HBase入门:大数据时代的OLTP解决方案
需积分: 50 170 浏览量
更新于2024-07-19
收藏 10MB DOCX 举报
"Hbase个人总结文档,主要讲述Hbase的基础知识,包括其在大数据处理中的作用,与Hive和Oracle的对比,以及行存储和列存储的差异"
HBase是一种分布式、面向列的NoSQL数据库,它在Hadoop生态系统中扮演着关键角色,尤其适合处理海量数据的在线事务处理(OLTP)任务。与传统的SQL数据库,如Hive和Oracle,相比,HBase在大数据场景下提供了更好的性能和可扩展性。
在大数据分析领域,Hive通常用于离线的数据仓库分析,支持复杂的SQL查询,但不支持事务和实时查询。当需要进行记录级别的更新、删除等操作时,Hive就显得力不从心。相比之下,Oracle作为关系型数据库,虽然在小规模数据下表现良好,但面对亿级别以上的数据,其性能会显著下降。
HBase应运而生,它设计的目标是处理大规模数据并提供快速的随机读写能力。HBase采用了列存储的方式,这与传统的关系型数据库的行存储模式不同。在列存储中,数据按列族和列进行组织,这样在查询时,只需要读取所需列的数据,提高了查询效率,尤其适合于需要频繁查询特定列的情况。列式存储还有利于压缩和并行处理,进一步优化了大数据环境下的性能。
HBase的体系架构基于Hadoop,利用HDFS(Hadoop Distributed File System)进行数据存储,通过Zookeeper进行协调和管理。它的设计原则包括强一致性、水平扩展性和高可用性。每个表在HBase中被划分为多个Region,Region分布在集群的不同节点上,随着数据增长,Region可以自动分裂,从而实现负载均衡和扩展性。
操作HBase时,用户通常使用Java API或者命令行工具。数据的增删改查操作可以通过Put、Get、Delete和Scan等方法实现。此外,HBase还支持Secondary Index和 Coprocessors等高级特性,以满足不同场景的需求。
HBase是大数据环境下处理OLTP操作的理想选择,尤其是在需要高效读写和查询特定列的场景下。它与Hive和Oracle等传统数据库互补,共同构建了大数据处理的完整解决方案。理解HBase的工作原理和优势,对于在大数据项目中正确选用合适的技术栈至关重要。

为什么要把表拆分成多个 A? 答:因为单机的存储容量有限。
hbase 的储存模式-数据坐标,行,列
对比关系型数据库(使用的二维储存,先是行,后是列, 使用四维坐标系统:W行健XW列族XW列限定符XW时间戳X
逻辑模型中,时间版本也是数据坐标之一
可以看做键值W/*X数据库:四个坐标2,单元数据2/*,单元维度越少,对应值得范围越广
