C语言源代码词法分析:识别与类型判断
需积分: 14 110 浏览量
更新于2024-09-12
收藏 237KB DOCX 举报
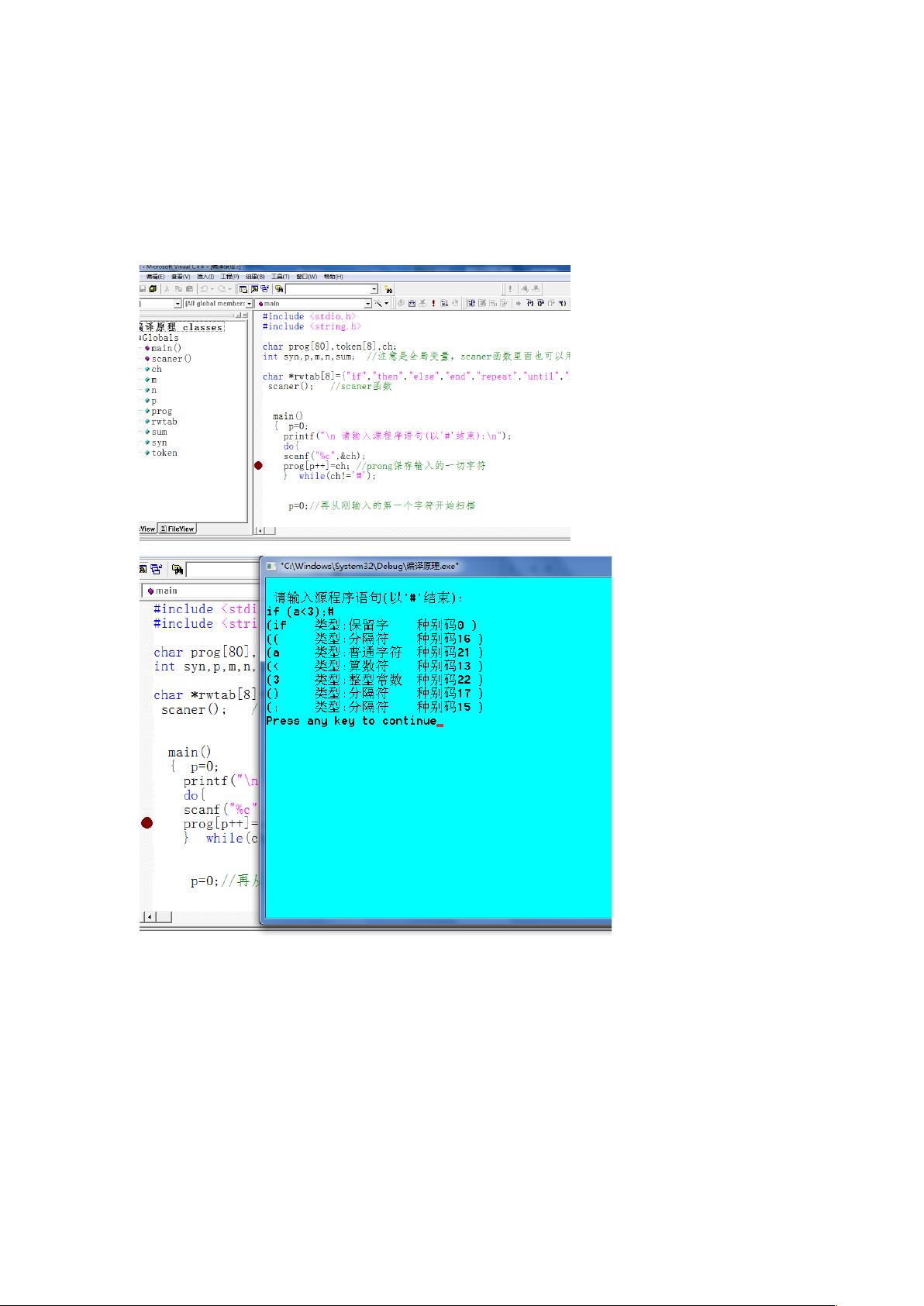
本文档主要探讨了编译原理中的词法分析在C语言源代码中的应用。词法分析是编译器工作流程的第一步,它将输入的源代码分解成一系列有意义的符号,即词汇单元(tokens),这些单元通常包括关键字、标识符、运算符、常量等。在这个C语言源代码示例中,作者实现了一个简单的词法分析器,通过`scaner()`函数逐个字符处理输入的源程序,将其转换成相应的种别码。
首先,我们看到全局变量`charprog[]`用于存储输入的源程序字符串,`token[]`作为临时缓存存储识别出的token,以及一些计数器变量如`syn`, `p`, `m`, 和 `n`。`rwtab[]`数组定义了识别的保留字,如"if", "then", "else"等。
`scaner()`函数是核心部分,其流程如下:
1. 读取用户输入的源程序,直到遇到结束标志'#',并将其保存在`prog[]`中。
2. 当遇到非空字符时,调用`scaner()`进行词法分析。分析过程分为多个条件分支:
- 如果遇到整型常数,`syn`的值为22,输出类型和种别码。
- 对于普通字符,`syn`值为21,输出字符类型和种别码。
- 如果`syn`表示保留字,输出相应的保留字及其种别码。
- 对于算术符和分隔符,根据`syn`的范围输出对应的类型和种别码。
- 如果`syn`为-1,表示输入的源程序语句错误,提示用户并退出程序。
特别地,`scaner()`函数会跳过空格和换行符,确保只处理有意义的字符。
通过这个简单的词法分析器,我们可以看到C语言源代码是如何被分解成可识别的元素,并根据预定义的规则进行分类。这为后续的语法分析阶段(如解析器)提供了基础,因为在编译过程中,词法分析器的结果会被递交给解析器来构建抽象语法树,从而形成更高级别的结构,最终生成目标代码。整个过程是编译器设计中的重要组成部分,对于理解和实现高效的编译器至关重要。
词法分析器,,后面有 C 语言源代码
截图:
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2010-07-21 上传
2011-05-17 上传
2009-06-16 上传
2009-04-10 上传
2012-11-07 上传
2010-04-20 上传

weiyidemiao
- 粉丝: 1
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- GreWordApp:将提供用于练习的高频 GRE 单词列表的应用程序
- jdk-8u171-linux-x64.tar
- 第3节(2) 设计概念.zip-综合文档
- Oracle11gR2 (p10404530_112030_Linux-x86-64_3of7.zip)
- 0311、基于MSP430和nRF905的多点无线通讯模块.rar
- WatchFolder
- DrupalMobileAdmin-开源
- 通过SD卡升级程序实验(裸机版).rar
- matlab归零码功率谱源码-ese524:ese524
- c代码-输入5名学生的分数,并显示出他们的总分和平均分。
- Bird-Species-Classification-Streamlit:通过使用stramlit部署的Web界面对20种物种进行分类的Python应用程序
- BlackLeopardEngine-开源
- 名称生成器
- 通过U盘更新程序实验(裸机版).rar
- Hackbot1.0:一个学习用户活动并在学习后自动重复活动的Android应用
- 工程材料手册(非金属卷)软件版V1.zip
