NYU机器学习讲义:回归与过拟合
需积分: 10 112 浏览量
更新于2024-07-17
1
收藏 1.14MB PDF 举报
"NYU机器学习第二讲课件,涵盖了 Regression、Empirical Risk Minimization、Least Squares、Higher Order Polynomials、Under-fitting/Over-fitting、Cross-Validation等主题,由Columbia University的Tony Jebara教授讲解。"
这篇课件主要讨论了机器学习中的几个关键概念,特别是针对回归分析的深入探讨。首先,我们来看看Regression(回归)的概念。回归是一种预测模型,它试图找到一个函数f(x),这个函数可以根据输入变量x来预测输出变量y。在房地产的例子中,我们可以使用回归来预测房价(y),输入变量可能包括房屋的房间数量(#rooms)、纬度(latitude)和经度(longitude)等。
接着,课件提到了Empirical Risk Minimization(经验风险最小化)。这是机器学习中的一种策略,它通过最小化训练数据集上的损失函数来选择模型。目标是找到一个函数f(x)使得在所有训练样本上的预测误差最小。
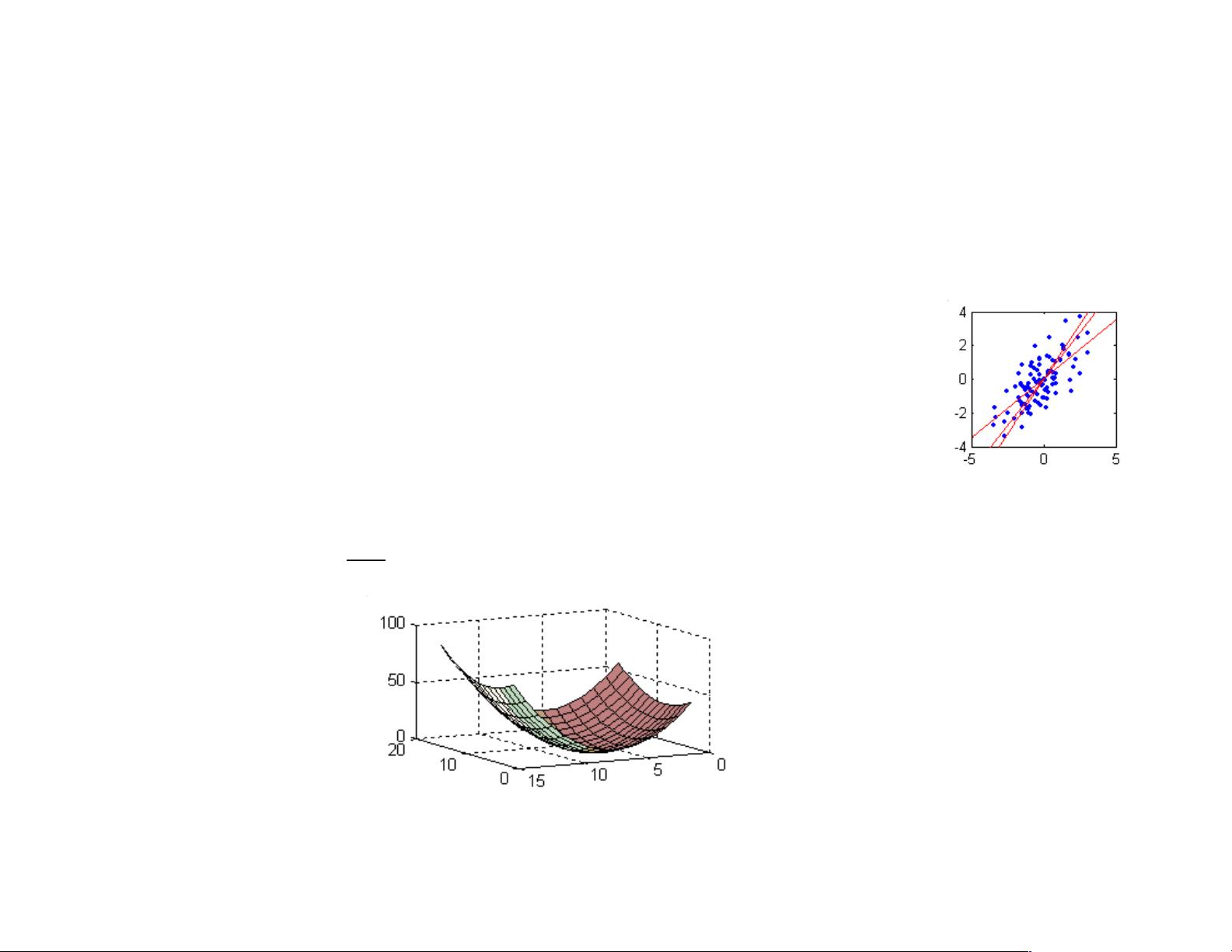
Least Squares(最小二乘法)是回归分析中常用的一种方法,尤其在简单线性回归中。它通过最小化预测值与实际值之间的平方误差和来确定最佳拟合线。
Higher Order Polynomials(高阶多项式)被用来处理非线性关系。当简单的线性模型无法捕捉数据中的复杂模式时,可以使用更复杂的多项式函数来提高预测准确性。
然而,过度复杂化的模型可能导致Under-fitting(欠拟合)或Over-fitting(过拟合)问题。欠拟合是指模型过于简单,无法捕捉数据的内在规律,而过拟合则是模型过于复杂,对训练数据过度拟合,导致在新数据上的泛化能力下降。
为了缓解过拟合,Cross-Validation(交叉验证)是一种有效的技术。它将数据集分为多个子集,然后多次训练和测试模型,以评估其在不同数据子集上的表现,从而得到更可靠的模型性能估计。
课件还简要提到了机器学习的分类,区分了Supervised Learning(监督学习)和Unsupervised Learning(无监督学习)。监督学习中,我们有带标签的数据(即输入和对应输出),如回归问题;而无监督学习则是在没有标签的情况下寻找数据的结构或模式,如聚类和密度估计。
NYU的这节机器学习课件深入浅出地介绍了回归分析的关键概念,包括经验风险最小化、最小二乘法、高阶多项式、欠拟合/过拟合以及交叉验证等,这些都是构建和评估预测模型时不可或缺的基础知识。
Tony Jebara, Columbia University
Linear Function Classes
• Linear is simplest class of functions to search over:
• Start with x being 1-dimensional (D=1):
• Plug in the above & minimize empirical risk over θ"
• Note: minimum occurs when R(θ) gets flat (not always!)
• Note: when R(θ) is flat, gradient
f x; θ
( )
= θ
T
x + θ
0
= θ
d
x d
( )
d =1
D
∑
+ θ
0
f x; θ
( )
= θ
1
x + θ
0
R θ
( )
=
1
2N
y
i
− θ
1
x
i
− θ
0
( )
i=1
N
∑
2
∇
θ
R = 0
剩余28页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2014-03-03 上传
2022-07-14 上传
2021-02-20 上传
2022-09-23 上传
2021-03-11 上传
2021-05-27 上传

weixin_38889715
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