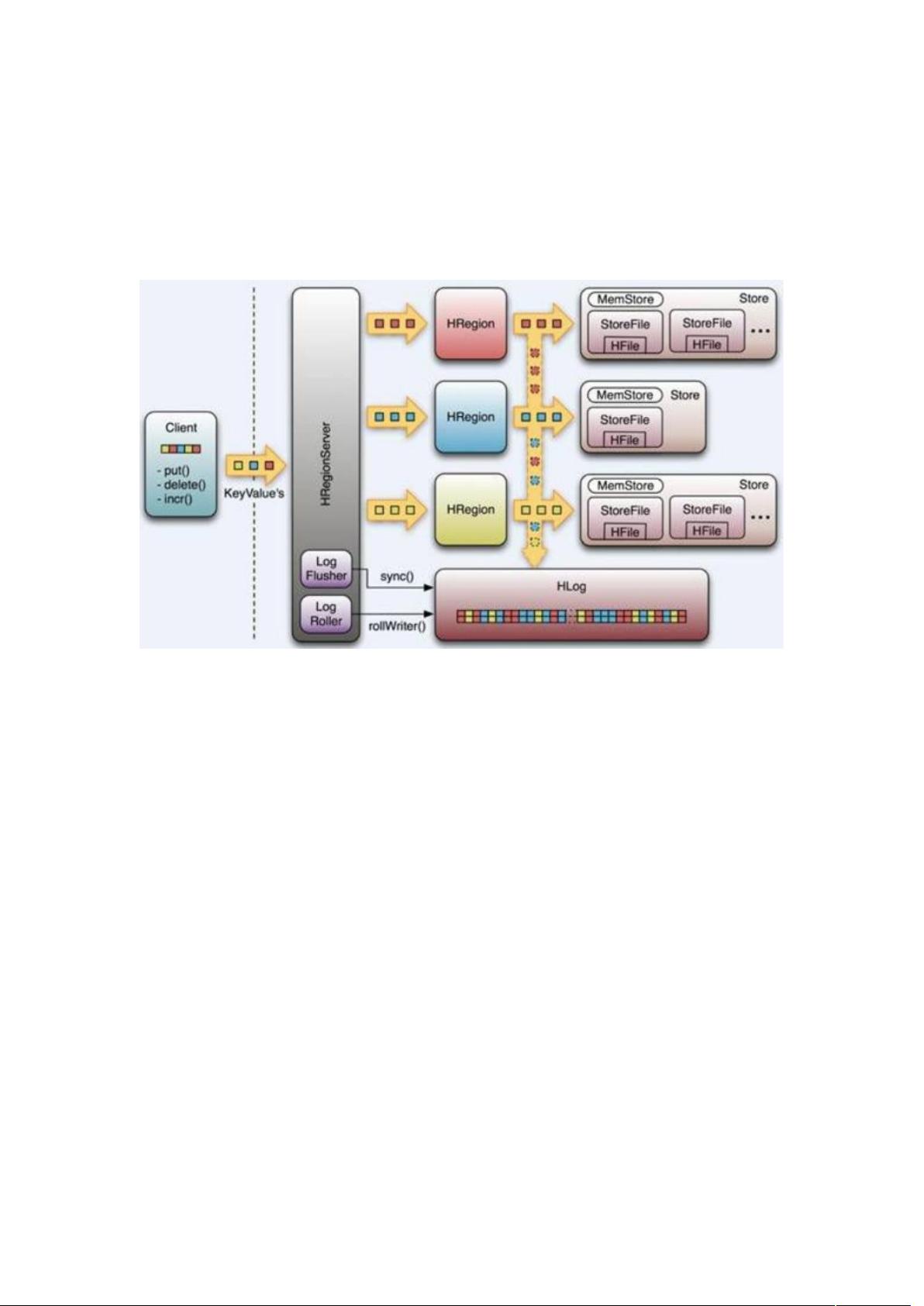
Hbase 的体系-系统架构
HMaster
! 没有单点问题, 中可以启动多个 !,通过 +, 的 !1 机制保证总有一个
! 运行,! 在功能上主要负责 和 A 的管理工作
管理用户对 的增、删、改、查操作
管理 A 的负载均衡,调整 A 分布
在 A 后,负责新 A 的分配
在 A 停机后,负责失效 A上的 A 迁移
剩余49页未读,继续阅读
2019-07-26 上传
2021-05-09 上传
2019-04-23 上传
2012-12-02 上传
2021-08-11 上传

wyq0827
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- SudokuSolver:简单的数独求解器
- vim-css-color:在编辑时在源代码中预览颜色-css source code
- Bibliotheque
- OpenSpecy:分析,处理,识别和共享拉曼光谱和(FT)IR光谱
- 钢琴基础教程,最经典钢琴入门教程.rar
- MathUI2014:MathUI2014 - Mozilla MathML 项目
- Draw-flowchart-with-drag-and-drop-in-HTML-and-[removed]这就是如何通过拖放操作使用html和javascript绘制流程图的全部内容。您可以使用HTML和JavaScript只需通过拖放即可绘制流程图。这仅用于学习目的
- 考试类精品--基于cassie-mujoco-sim,参考gym-cassie改的一个cassie行走仿真测试例子.zip
- le1e:code.le1e.com乐一易为Code提供简要信息服务,提供当前IP信息,网站的首页源码信息,持续提供简单的Web展示页面
- imteger,c语言ftp客户端源码,c语言
- spotiView:用于查看当前播放歌曲的应用程序在Spotify上有效
- 品牌运动鞋电商专题网站模板
- sunset:根据一天中的时间更改您的Atom UI和语法主题!
- Cat-Facts-Website-Source:#Cat-Facts-Website-Source www.barker.spacecatfacts网站JavaScript和PHP源代码。 处理用于选择事实,关闭音频和其他网站功能的控件-Source website php
- Terraform-In-Azure-Workshop:这是Azure Bootcamp中Terraform的所有代码和说明信息
- 数据结构课程设计源代码,匿名飞控c语言源码讲解,c语言
