深度学习驱动的NLP语义压缩与应用解析
需积分: 24 32 浏览量
更新于2024-07-15
收藏 1.09MB DOC 举报
语义压缩算法.doc
在这个文档中,主要探讨的是自然语言处理领域中的一种关键技术——语义压缩,以及其在深度学习背景下的重要性。随着大数据和人工智能的发展,自然语言处理(NLP)成为关键领域,特别是在海量数据处理中,语义相似度计算扮演了核心角色。深度学习的兴起极大地推动了NLP语义相似度计算的进步,使得许多基于神经网络的算法得以显著提升任务表现。
首先,语义相似度计算在NLP中的应用广泛,例如对话机器人、情感分析、搜索引擎优化、推荐系统和机器翻译等领域,都依赖于准确的语义理解和匹配。通过比较文本间的语义相似性,可以提高交互的自然度、搜索结果的相关性以及个性化推荐的准确性。
传统的计算模型,如TF-IDF(词频-逆文档频率),是基于统计学的方法。TF-IDF通过计算词语在文档中的出现频率(TF)和在整个语料库中的相对稀有度(IDF)来评估词语的重要性。TF考虑词语的频繁程度,而IDF则衡量词语的通用性,两者结合后,可以有效过滤掉常用词并强调那些在特定上下文中具有重要意义的词语。这种方法简单且直观,但可能无法捕捉到词语之间的复杂语义关系。
相比之下,基于神经网络的计算模型如DSSM(Deep Structured Semantic Model)则更深入地利用了深度学习的优势,如词嵌入(Word Embeddings)、卷积神经网络(CNN)和循环神经网络(RNN)。这些模型能够捕捉到词语之间的潜在语义联系,从而提高语义相似度计算的精度。通过多层次的特征提取和学习,神经网络模型能够更好地理解文本的深层含义,为NLP任务提供了强大的工具。
总结来说,语义压缩算法是NLP领域的一个重要分支,它结合了自然语言处理技术、相似度匹配和深度学习的优势。传统方法与现代神经网络技术相辅相成,共同推动了NLP在实际应用中的效率和效果提升。随着研究的深入,未来的语义压缩算法可能会更加智能,能够更好地理解和处理自然语言的复杂性和多样性。
权值,其中 fi 代表了单词在文档 D 中的词频,k1 和 K 是经验参数。第三个组成部分是查
