C语言函数调用栈详解:以IA32架构为例
86 浏览量
更新于2024-08-27
收藏 416KB PDF 举报
C语言函数调用栈详解
在编程中,C语言函数调用栈是程序执行过程中不可或缺的一部分。程序的执行流程可以视为一系列函数的调用和返回,这种切换过程依赖于一个被称为调用栈(call stack)的数据结构。调用栈是内存中的一块区域,负责管理函数调用的上下文信息,确保函数执行结束后能够正确地返回到先前的位置继续执行。
在函数调用过程中,编译器利用堆栈来管理以下关键信息:
1. **函数参数传递**:通过将参数压入堆栈,函数调用时需要将参数值依次存储在栈顶,然后在函数内部取出使用。这样可以保持原始变量状态的连续性,便于函数间的数据传递。
2. **返回地址**:函数调用时,编译器会在堆栈中保存返回指令的地址,以便函数执行完毕后能知道该返回何处。这通常是通过将当前指令指针EIP(Intel指令指针)压入栈中实现的。
3. **寄存器上下文保存**:处理器寄存器中的临时数据,如临时变量、函数局部变量等,需要被临时保存,以便函数执行完毕后能恢复这些寄存器的原始值,以便后续代码可以继续执行。
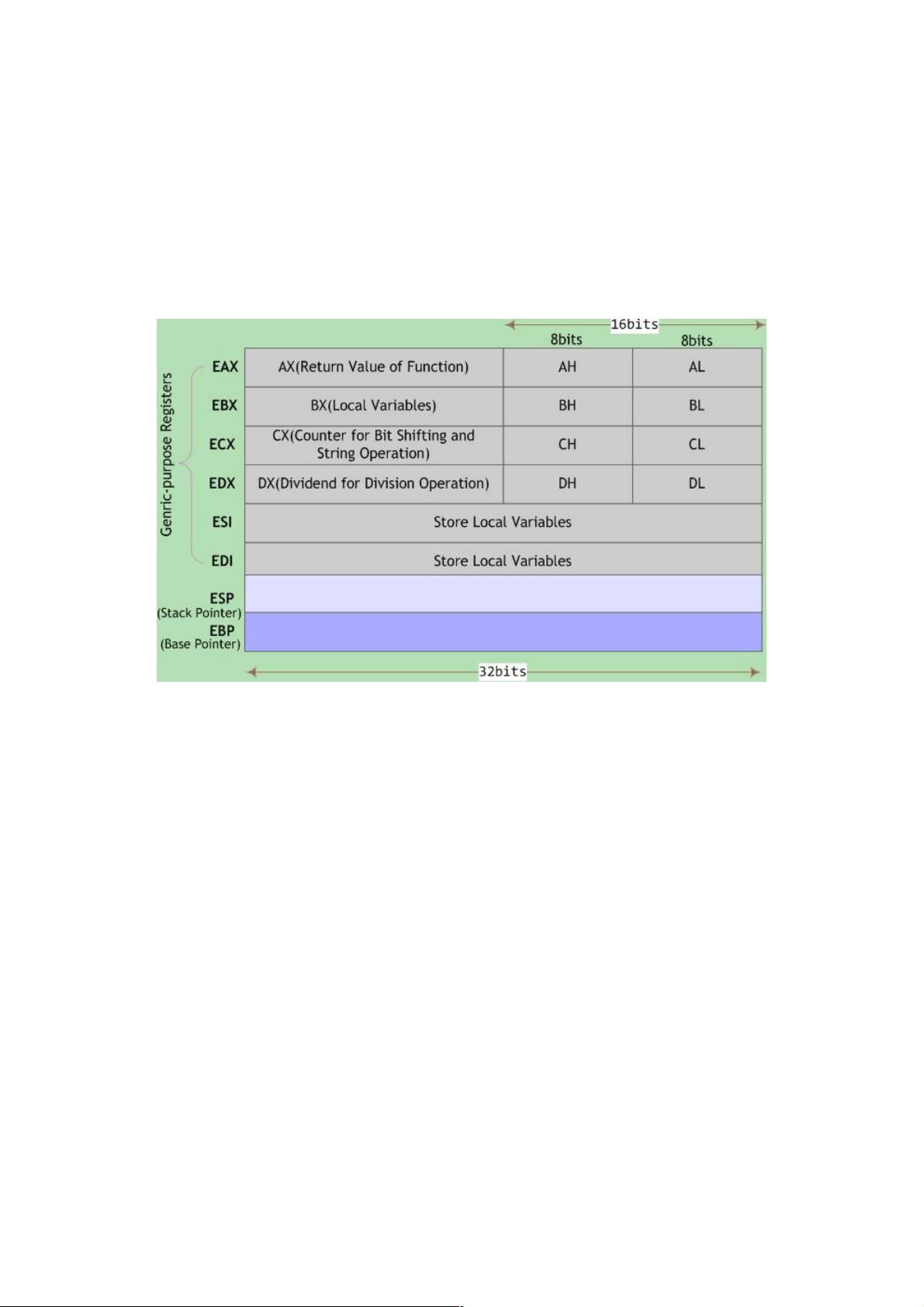
在Intel 32位体系结构(IA32)中,有8个基本的32位寄存器,包括eax、ebx、ecx、edx、edi、esi、ebp和esp。其中,eax、ebx、ecx和edx可以看作是两个独立的16位寄存器,而低16位还可以进一步拆分为两个8位寄存器。这些寄存器的使用由编译器根据操作数的大小和ABI(应用程序二进制接口)规范进行选择,以优化性能和保持兼容性。
堆栈的实现与处理器的堆栈指针ESP密切相关。ESP指示当前栈帧的顶部,每次函数调用时都会更新ESP以适应新的局部变量和返回地址。EIP则始终指向下一条待执行的指令地址,执行完后自动更新。
理解C语言函数调用栈的工作原理对于深入学习编程至关重要,因为正确的栈管理可以防止内存泄漏,提高代码效率,并有助于调试复杂程序中的错误。不同的处理器和编译器可能有不同的细节,但基本原理都是基于栈的高效管理,确保程序控制流的顺畅执行。
C语言函数调用栈语言函数调用栈(一一)
程序的执行过程可看作连续的函数调用。当一个函数执行完毕时,程序要回到调用指令的下一条指令(紧接call指令)处
继续执行。函数调用过程通常使用堆栈实现,每个用户态进程对应一个调用栈结构(call stack)。编译器使用堆栈传递函
数参数、保存返回地址、临时保存寄存器原有值(即函数调用的上下文)以备恢复以及存储本地局部变量。
不同处理器和编译器的堆栈布局、函数调用方法都可能不同,但堆栈的基本概念是一样的。
1 寄存器分配
寄存器是处理器加工数据或运行程序的重要载体,用于存放程序执行中用到的数据和指令。因此函数调用栈的实现与
处理器寄存器组密切相关。
Intel 32位体系结构(简称IA32)处理器包含8个四字节寄存器,如下图所示:
图1 IA32处理器寄存器
最初的8086中寄存器是16位,每个都有特殊用途,寄存器名城反映其不同用途。由于IA32平台采用平面寻址模式,对
特殊寄存器的需求大大降低,但由于历史原因,这些寄存器名称被保留下来。在大多数情况下,上图所示的前6个寄存
器均可作为通用寄存器使用。某些指令可能以固定的寄存器作为源寄存器或目的寄存器,如一些特殊的算术操作指令
imull/mull/cltd/idivl/divl要求一个参数必须在%eax中,其运算结果存放在%edx(higher 32-bit)和%eax (lower32-bit)中;
