects, based
on some given attributes, are usually referred to as the skyline.
We classify top-k processing techniques based on the restrictions they impose on the
underlying ranking function as follows:
—Monotone ranking function. Most of the current top-k processing techniques assume
monotone ranking functions since they fit in many practical scenarios, and have
appealing properties allowing for efficient top-k processing. One example is Fagin
et al. [2001]. We discuss the properties of monotone ranking functions in Section 6.1.
—Generic ranking function. A few recent techniques, for example, Zhang et al. [2006],
address top-k queries in the context of constrained function optimization. The ranking
function in this case is allowed to take a generic form. We discuss the details of these
techniques in Section 6.2.
—No ranking function. Many techniques have been proposed to answer skyline-related
queries, for example, B
¨
orzs
¨
onyi et al. [2001] and Yuan et al. [2005]. Covering current
skyline literature in detail is beyond the scope of this survey. We believe it worth a
dedicated survey by itself. However, we briefly show the connection between skyline
and top-k queries in Section 6.3.
2.6. Impact of Design Dimensions on Top-k Processing Techniques
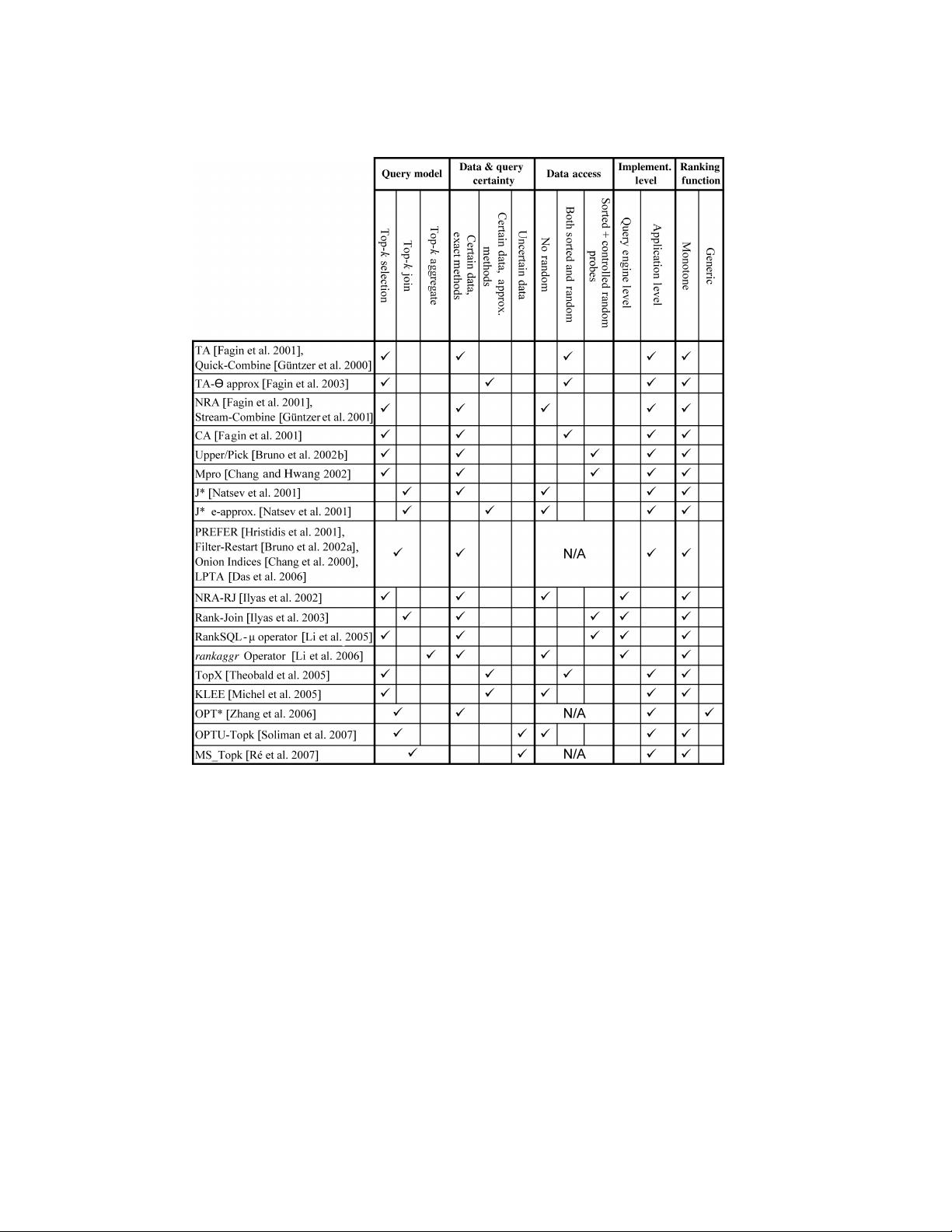
Figure 4 shows the properties of a sample of different top-k processing techniques that
we describe in this survey. The applicable categories under each taxonomy dimension
are marked for each technique. For example, TA [Fagin et al. 2001] is an exact method
that assumes top-k selection query model, and operates on certain data, exploiting
both sorted and random access methods. TA integrates with database systems at the
application level, and supports monotone ranking functions.
Our taxonomy encapsulates different perspectives to understand the processing re-
quirements of current top-k processing techniques. The taxonomy dimensions, dis-
cussed in the previous sections, can be viewed as design dimensions that impact the
capabilities and the assumptions of the underlying top-k algorithms. In the following,
we give some examples of the impact of each design dimension on the underlying top-k
processing techniques:
—Impact of query model. The query model significantly affects the solution space of the
top-k algorithms. For example, the top-k join query model (Definition 2.2) imposes
tight integration with the query engine and physical join operators to efficiently
navigate the Cartesian space of join results.
—Impact of data access. Available access methods affect how different algorithms com-
pute bounds on object scores and hence affect the termination condition. For example,
ACM Computing Surveys, Vol. 40, No. 4, Article 11, Publication date: October 2008.

剩余57页未读,继续阅读
2024-11-26 上传
2024-11-26 上传
2024-11-26 上传
2024-11-26 上传
2024-11-26 上传

billmaths
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB新功能:Multi-frame ViewRGB制作彩色图阴影
- XKCD Substitutions 3-crx插件:创新的网页文字替换工具
- Python实现8位等离子效果开源项目plasma.py解读
- 维护商店移动应用:基于PhoneGap的移动API应用
- Laravel-Admin的Redis Manager扩展使用教程
- Jekyll代理主题使用指南及文件结构解析
- cPanel中PHP多版本插件的安装与配置指南
- 深入探讨React和Typescript在Alias kopio游戏中的应用
- node.js OSC服务器实现:Gibber消息转换技术解析
- 体验最新升级版的mdbootstrap pro 6.1.0组件库
- 超市盘点过机系统实现与delphi应用
- Boogle: 探索 Python 编程的 Boggle 仿制品
- C++实现的Physics2D简易2D物理模拟
- 傅里叶级数在分数阶微分积分计算中的应用与实现
- Windows Phone与PhoneGap应用隔离存储文件访问方法
- iso8601-interval-recurrence:掌握ISO8601日期范围与重复间隔检查