询词自身的权值,其中 qfi 代表查询词在用户查询中的词频,如果查询较短小的话,这个
值往往是 1,k2 是经验参数在第二个计算因子中,K 因子代表了对文档长度的考虑,它用
来利用文档长度归一化 tf 因子。 公式(7)所示 K 的计算公式中 ,dl 代 表 文 档 D 的 长
度 , 而 avdl 则 代 表 文 档 集 合 中所有文档的平均长度,k1 和 b 是经验参数。 其中参数
b 是调节因子,极端情况下,将 b 设定为 0,则文档长度因素将不起作用,经验表明一般将
b 设定为 0.75 会获得较好的搜索效果。ÿ
(公式 7)
BM25 公式中包含 3 个
自 由 调 节 参 数 , 除 了
调节因子 b 外 ,还有针对词频的调节因子 k1 和 k2。 k1 的作用是对查询词在文档中的词频
进行调节,如果将 k1 设定为 0,则第二部分计算因子成了整数 1,即不考虑词频的因素,
退化成了二元独立模型。 如果将 k1 设定为较大值, 则第二部分计算因子基本和词频 fi 保
持线性增长,即放大了词频的权值,根据经验,一般将 k1 设定为 1.2。调节因子 k2 和 k1
的作用类似,不同点在于其是针对查询词中的词频进行调节,一般将这个值设定在 0 到
1000 较大的范围内。之所以如此,是因为查询往往很短,所以不同查询词的词频都很小,
词频之间差异不大,较大的调节参数数值设定范围允许对这种差异进行放大。
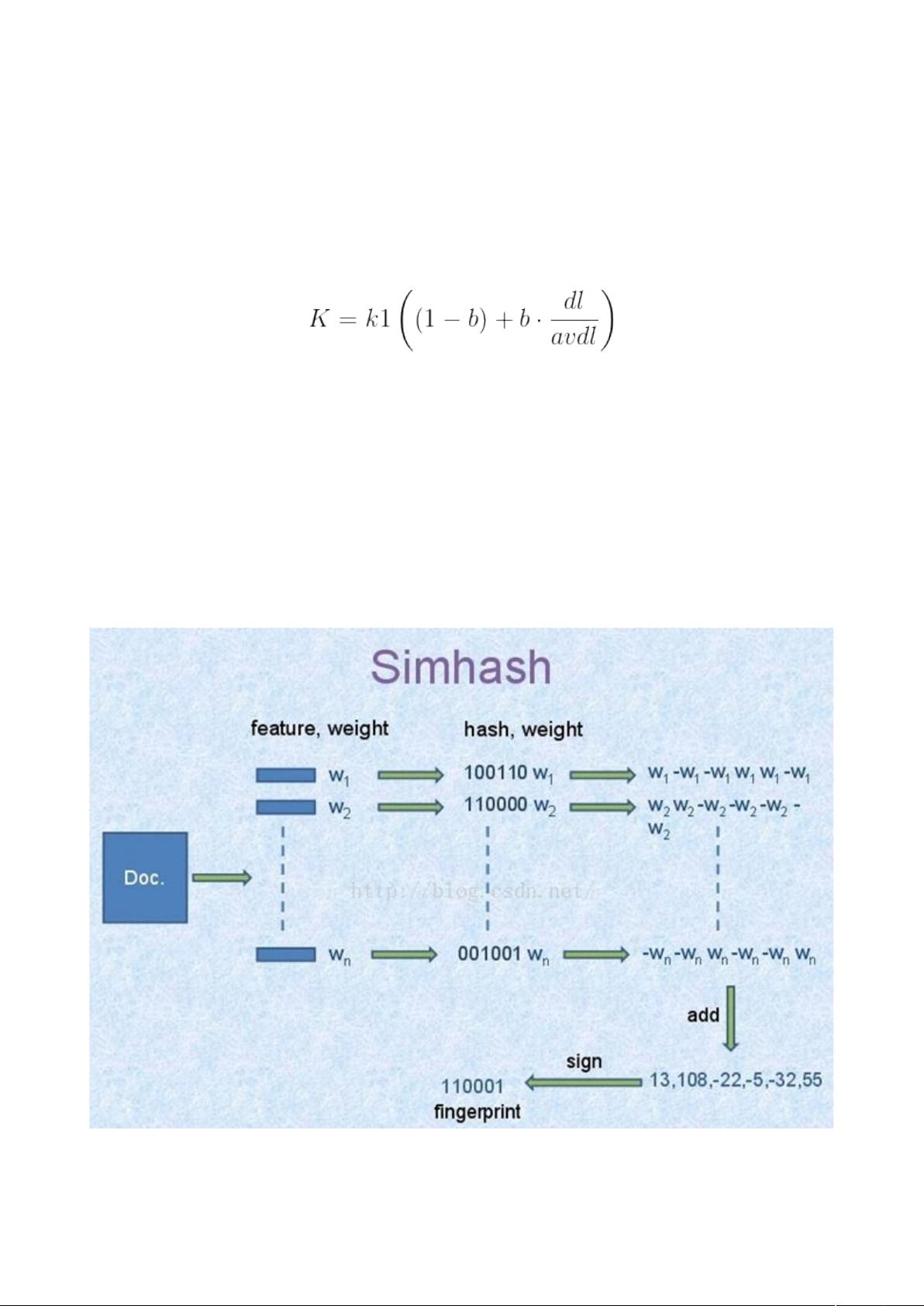
(3)simhash:【3】ÿ
先贴一张 google 出品的图片:
剩余17页未读,继续阅读
2021-03-19 上传
2022-07-13 上传
2022-06-12 上传
2021-07-02 上传
2021-01-30 上传
2022-06-27 上传
2021-12-24 上传
2024-05-29 上传
2021-09-20 上传

zty310315
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