又如函数返回值通常保存在%eax中,等等。为避免兼容性问题,ABI规范对这组通用寄存器的具体作用加以定义(如图
中所示)。
对于寄存器%eax、%ebx、%ecx和%edx,各自可作为两个独立的16位寄存器使用,而低16位寄存器还可继续分为两
个独立的8位寄存器使用。编译器会根据操作数大小选择合适的寄存器来生成汇编代码。在汇编语言层面,这组通用寄
存器以%e(AT&T语法)或直接以e(Intel语法)开头来引用,例如mov $5, %eax或mov eax, 5表示将立即数5赋值给寄存
器%eax。
在x86处理器中,EIP(Instruction Pointer)是指令寄存器,指向处理器下条等待执行的指令地址(代码段内的偏移量),每
次执行完相应汇编指令EIP值就会增加。ESP(Stack Pointer)是堆栈指针寄存器,存放执行函数对应栈帧的栈顶地址(也
是系统栈的顶部),且始终指向栈顶;EBP(Base Pointer)是栈帧基址指针寄存器,存放执行函数对应栈帧的栈底地址,
用于C运行库访问栈中的局部变量和参数。
注意,EIP是个特殊寄存器,不能像访问通用寄存器那样访问它,即找不到可用来寻址EIP并对其进行读写的操作码
(OpCode)。EIP可被jmp、call和ret等指令隐含地改变(事实上它一直都在改变)。
不同架构的CPU,寄存器名称被添加不同前缀以指示寄存器的大小。例如x86架构用字母“e(extended)”作名称前缀,指
示寄存器大小为32位;x86_64架构用字母“r”作名称前缀,指示各寄存器大小为64位。
编译器在将C程序编译成汇编程序时,应遵循ABI所规定的寄存器功能定义。同样地,编写汇编程序时也应遵循,否则
所编写的汇编程序可能无法与C程序协同工作。
【扩展阅读】栈帧指针寄存器
为了访问函数局部变量,必须能定位每个变量。局部变量相对于堆栈指针ESP的位置在进入函数时就已确定,理论上
变量可用ESP加偏移量来引用,但ESP会在函数执行期随变量的压栈和出栈而变动。尽管某些情况下编译器能跟踪栈
中的变量操作以修正偏移量,但要引入可观的管理开销。而且在有些机器上(如Intel处理器),用ESP加偏移量来访问一
下载后可阅读完整内容,剩余7页未读,立即下载
350 浏览量
187 浏览量
1060 浏览量
350 浏览量
855 浏览量
110 浏览量
154 浏览量

weixin_38675969
- 粉丝: 2
- 资源: 957
 我的内容管理
展开
我的内容管理
展开







最新资源
- STM32通过按键改变PWM占空比产生呼吸灯效果
- react-django-docker
- A_Simple_Game_of_Fetch_Build:和狗一起玩取回游戏,并反思您作为老人的生活
- 九丁百度图片下载搜索工具 v1.0
- Catfish(鲶鱼) Blog v2.0.75
- AMwebsite:网站开发
- 静态网页 html/css 练习素材
- Hydra3D-开源
- ML_proj01
- 世界之窗浏览器(TheWorld) v3.6.1.0
- 无后顾之忧:React的状态管理库
- Library-Python-SQLAlchemy-Flask:使用python flask将库数据保存到sqlite.db
- 仿webqq的webos框架zos,基于hoorayos2.0移植的纯html+js版本,后端语言.net
- fw —工作区生产力的助推器-Rust开发
- my_xUltimate-d9pc-x86
- 行业文档-设计装置-除琐屑的建筑用钢筋切割装置.zip
